Создаем пет-проект по аналитике в связке с GitHub Actions. Часть 2
Статья будет полезна начинающим аналитикам в поисках хорошего проекта для своего портфолио. В этой части разбираю подход к выбору проекта и источника данных, к сбору и анализу данных и представлении результатов своей работы.

В прошлый раз подробно описала гайд по работе с GitHub actions, перед прочтением этой части рекомендую ознакомиться сперва с ним.
Выбираем проект и проблему
Лучшим вариантом будет выбрать не просто проект по анализу данных с kaggle, а проект, приближенный к реальности. То есть тот, который включает в себя:
- Реальные данные — те, которые можно получить в настоящий момент времени
- Использование нескольких инструментов (sql, python, git, excel — в любой комбинации)
- Наличие проблемы и решения этой конкретной проблемы
- Корректные и применимые выводы
То есть идеальный проект — это по факту исследовательская задача по рабочему проекту, для которой ты сам выбираешь способ реализации.
Для выбора темы лучше всего ориентироваться на собственные интересы (так легче довести задачу до конца) и на возможность получать данные в реальном времени по этой интересующей теме.
Тут выручают API или парсинг данных с сайтов. Не всегда можно/ удобно это реализовывать, поэтому придется поискать лучший для себя вариант.
Для этой статьи я подобрала удобный пример — парсинг данных с тг каналов. Во первых, для меня эта тема актуальна из-за ведения тг канала, во вторых это вполне доступная история:)
Особой проблемы у меня нет, поэтому накручу ее себе — к примеру, я хочу понимать статистику по tg-каналам конкурентов. Для выстраивания стратегии по ведению мне необходимо понимать:
- Как растут чужие tg-каналы (количество подписчиков, ежедневный рост)
- Охваты постов
- Частота публикации контента
- Темы публикации
- Вовлеченность пользователей в контент (комментарии, лайки, просмотры)
- Топовые темы/ ключевые слова для публикаций, которые выходят в топ по метрикам вовлеченности
- Наличие реклам
Делаю вид, что tg-stat в моей реальности не существует или там недостаточно глубокий анализ для моего запроса -> потому у меня есть потребность сделать этот проект вручную без использования уже существующих инструментов.
В этой статье разбираю только парсинг по количеству подписчиков и немного визуализации результатов, чтобы не раздувать статью. Но с помощью этого способа можно реализовать и остальные задачи.
Где брать данные?
Как уже упомянула ранее — данные нам можно доставать через API или парсинг сайтов/ страниц.
Вот несколько источников, которые можно использовать для своих проектов:
- Apple store через официальный API (https://developer.apple.com/documentation/appstoreconnectapi)
- Google Play через библиотеку google-play-scraper
- Telegram — через API или библиотеки (разберем ниже)
- Alpha Vantage через API (https://www.alphavantage.co/)
- World Bank по API (https://documents.worldbank.org/en/publication/documents-reports/api)
- Faker по API (https://fakerjs.dev/)
Так как я разбираю Tg, то данные буду брать из него.
Из телеграмма можно доставать данные через python библиотеки, а также через обходные пути (парсинг html страниц).
На что будем обращать внимание:
| Интересующие нас параметры | Telethon | Парсинг |
| Дата и время поста | ✅ | ✅ |
| Просмотры | ✅ | ✅ |
| Полный текст | ✅ | ✅ |
| Реакции | ✅ | ✅ |
| Количество подписчиков | ✅ | |
| Официальный способ | ✅ | |
| Сбор через личный tg аккаунт | ✅ | |
| Сбор без логина в tg | ✅ | |
| Отсутствие лимитов по запросам и времени между запросами | ✅ | |
| Наличие риска бана аккаунта | ✅ | |
| Простота реализации | ✅ |
Моя первая попытка была именно через Telethon и, после пары первых успешных попыток, я постоянно начала ловить разлогирование со своего аккаунта. И эта проблема не решилась даже после добавления задержек между запросами.
Еще одной причиной этой проблемы были повторяющиеся запросы — tg их легко отлавливает и стопорит.
Когда мой акк в tg заблочили на ~30 минут первый раз я решила, что такого я больше не переживу и надо искать способ попроще для моих нервов.
С учетом того, что я настраивала ежедневный сбор данных, то у меня не было задачи смотреть в глубину канала и проверять посты годовой давности. Для такой постановки вопроса парсинг звучит проще и реализуемей (и головной боли тоже становится меньше).
Поэтому для этого проекта выбор остановила именно на простом парсинге html страниц tg-каналов (те самые, которые открываются в браузере, когда ты переходишь по ссылке).
Реализация и скрипты
Настроить сам парсинг довольно просто, на этом этапе нет серьезных подводных камней. Структура всех документов будет выглядеть следующим образом
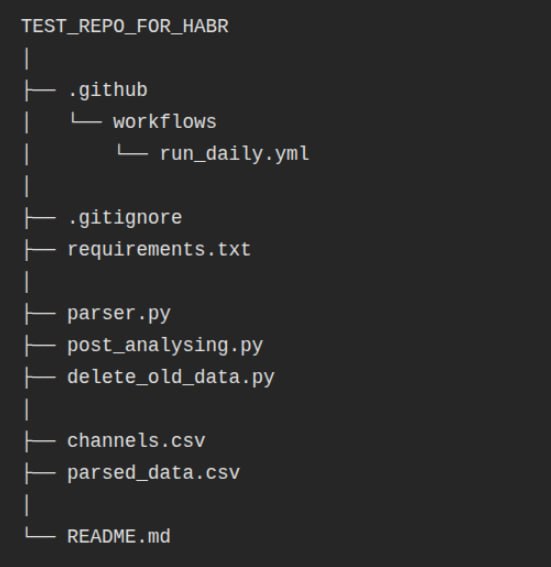
TEST_REPO_FOR_HABR
│
├── .github
│ └── workflows
│ └── run_daily.yml
│
├── .gitignore
├── requirements.txt
│
├── parser.py
├── post_analysing.py
├── delete_old_data.py
│
├── channels.csv
├── parsed_data.csv
│
└── README.md
Создание технических файлов (.gitignore и requirements.txt) / файлов из .github описала в прошлой статье. А остальные разберем ниже подробнее.
Для проекта создадим три python файла:
- parser.py — для парсинга нужных данных
- post_analysing.py — для анализа данных/ подсчета метрик/ построения визуализации
- delete_old_data.py — для удаления данных старше N месяцев
И создадим 2 csv файла:
- channels.csv — список каналов, которые будем использовать для анализа
- parsed_data.csv — данные, которые собираем через parser.py
Пример рабочего скрипта parser.py
Этот скрипт будет записывать количество подписчиков ежедневно по каждому каналу. Для того, чтобы пощупать этот способ и собрать свои первые данные первый раз — самое то.
import os
import csv
import re
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Настраиваем драйвер для чтения страницы
options = Options()
# Без открытия окна браузера
options.add_argument(‘—headless’)
options.add_argument(‘—disable-gpu’)
options.add_argument(‘—no-sandbox’)
# Отключаем ненужные логи
options.add_argument(‘—log-level=3’)
# Создаём сервис с подавлением логов
service = Service(ChromeDriverManager().install(), log_path=’NULL’)
# Настраиваем драйвер для запуска браузера
driver = webdriver.Chrome(service=service, options=options)
# Достаем список каналов
channel_list = []
with open(‘channels.csv’, ‘r’, encoding=’utf-8′) as ch_file:
reader = csv.DictReader(ch_file)
for row in reader:
url = row[‘url’].strip().strip(«‘\»»)
if url and url.startswith(«https://t.me/»):
channel_list.append(url)
# Указываем файл, куда будем сохранять данные по каналу
csv_file = ‘parsed_data.csv’
csv_exists = os.path.exists(csv_file)
# Получаем сегодняшнюю дату
date_today = datetime.now().strftime(«%Y-%m-%d»)
# Проверяем, есть ли уже данные за сегодня
already_parsed_today = False
saved_entries = set()
# Читаем ранее сохранённые username
if csv_exists:
with open(csv_file, ‘r’, encoding=’utf-8′, newline=») as f:
reader = csv.DictReader(f)
name_field = ‘username’ if ‘username’ in reader.fieldnames else ‘channel_name’
for row in reader:
saved_entries.add((row[‘date’], row[name_field]))
if row[‘date’] == date_today:
already_parsed_today = True
if already_parsed_today:
print(f»\n🟡 Данные за {date_today} уже есть — парсинг не выполняется.»)
driver.quit()
exit()
# Парсим и сохраняем данные
with open(csv_file, ‘a’, encoding=’utf-8′, newline=») as f:
writer = csv.writer(f)
if not csv_exists:
writer.writerow([‘date’, ‘channel_name’, ‘subscribers’])
print(«\n🟢 Запуск парсинга и сохранение данных:\n» + «-» * 60)
for url in channel_list:
if (date_today, url) in saved_entries:
print(f»⏭️ Пропущено (уже есть): {url}»)
continue
connect_status = «❌»
data_status = «❌»
clean_title = «—»
subs = «—»
try:
driver.get(url)
connect_status = «✅»
time.sleep(5)
text = driver.find_element(«tag name», «body»).text
lines = text.splitlines()
for i, line in enumerate(lines):
if «subscribers» in line.lower():
raw_title = lines[i — 1] if i > 0 else «—»
subs = re.sub(r'[^\d]’, », line).strip()
channel_name = re.sub(r'[^а-яА-Яa-zA-ZёЁ\s]’, », raw_title).strip()
data_status = «✅»
break
except Exception as e:
channel_name = f»⚠️ Ошибка: {str(e)}»
print(f»{channel_name} — {date_today} — {subs} ({url})»)
if data_status == «✅»:
writer.writerow([date_today, channel_name, subs])
driver.quit()
Можем переходить к следующему шагу — анализ данных и отправка результатов. Для отправки нам понадобится:
Создать приватный tg канал
Создать бота в tg
Раздать админские права боту в созданном tg канале
Получить токен бота и id tg канала
Добавить полученные данные в secrets в Git
Описывать эти действия тут не буду дабы не плодить кучу повторяющейся информации в интернете.
Но вообще для этих действий пригодится только бот BotFather — в нем уже есть встроенная инструкция по созданию бота.
Перейдем к написанию скрипта для анализа данных, визуализации и отправки в созданный приватный канал.
Пример несложного скрипта можно подсмотреть ниже.
import os
import requests
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
from dotenv import load_dotenv
load_doten()
# Загружаем данные по каналам, которые мы уже собрали на предыдущем шаге
df = pd.read_csv(‘parsed_data.csv’)
df[‘date’] = pd.to_datetime(df[‘date’])
df[‘subscribers’] = df[‘subscribers’].astype(int)
# Фильтруем данные за последние 30 дней
one_month_ago = datetime.now() — timedelta(days=30)
one_week_ago = datetime.now() — timedelta(weeks=1)
df = df[df[‘date’] >= one_month_ago]
df_week = df[df[‘date’] >= one_week_ago]
# Выбираем целевой канал, на который будем ориентироваться при построении визуализации.
# Условно — это канал, который для нас наиболее интересен.
# Выбираю канал по слову в его наименовании
target_channel = ‘ANY_CHANNEL_NAME’
target_matches = df[df[‘channel_name’].str.contains(target_channel, case=False, na=False)]
if target_matches.empty:
raise ValueError(f»Не найден канал с ключом: {target_channel}»)
main_channel_name = target_matches[‘channel_name’].iloc[0]
# Вычисляем прирост для всех каналов за 30 дней
growth = df.groupby(‘channel_name’)[‘subscribers’].agg([‘min’, ‘max’])
growth[‘delta’] = growth[‘max’] — growth[‘min’]
growth = growth.reset_index()
main_subs = growth[growth[‘channel_name’] == main_channel_name][‘max’].values[0]
# Отбираем ближайшие каналы к нашему целевому. Это сделано для того, чтобы снизить разброс между каналами на графике.
closest_above = growth[growth[‘max’] > main_subs].sort_values(by=’max’).head(10)
closest_below = growth[growth[‘max’] < main_subs].sort_values(by=’max’, ascending=False).head(3)
main_channel_row = growth[growth[‘channel_name’] == main_channel_name]
top_channels = pd.concat([closest_below, main_channel_row, closest_above])
# Формируем текст с метриками прироста
metrics_text = «\U0001F4CA <b>Метрики прироста за месяц:</b>\n»
metrics_text += «_________________________________\n\n»
for , row in topchannels.sort_values(by=’max’).iterrows():
start = row[‘min’]
end = row[‘max’]
delta = row[‘delta’]
percent = (delta / start * 100) if start > 0 else 0
channel_label = row[‘channel_name’]
icon = ‘\U0001F31D’ if channel_label.strip().lower() == ‘ANY_CHANNEL_NAME’ else ‘\U0001F4AC’
metrics_text += (
f»{icon} <b>{channel_label}</b>\n»
f» Подписчиков: {end}\n»
f» Прирост за месяц: <b>{percent:.2f}%</b>\n\n»
)
# Фильтруем данные только для нужных каналов
df_plot = df[df[‘channel_name’].isin(top_channels[‘channel_name’])]
# Сортируем каналы по числу подписчиков
channel_order = (
top_channels.sort_values(by=’max’, ascending=False)[‘channel_name’].tolist()
)
# Строим график
def wrap_label(text, max_len=25):
words = text.split()
lines = []
current = «»
for word in words:
if len(current + » » + word) <= max_len:
current += » » + word if current else word
else:
lines.append(current)
current = word
if current:
lines.append(current)
return ‘\n’.join(lines)
plt.figure(figsize=(12, 6))
for name in channel_order:
group = df_plot[df_plot[‘channel_name’] == name].sort_values(‘date’)
if name.strip().lower() == main_channel_name.strip().lower():
plt.plot(
group[‘date’],
group[‘subscribers’],
label=f’>> {name} <<‘,
color=’red’,
linewidth=2
)
else:
plt.plot(
group[‘date’],
group[‘subscribers’],
label=wrap_label(name),
linestyle=’—‘,
linewidth=1.5,
alpha=0.8
)
plt.title(‘Динамика подписчиков за последние 30 дней’)
plt.grid(True)
plt.legend(
loc=’center left’,
bbox_to_anchor=(1.0, 0.5),
borderaxespad=0.5,
fontsize=9,
frameon=False
)
plt.subplots_adjust(right=0.75)
min_date = df[‘date’].min()
max_date = df[‘date’].max()
tick_dates = pd.date_range(start=min_date, end=max_date, freq=’5D’)
plt.xticks(tick_dates, rotation=0)
plot_path = ‘participants_growth.png’
plt.savefig(plot_path)
# Отправка текста и графика в Telegram
bot_token = os.getenv(‘bot_token’)
channel_id = os.getenv(‘channel_id’)
send_text_url = f»https://api.telegram.org/bot{bot_token}/sendMessage»
payload = {
‘chat_id’: channel_id,
‘text’: metrics_text,
‘parse_mode’: ‘HTML’
}
requests.post(send_text_url, data=payload)
send_photo_url = f»https://api.telegram.org/bot{bot_token}/sendPhoto»
with open(plot_path, ‘rb’) as photo:
requests.post(
send_photo_url,
data={‘chat_id’: channel_id},
files={‘photo’: photo}
)
Результаты
Скрипт выдает довольно скромную визуализацию и текст, при наличии желания всё это можно подстроить под свои хотелки.
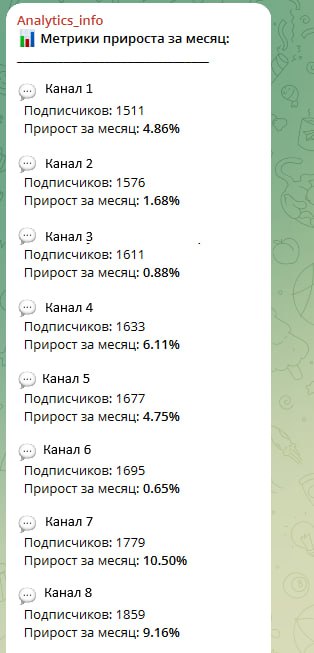
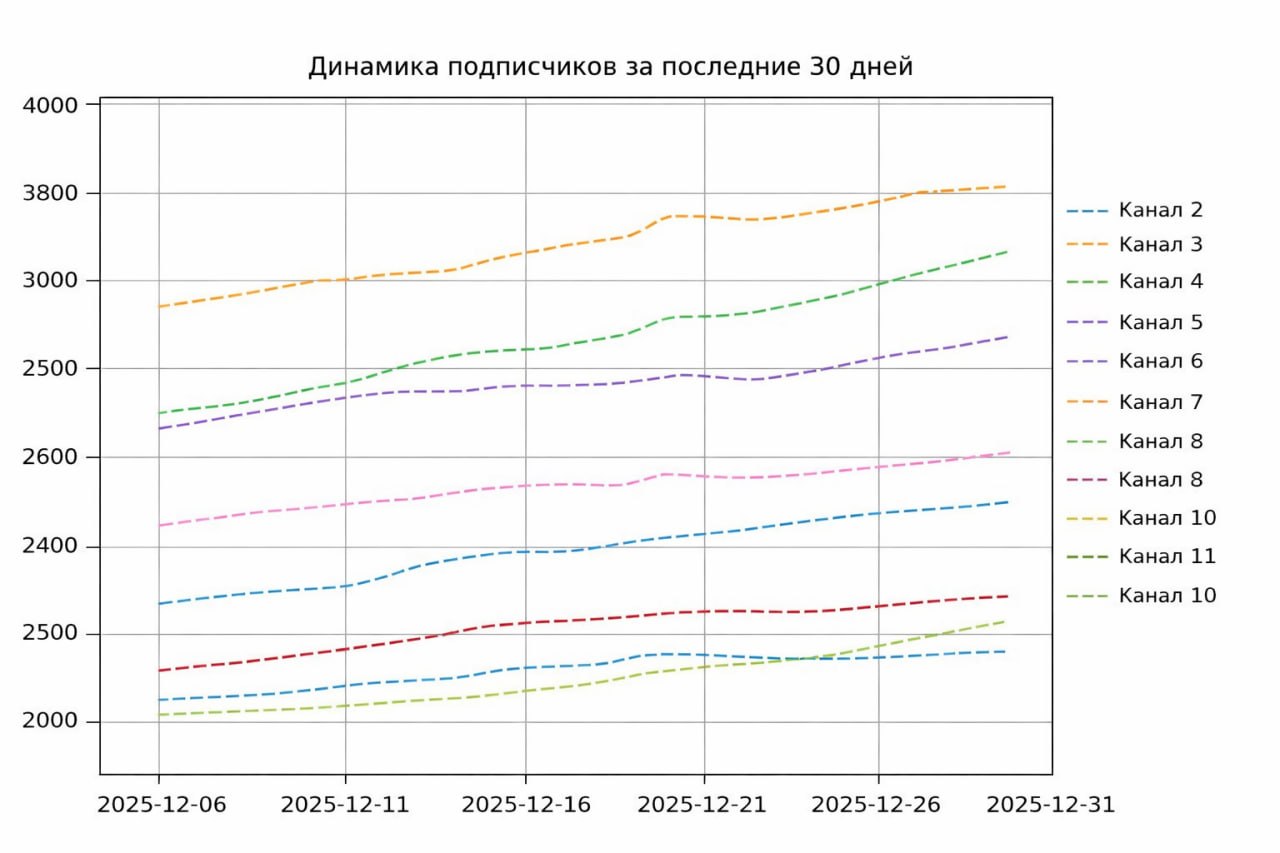
Такие полученные результаты полноценным проектом назвать нельзя, так как мы еще не закрыли остальные требования к хорошему проекту. Поэтому не рекомендую останавливаться на этом шаге. Как минимум тут нужны выводы, а только по росту каналов выводов особо не сделаешь :). Поэтому, в любом случае, нужно добавлять дополнительные метрики и погружаться в дальнейший анализ.
Анализ текста, просмотров, наличие реклам и прочего оставлю на будущие разборы, но к тому моменту возможно у вас на руках уже будет доработанный проект 🙂
Итоги
Парсинг данных в сочетании с GitHub Actions — хороший и простой способ для создания своего небольшого проекта для портфолио.
Это точно лучше заезженных историй с «датасетом по Титанику», поэтому 100 % рекомендую для развития на старте.
