Алгоритмы машинного обучения: основные методы и способы ML
Искусственный интеллект побеждает гроссмейстеров в шахматы, определяет болезни по снимкам и подсказывает, какой сериал посмотреть дальше. Все это работает благодаря Machine Learning. В этой статье разбираемся в алгоритмах машинного обучения — что это такое, чем они отличаются друг от друга, как устроены и где применяются.
Содержание

Определение
Представьте, что вы владеете кофейней и каждый день записываете, сколько кофе покупают посетители. Через месяц накапливается таблица: день недели, погода, количество проданных чашек. Возникает вопрос: можно ли по этим данным предсказать, сколько заказов будет завтра? Или понять, в какие дни стоит готовить больше латте, а когда — эспрессо?
ML помогает находить закономерности в массивах информации и использовать их для предсказаний или принятия решений.
Алгоритмы машинного обучения — это наборы правил и методов, которые позволяют компьютеру учиться на примерах, а не просто выполнять заранее заданные инструкции. Как ребенок, который понимает, если небо серое — скоро пойдет дождь, так и компьютер с помощью определенных методик учится на примерах и начинает угадывать результат.
Подобные механизмы обучения лежат в основе голосовых помощников, систем распознавания лиц, фильтрации спама, медицинских прогнозов и многих других технологий, которые мы используем каждый день.
Если вам интересно, как все это работает на практике, приходите на курс «Инженер машинного обучения». Здесь вы шаг за шагом погрузитесь в интересную область с нуля: от основ Python до построения нейросетей, статистики и A/B-тестов. Чтобы начать, достаточно школьной математики и базовых навыков работы с числами и функциями.
ML- методы
Компьютеры, как и люди, могут учиться по-разному. Бывает, рядом есть учитель, который показывает, как правильно. А бывает, что приходится разбираться самому или учиться на собственных ошибках. Эти подходы заложили три основных метода обучения моделей.
Контролируемое обучение
Допустим, вы хотите научить компьютер предсказывать цену квартиры. У вас есть таблица, куда внесены площадь, этаж, количество комнат и реальная цена каждого объекта недвижимости. Мы учим модель на этих примерах, и потом она сможет предугадывать цену для новых квартир.
Так работает контролируемое обучение: вы показываете алгоритму данные с уже известными ответами, а он учится на этих примерах, чтобы потом делать прогнозы или классифицировать новые параметры.
Примеры задач:
- предсказать стоимость жилья;
- определить, спам или нет;
- спрогнозировать отток клиентов.
Неконтролируемое обучение
А теперь представим, что у вас есть список всех посетителей интернет-магазина, но вы не знаете, кто из них какие покупки делает. Просто есть возраст, активность, количество визитов. Можно ли выделить какие-то группы, например, «любители техники» и «покупатели детских товаров»?
Неконтролируемое обучение используется в тех случаях, когда у нас нет готовых ответов. Алгоритм сам ищет скрытые структуры в данных: группы, паттерны, связи.
Примеры задач:
- сгруппировать клиентов по поведению;
- найти аномалии (например, подозрительные транзакции);
- сжать файл.
Обучение с подкреплением
Если вы учите робота играть в шахматы, то не объясняете ему правила пошагово. Вы просто даете сигнал «молодец» или «ошибся» после каждого хода. Со временем он начинает понимать, какие действия приводят к успеху, а какие — нет.

Это и есть обучение с подкреплением. Алгоритм учится на основе вознаграждений или штрафов, которые он получает за действия в определенной среде. Такой способ часто используется, когда нужно выработать стратегию поведения: не просто распознать информацию, а действовать по ситуации.
Примеры задач:
- сыграть в шахматы, Go или компьютерные игры;
- управлять роботом;
- оптимизировать показы рекламы в реальном времени.
Основные алгоритмы машинного обучения
Под разные задачи вы выбираете подходящий метод: линейную регрессию для прогнозов, деревья решений для классификации, нейросети для распознавания изображений. Рассмотрим все эти решения чуть подробнее.
Линейная регрессия
Один из самых простых и понятных способов сделать прогноз. Строится прямая линия, которая наилучшим образом описывает зависимость между переменными. Чем больше данных — тем точнее. Подробнее об этом инструменте читайте здесь.
Где применяется: прогноз продаж, оценка спроса, анализ трендов.
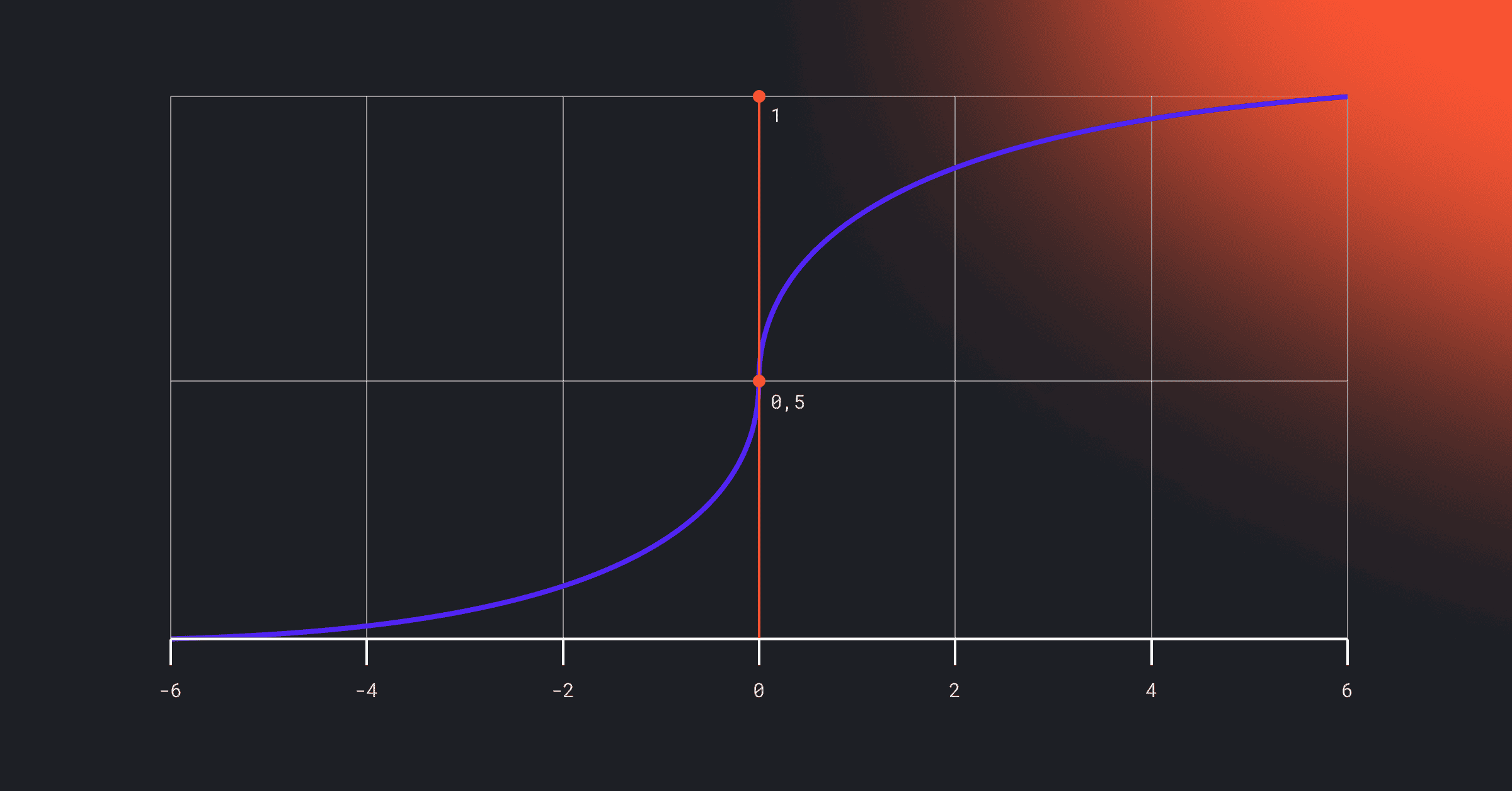
Логистическая регрессия
Используется для классификации. Например, определить, перейдет клиент по ссылке или нет. Логистическая регрессия выдает вероятность: если она выше порога, относим к одному классу, если ниже — к другому. Больше об этом и других методах регрессионного анализа, читайте в этой статье.
Где применяется: выявление спама, прогноз ухода клиентов, диагностика заболеваний.
Решающие деревья
Представьте схему с вопросами и ответами: «Больше 10 тысяч на счете?» — да или нет. «Есть просроченные кредиты?» — да или нет. Алгоритм принимает решения, задавая последовательность вопросов (условий) на основе характеристик объекта. Работает по принципу разветвлений и хорошо объясняет, почему было принято то или иное решение.
Где применяется: одобрение кредита, принятие бизнес-решений, оценка рисков.
Случайный лес
Когда одного дерева недостаточно, в дело вступает целый лес. Этот метод объединяет множество решающих деревьев и усредняет их выводы. Это повышает точность и устойчивость модели, особенно на сложных и шумных данных.
Где применяется: в медицине, финансах, маркетинге — везде, где важна надежность предсказания.

Бустинг
Это каскад: слабые модели (обычно деревья) обучаются друг за другом, и каждая новая старается исправить ошибки предыдущих. В результате получается мощная и точная система. Бустинг — один из алгоритмов машинного обучения, который показывает одни из лучших результатов на практике, особенно в соревнованиях по анализу данных.
Где применяется: в оценке кредитоспособности, рекомендательных системах, задачах классификации и регрессии.

Метод k-ближайших соседей (k-NN)
Очень интуитивный подход. Чтобы классифицировать объект, программа смотрит, кто находится рядом в пространстве признаков. Например, если вокруг много красных точек, значит, и этот объект, скорее всего, красный. Это как спросить совета у соседей и выбрать самый популярный вариант.
Где применяется: распознавание рукописного текста, рекомендации товаров, поиск похожих объектов.
Метод опорных векторов
Представьте себе линию, которая разделяет два класса так, чтобы между ними было как можно больше свободного пространства. Метод опорных векторов как раз ищет такую границу. Подходит, когда нужно четкое разделение между категориями.
Где применяется: анализ изображений, биоинформатика, классификация текстов.

Наивный байесовский классификатор
В его основе лежит теорема Байеса. Метод предполагает, что признаки не зависят друг от друга. Отсюда слово «наивный». Несмотря на столь сильное допущение (нереалистичное в реальных данных), классификатор часто дает хорошие результаты и быстро обучается благодаря простоте вычислений.
Где применяется: фильтрация спама, анализ отзывов, автоматическая категоризация.
Нейронные сети
Вдохновленные работой человеческого мозга, нейросети состоят из узлов (нейронов), которые передают сигналы друг другу. Хорошо справляются с распознаванием сложных шаблонов и зависимостей в информации. Особенно полезны, когда данных много и они неструктурированные, например, изображения или звук.
Где применяется: распознавание речи, генерация текста, управление автопилотами.

Сверточные нейросети (CNN)
Особый вид нейронных сетей, который отлично работает с изображениями. Они «видят» картинку, как человек: сначала распознают контуры, потом формы и, наконец, объекты. Именно они распознают лица, номерные знаки и помогают врачам находить болезни по снимкам.
Где применяется: компьютерное зрение, медицина, автопилоты, контроль качества на производстве.
Что можно сделать с помощью алгоритмов машинного обучения
Все вышеописанные инструменты решают вполне прикладные задачи, которые помогают бизнесу, медицине, образованию и многим другим сферам работать эффективнее.
Прогнозирование целевой категории
Здесь нужно угадать, к какому классу относится объект. Спам это или нет? Болен человек или здоров? Покупатель уйдет или останется? Модель смотрит на признаки и решает, к какой категории отнести. Например, по кредитной истории клиента банк определяет, выдавать ли заем — одобрить или отказать.
Поиск необычных точек данных
Иногда суть, чтобы заметить что-то странное или необычное. Это называется поиск аномалий. Алгоритмы учатся распознавать «нормальное» поведение, а потом сигнализируют, если что-то выбивается из привычной картины. Так банковская система замечает неожиданно большую транзакцию с новой локации — и блокирует ее до выяснения.
Прогнозирование значений
Когда вместо категории нужно получить конкретное число — это задача регрессии. Сюда относится все, что связано с прогнозами чисел: цены, доходы, рейтинги, спрос.
Таким образом приложение предсказывает, сколько шагов вы сделаете сегодня на основе вашей активности за последние дни.

Изменение значений со временем
Некоторые данные меняются с течением времени — курсы валют, погода, трафик на сайте. Такие задачи называются анализом временных рядов, и для них нужны особые методики, которые учитывают зависимость от времени. Например, прогноз погоды на завтра строится на наблюдениях за прошлые дни и сезоны.
Обнаружение сходства
Иногда нужно найти, что похоже на что. Так работают рекомендации: если вы посмотрели один фильм, модель найдет похожие — по жанру, актерам или сюжету. Или онлайн-магазин предлагает вам товары, похожие на то, что вы уже покупали.
Классификация
Здесь требуется разбить объекты по группам. Отличие от прогнозирования категории в том, что тут группы фиксированы и заранее известны. Допустим, приложение для распознавания растений определяет, что перед нами — дуб, клен или береза.
Что такое библиотеки машинного обучения
Программисты и аналитики используют специальные библиотеки — готовые наборы инструментов, которые упрощают создание моделей, обработку данных и визуализацию результатов.
Классификация методов и способов машинного обучения — это как раз то, что лежит в основе этих фреймворков. Не можем тут перечислить все, но упомянем самые популярные.
- Scikit-learn — одна из самых универсальных. Подходит для задач классификации, регрессии, кластеризации и работы с базовыми моделями. Очень дружелюбна для новичков.
- TensorFlow и Keras — мощные библиотеки для построения нейронных сетей и глубокого обучения. Идеальны, если вы хотите поработать с изображениями, распознаванием речи или рекомендательными системами.
- XGBoost и LightGBM — библиотеки градиентного бустинга, часто используются для участия в соревнованиях и в продакшене, потому что дают высокую точность.
- PyTorch — еще один набор инструментов для построения глубоких нейронных сетей, любимый многими за гибкость и простоту отладки.
Заключение
ML уже стало неотъемлемой частью нашей повседневной жизни — от рекомендаций фильмов до систем безопасности и финансовой аналитики. Чтобы уверенно чувствовать себя в этой сфере, важно понимать, как работают методы обучения модели машинного обучения и базовые типы алгоритмов, какие задачи они решают и чем отличаются между собой.
Мы рассмотрели основные подходы, методы и библиотеки, которые помогут сделать первые шаги в этой области.











