Алгоритмы машинного обучения: методы и способы их применения
Искусственный интеллект побеждает гроссмейстеров в шахматы, определяет болезни по снимкам и подсказывает, какой сериал посмотреть дальше. Благодаря чему это все работает? Разбираемся, что такое ML и в методах машинного обучения — что это, чем они отличаются друг от друга, как устроены и где применяются.
Содержание
- Что такое машинное обучение простыми словами
- Как работает машинное обучение
- Виды машинного обучения: классификация по типу обучения
- Классификация ML-алгоритмов по типу решаемых задач
- Основные алгоритмы машинного обучения
- Как выбрать алгоритм машинного обучения
- Примеры применения алгоритмов машинного обучения в жизни
- Заключение
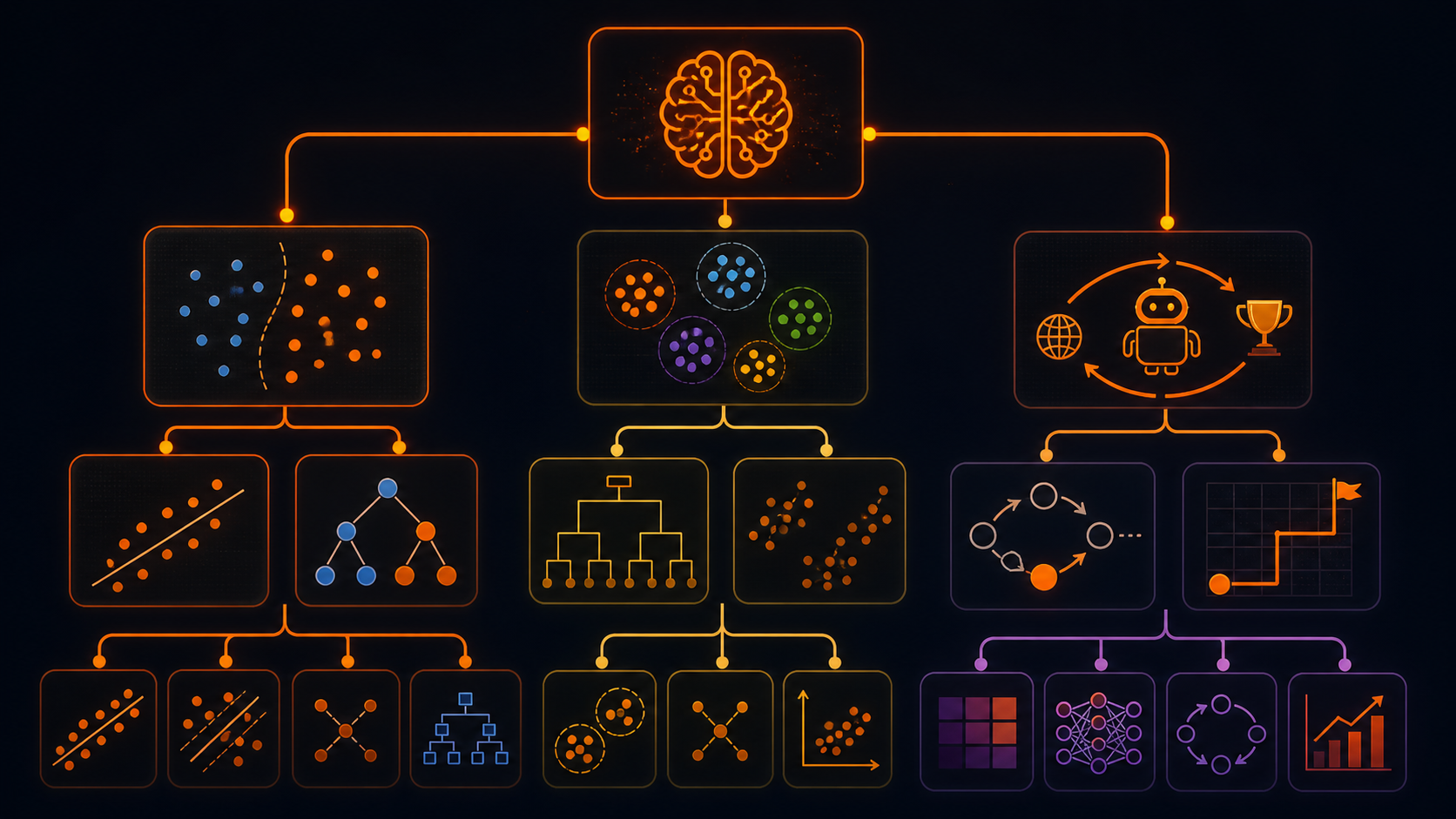
Что такое машинное обучение простыми словами
Представьте, что владеете кофейней и каждый день записываете, какие напитки покупают посетители. Через месяц накапливается таблица: день недели, погода, количество проданных чашек. Возникает вопрос: можно ли по этим данным предсказать, сколько заказов будет завтра? Или понять, в какие дни стоит готовить больше латте, а когда — эспрессо?
Машинное обучение (Machine Learning, ML) — это подраздел искусственного интеллекта (ИИ) и обширная область компьютерных наук. Его главная идея заключается в том, чтобы обучать компьютерные системы на данных, а не писать для каждой конкретной задачи жесткие инструкции или правила.
Алгоритмы машинного обучения ML — это наборы правил и методов, которые позволяют компьютеру учиться на примерах, а не просто выполнять заранее заданные инструкции.
Это основа голосовых помощников, систем распознавания лиц, фильтрации спама, медицинских прогнозов и других технологий, которые мы используем каждый день.
Обработав сотни и тысячи записей о работе кофейни, математическая ML-модель начинает улавливать связи. Дождливый понедельник? Спрос на какао вырастет. Солнечная пятница? Готовьте больше холодного латте.
Если вы хотите освоить эту науку на реальных задачах, приходите на курс «Инженер машинного обучения». Здесь вы шаг за шагом погрузитесь в интересную область с нуля: от основ Python до построения нейросетей, статистики и A/B-тестов. Чтобы начать, достаточно знания школьной математики и базовых навыков работы с числами и функциями.
Как работает машинное обучение
Любой проект в этой сфере держится на трех китах: данных, признаках и алгоритме. Можно долго спорить, что важнее, но на практике без любого из этих элементов модель просто не построить. Далее разберем, что скрывается за каждым термином, откуда все берется и как связаны между собой эти компоненты.
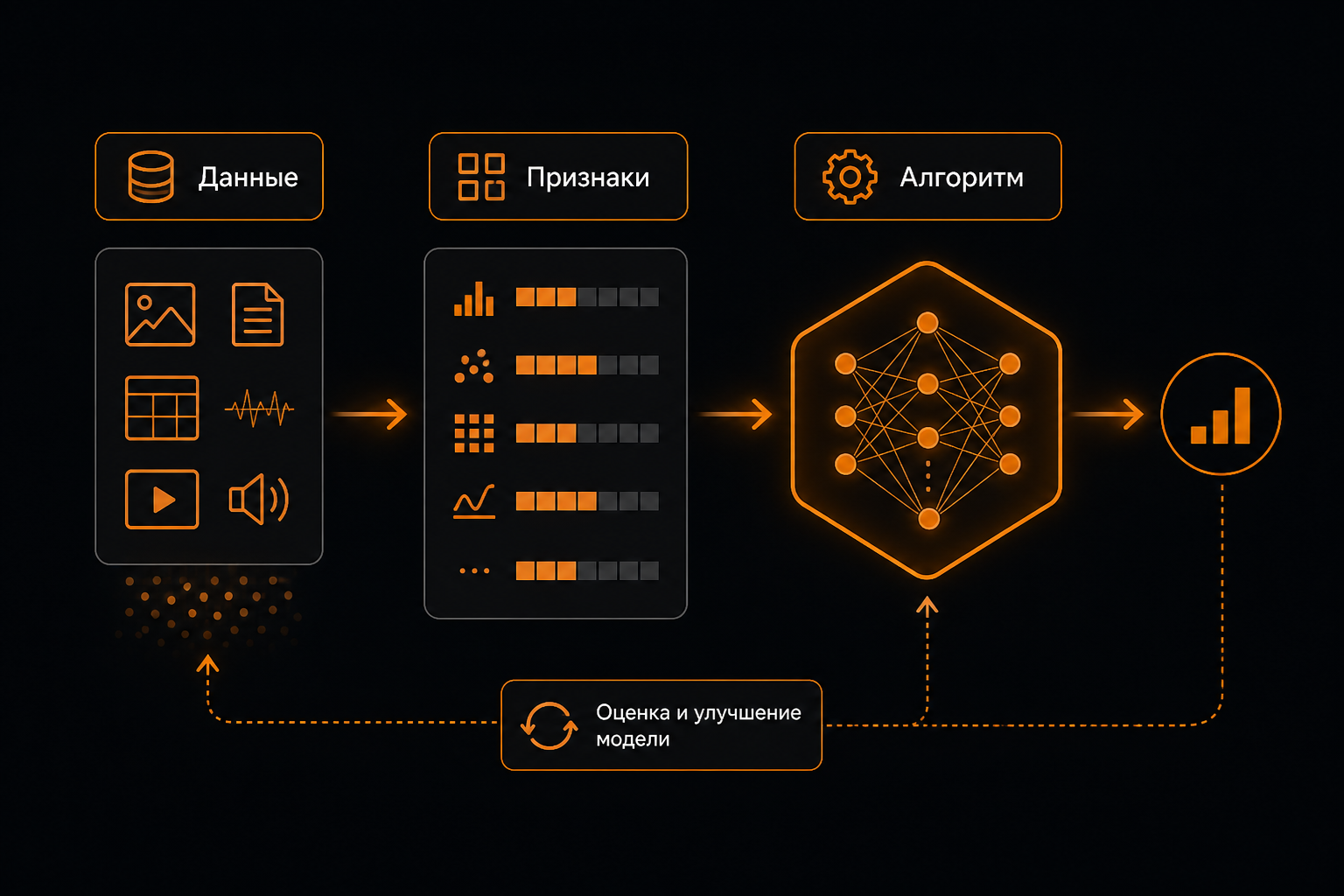
Данные (датасеты)
Возвращаемся в кофейню. Вы записывали продажи целый месяц, и получилась таблица: строки — это дни, столбцы — погода, день недели, количество проданных чашек. Это и есть датасет, т.е. организованный набор данных, с которым будет работать алгоритм.
Данные — это топливо для обучения. Без них модели просто нечему учиться. И чем они качественнее и разнообразнее, тем точнее окажутся прогнозы. Если вы записывали продажи только по солнечным вторникам, не ждите, что ML-модель предскажет спрос в дождливую субботу. Она просто не видела таких примеров.
Три источника, откуда брать данные:
- Внутренние ресурсы компании. Это CRM-система, чеки, логи сервера, записи в Excel.
- Открытые источники. Например, официальная статистика, архивы погоды, информация из соцсетей.
- Собственный сбор, когда компания целенаправленно запускает опросы, датчики или анкеты, чтобы получить то, чего нет в готовом виде.
Чаще всего данные попадают в работу в виде таблиц, где строки — объекты наблюдения, а столбцы — их характеристики. Но могут быть и изображения, тексты, звукозаписи.
Важно
Данные требуют очистки: убрать дубликаты, заполнить пропуски, исправить опечатки. Грязные данные ведут к неверным выводам, каким бы мощным ни был алгоритм. В реальных проектах подготовка часто занимает до 80% всего времени.
Признаки (features)
Это характеристики объекта, которые алгоритм машинного обучения использует для поиска закономерностей и построения прогноза. Если мы предсказываем спрос на кофе, то признаками будут погода, время суток, близость выходных. Если диагностируем заболевание — давление, возраст, результаты анализов. От того, какие признаки мы отберем, точность модели зависит сильнее, чем от выбора самого ML-метода.
Хороший признак обладает двумя свойствами:
- Действительно связан с тем, что мы предсказываем.
- Вносит что-то новое, а не дублирует уже имеющуюся информацию.
Например, температура в градусах Цельсия и по Фаренгейту — один и тот же признак, и толку от его дублирования нет.
Типичная ошибка новичка: добавить как можно больше признаков в надежде, что алгоритм сам во всем разберется. Лишние, неинформативные признаки размывают картину, замедляют обучение и могут ухудшить точность. Лучше меньше, да лучше.
Алгоритм
Итак, информация собрана, признаки выделены. Теперь в дело вступает математический метод, который ищет в данных закономерности и строит на их основе правило для прогнозов.
Алгоритм получает на вход таблицу, т.е. строки с признаками. Он начинает с некоторого начального предположения, почти наверняка ошибочного. Затем вычисляет, насколько сильно ошибся, и корректирует внутренние параметры, чтобы в следующий раз быть точнее. Цикл — предсказал, измерил ошибку, подстроился — повторяется тысячи раз, пока качество не перестанет расти.
Важно
Нет универсального метода, который одинаково хорош для всего. Некоторые ML-алгоритмы ищут простые линейные зависимости, другие способны улавливать сложные нелинейные связи. Одни работают быстро и выдают понятный результат, но могут быть неточными. Другие выдают высочайшую точность, но работают как черный ящик, т.е. в их логику сложно заглянуть.
Выбор всегда зависит от трех вещей: какая задача решается, сколько данных доступно и насколько важна объяснимость результата.
Виды машинного обучения: классификация по типу обучения
Вернемся к примеру из кофейни. В одной ситуации у нас есть колонка «Реальные продажи» и мы просим модель научиться их предсказывать. В другой — мы просто смотрим на записи и хотим понять, не образуют ли наши посетители какие-то скрытые группы, о которых мы даже не догадывались. Ответы на эти вопросы лежат в разных подходах к обучению. Все зависит от того, есть ли в данных правильный ответ или предстоит искать закономерности без подсказок.
Обучение с учителем (Supervised Learning)
Допустим, вы наняли стажера в кофейню и учите его определять, будет ли день загруженным. Показываете записи за последние месяцы, где для каждого дня уже проставлен результат «Загружен» или «Свободен». Стажер смотрит на данные, сопоставляет признаки с итогом и постепенно выводит для себя правило: если пятница и солнечно — будет много посетителей. Через какое-то время он начинает предугадывать загрузку на будущее.
Это обучение с учителем. Учитель в данном случае — не человек, а сами данные, в которых для каждого примера уже известен правильный ответ. Задача алгоритма — найти связь между признаками и ответом, чтобы предсказывать его для незнакомых ситуаций.
Датасет делится на две части: обучающую и тестовую. На первой алгоритм учится, подгоняя свои параметры так, чтобы его предсказания совпадали с известными ответами. На второй, которую он в процессе обучения не видел, проверяется, насколько хорошо он справляется с новой информацией. Если модель хорошо показывает себя на обеих выборках, она готова к работе.
Обучение с учителем решает либо задачу классификации, либо задачу регрессии, о которых мы поговорим далее.
- В первом случае ответ — категория: «купит/не купит», «спам/не спам», «кошка/собака».
- Во втором — число: цена квартиры, объем продаж, температура.
Разница принципиальна, и под каждый тип подбирается свой набор методов.
Обучение без учителя (Unsupervised Learning)
Теперь представьте, что владеете кофейней не первый год, у вас тысячи чеков, но никаких пометок о том, загруженным был день или нет, вы не делали. Зато есть подозрение, что посетители чем-то различаются: одни заходят утром за эспрессо, другие сидят днем с ноутбуком и берут большой латте, третьи забегают вечером за десертом. Вы показываете данные алгоритму и просите: «Найди в этом скоплении записей какие-то осмысленные группы, я не знаю заранее, сколько их и какие они».
Это обучение без учителя. Никаких ответов в данных нет, никто не подсказывает алгоритму, что должно получиться. Он сам исследует структуру, скрытые закономерности и естественные группировки.
ML-алгоритм ищет объекты, похожие друг на друга по набору признаков, и объединяет их в кластеры. Или, наоборот, находит наблюдения, которые сильно выбиваются из общей картины. Критерий качества здесь не точность предсказания, а осмысленность и интерпретируемость полученной структуры.
Типичные задачи:
- Кластеризация: разделить клиентов на сегменты, товары на категории, документы на тематики.
- Поиск аномалий: подозрительные транзакции, сбои оборудования, не характерное поведение пользователя.
- Понижение размерности: сжать множество признаков до нескольких ключевых, чтобы данные стало проще визуализировать и анализировать без потери важной информации.
Обучение без учителя помогает формировать гипотезы. Например, сегментация клиентов часто становится первым шагом перед запуском персонализированных рассылок. Сначала метод находит группы, а уже потом для каждой группы строится отдельная стратегия.
Обучение с подкреплением (Reinforcement Learning)
Представьте, что поручаете стажеру управлять кофейней в одиночку. Правильных ответов вы не даете, вместо этого он пробует разные действия: кому-то предлагает скидку, кому-то десерт, меняет музыку, регулирует температуру в зале. В конце дня стажер смотрит на выручку и понимает: что-то сработало хорошо, что-то — не очень. На следующий день он чуть корректирует поведение, стараясь заработать больше. Постепенно, методом проб и ошибок, нащупывает оптимальную стратегию.
Это обучение с подкреплением. Алгоритм наблюдает текущее состояние среды и выбирает действие. Среда реагирует: переходит в новое состояние и выдает числовую награду — положительную или отрицательную. Алгоритм запоминает, какая последовательность действий к чему привела, и постепенно учится принимать решения не на шаг вперед, а с прицелом на общий итог.

Обучение с подкреплением незаменимо там, где решение нельзя свести к однократному прогнозу, а нужно выстроить цепочку действий с отсроченным результатом. Именно этот подход стоит за динамическим ценообразованием, когда цена товара корректируется в зависимости от спроса, времени суток и поведения конкурентов.
Классификация ML-алгоритмов по типу решаемых задач
Теперь важно понять, что именно мы хотим получить в итоге. Результат — это категория или число? От этого зависит все: какие методы рассматривать, как оценивать качество, какой результат показывать заказчику. Если на выходе ожидается «Одобрить кредит» или «Отказать» — это один сценарий. Если «123 000 рублей» — другой. Давайте разберем оба.
Задачи классификации
Классификация — это предсказание категории объекта на основе его признаков. Алгоритм анализирует данные и проводит границы между классами, чтобы, получив новый объект, отнести его к нужной группе.
- Когда классов всего два — «Спам» и «Не спам», «Одобрить кредит» или «Отказать», — говорят о бинарной классификации.
- Когда вариантов больше — например, распознать, что изображено на фото: кошка, собака или велосипед, — это многоклассовая классификация.
Принцип один и тот же, но чем больше классов, тем сложнее провести границы и тем выше требования к данным.
Это один из самых востребованных типов ML-задач в бизнесе. Он стоит за фильтрацией спама в почте, за определением мошеннических транзакций, за прогнозом оттока клиентов, за медицинской диагностикой по снимкам и за системами рекомендаций, которые решают, показывать вам этот товар или другой.
Задачи регрессии
Регрессия — это предсказание числового значения на основе признаков объекта. Здесь результат всегда лежит в непрерывной шкале: цена, температура, количество, время. Алгоритм ищет математическую зависимость между признаками и целевым числом, чтобы для любого нового набора условий выдать максимально точный прогноз.
- Если предсказание строится на одном признаке — например, только на температуре воздуха, — это простая регрессия.
- Когда признаков несколько, говорят о множественной регрессии.
В реальности факторов всегда больше: день недели, сезон, близость праздников, цена, активность конкурентов. Чем больше удается учесть, тем точнее прогноз, но тем выше риск переусложнить модель.
Прогноз продаж и выручки, оценка стоимости недвижимости, предсказание времени доставки, расчет оптимальной цены, прогноз потребления энергии, оценка вероятности поломки оборудования в днях — все это типичные регрессионные задачи.
Основные алгоритмы машинного обучения
Пройдем путь от простых и прозрачных методов к более сложным и мощным. Разберемся, как все это работает, когда применять и с какими ограничениями придется столкнуться.
Линейная регрессия (Linear Regression)
Самый простой и понятный способ сделать числовой прогноз. Представьте: вы наносите на график точки — сколько чашек кофе продано в зависимости от температуры на улице. Чем холоднее, тем больше кофе покупают. Точки выстраиваются в примерную линию, идущую вниз. Линейная регрессия проводит через эти точки прямую, которая описывает зависимость лучше всего, и с ее помощью предсказывает продажи для любой температуры.
Этот метод входит в число классических алгоритмов машинного обучения, с которых начинают знакомство с ML-моделированием.
Выбирайте, если:
- Важна объяснимость. Линейная модель прямо покажет, что каждый градус тепла отнимает у вас примерно пять чашек.
- Данных мало. На небольшой выборке сложные методы склонны к переобучению, а линейная регрессия ведет себя устойчиво.
- Есть основания полагать, что зависимость действительно близка к линейной — без резких скачков и замысловатых изгибов.
Но если связь между признаками и целевым показателем сложная, прямая линия неизбежно начнет ошибаться. Кроме того, алгоритм чувствителен к выбросам: одна аномально жаркая неделя с высокими продажами может заметно исказить прогноз.
В бизнесе линейную регрессию применяют для прогноза продаж и выручки, оценки спроса, анализа трендов, расчета оптимальной цены, предсказания времени доставки, оценки стоимости недвижимости — везде, где нужно получить числовой прогноз и при этом важно понимать вклад каждого фактора.
Логистическая регрессия (Logistic Regression)
Один из ключевых алгоритмов классификации в машинном обучении. Несмотря на слово регрессия в названии, на выходе получаем не число, а вероятность принадлежности объекта к тому или иному классу.
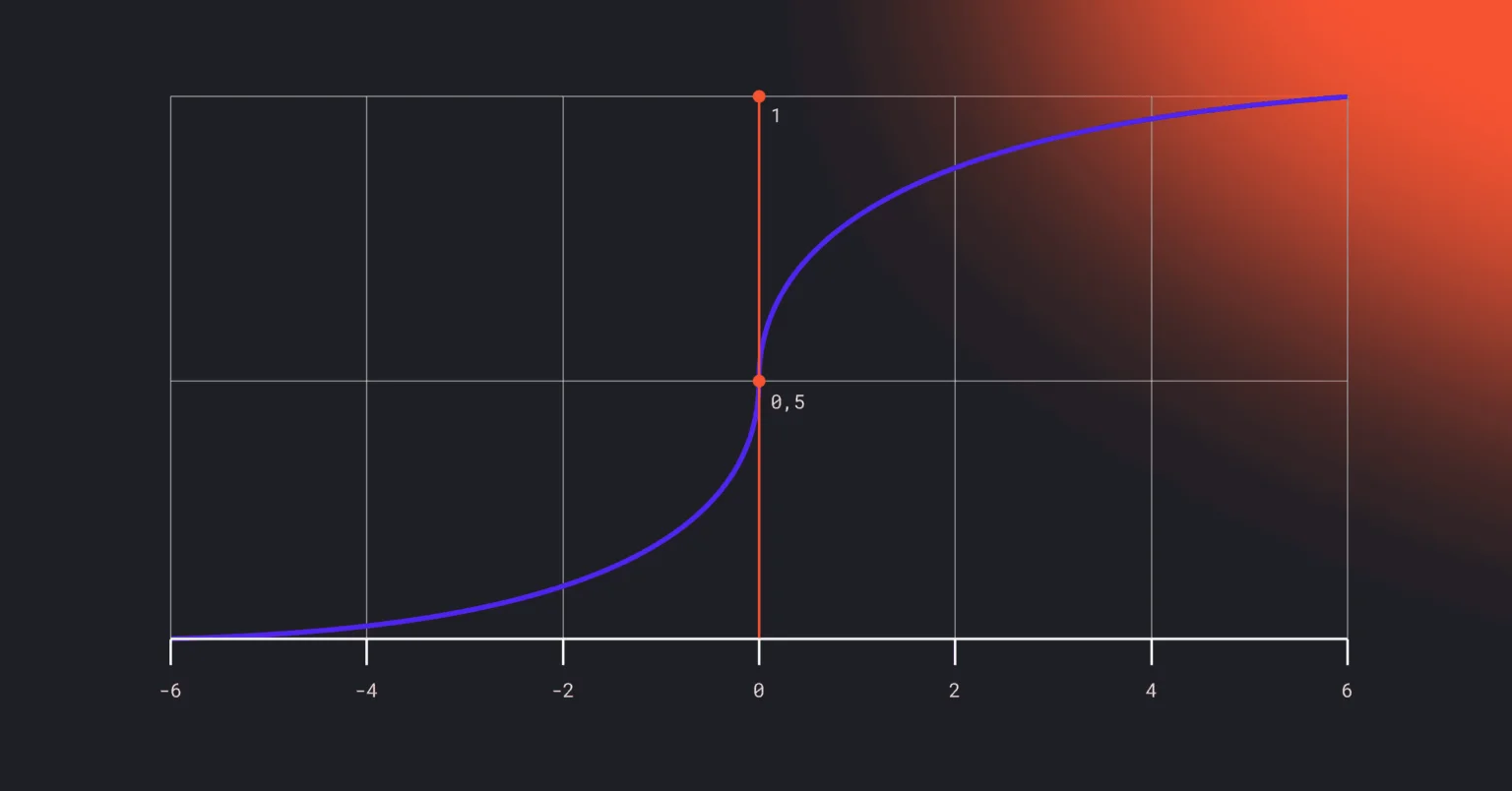
Алгоритм вычисляет вероятность события по шкале от 0 до 1. Допустим, мы хотим предсказать, перейдет ли клиент по ссылке в рассылке. Логистическая регрессия анализирует признаки — время с момента последнего клика, историю покупок, день недели — и выдает число, скажем, 0,78. Это означает: вероятность перехода — 78%. Дальше мы задаем порог, обычно 0,5, и относим объект к одному из двух классов: если выше порога — «Перейдет», если ниже — «Не перейдет».
Выявление спама в почте, прогноз оттока клиентов, кредитный скоринг, предсказание отклика на маркетинговую акцию, диагностика заболеваний по симптомам — метод используют везде, где нужно ответить «Да» или «Нет» и при этом важно объяснить, почему модель приняла именно такое решение.
Метод k-ближайших соседей (KNN)
Очень интуитивный подход. Чтобы классифицировать объект, программа смотрит, кто находится рядом в пространстве признаков. Например, если вокруг много красных точек, значит, и этот объект, скорее всего, красный. Это как спросить совета у соседей и выбрать самый популярный вариант.
Число k задается вручную: при k=3 алгоритм спросит трех соседей, при k=7 — семерых. Слишком маленькое k делает модель чувствительной к шуму, слишком большое — размывает границы между классами.
В бизнес-практике метод KNN чаще используют не как самостоятельное решение, а как быстрый способ проверить гипотезу или построить вспомогательный компонент более сложной системы.
Деревья решений (Decision Trees)
Представьте анкету: «Доход выше 50 тысяч?» — да. «Есть ли просроченные кредиты?» — нет. «Стаж на текущем месте больше года?» — да. Пройдя по цепочке таких развилок, ML-модель приходит к финальному выводу: «Кредит одобрить». Деревья решений — еще один представитель алгоритмов классификации в машинном обучении, хотя они успешно справляются и с задачами регрессии.
Деревья склонны к переобучению: если вовремя не остановиться, они будут расти, пока не запомнят каждый пример из обучающей выборки, включая шум и случайные выбросы. На новых данных такая модель провалится.
Метод активно применяют для кредитного скоринга и одобрения заявок, оценки рисков, диагностики неисправностей, сегментации клиентов по простым правилам, поддержки принятия решений. Работает по принципу разветвлений и хорошо объясняет, почему было принято то или иное решение
Случайный лес (Random Forest)
Когда одного дерева недостаточно, в дело вступает целый лес. Этот метод объединяет множество решающих деревьев и усредняет их выводы, что повышает точность и устойчивость модели, особенно на сложных и шумных данных.
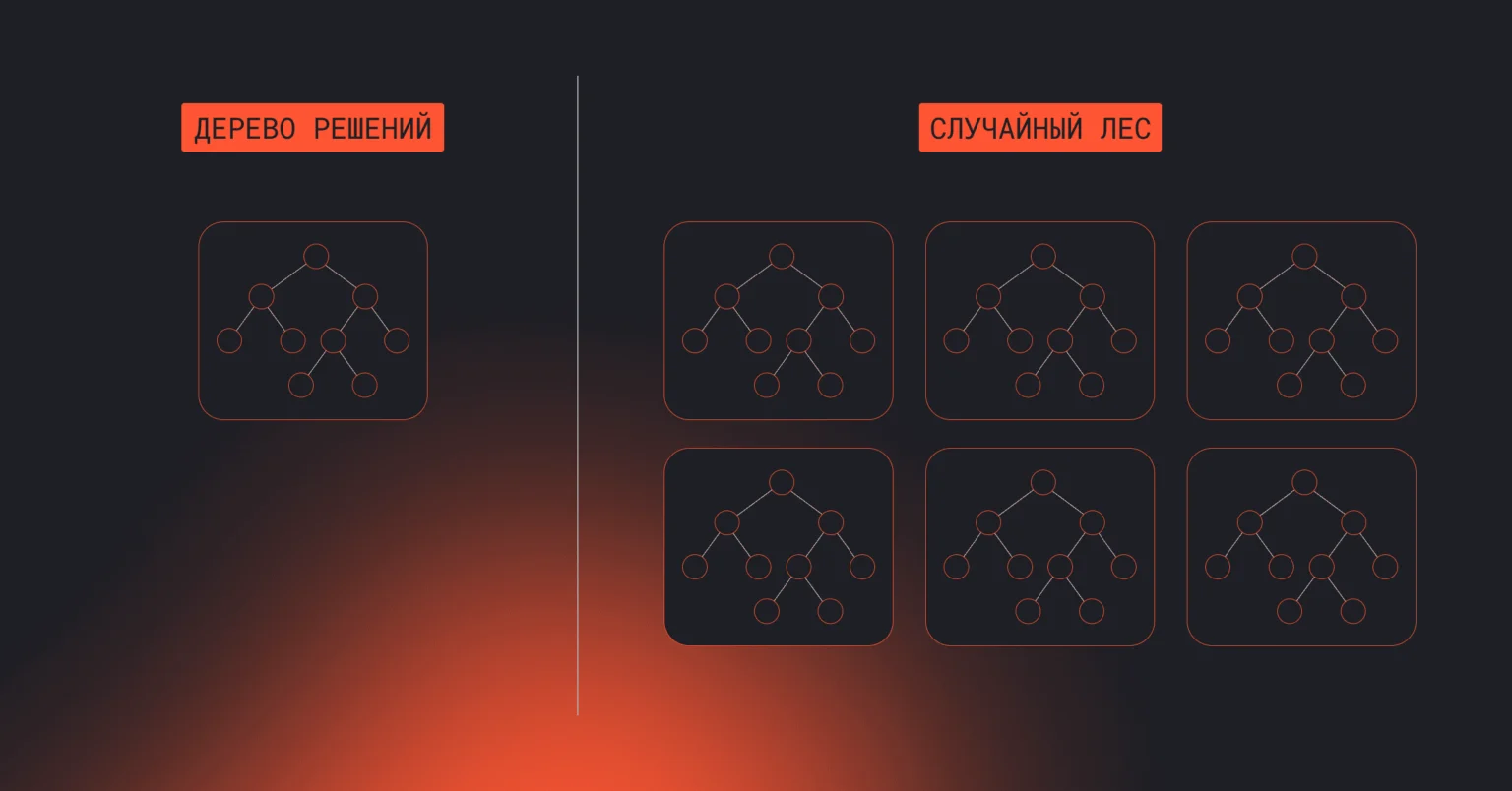
Алгоритм создает каждое дерево на случайной выборке данных и на каждом разбиении использует случайное подмножество признаков. Благодаря этому деревья получаются разными — какие-то сильнее, какие-то слабее, но вместе они сглаживают ошибки друг друга. Этот подход почти полностью снимает главную проблему одиночного дерева — склонность к переобучению.
Используется для медицинской диагностики по набору симптомов и анализов, оценки кредитных рисков, прогноза оттока клиентов, сегментации аудитории, предсказания спроса, выявление мошеннических транзакций.
Метод опорных векторов (SVM)
Представьте линию, которая разделяет два класса так, чтобы между ними было как можно больше свободного пространства. Метод опорных векторов как раз ищет такую границу. Подходит, когда нужно четкое разделение между категориями.

В отличие от деревьев и линейных моделей, SVM не дает внятной интерпретации, почему граница прошла именно так, а не иначе.
В бизнес-практике этот метод чаще используют в нишевых задачах, где важнее качество разделения классов, чем скорость или объяснимость. Например, анализ изображений, биоинформатика, классификация текстов. В эпоху нейронных сетей его роль сузилась, но на небольших и средних выборках с четкими границами он по-прежнему дает отличные результаты.
Бустинг (AdaBoost, Gradient Boosting, XGBoost)
Подход, при котором слабые модели объединяются в сильную, причем обучаются они не независимо, как в случайном лесе, а последовательно. Каждая следующая модель фокусируется на ошибках предыдущей, постепенно доводя общий результат до очень высокой точности.
Если нужна максимальная точность и вы готовы пожертвовать простотой и интерпретируемостью — бустинг, как правило, первый в списке кандидатов. Он работает одинаково хорошо на задачах классификации и регрессии. Современные библиотеки делают его достаточно быстрым даже на крупных датасетах, а встроенные механизмы регуляризации защищают от переобучения.
Оценка кредитоспособности, прогноз оттока клиентов, рекомендательные системы, ранжирование товаров в интернет-магазинах, предсказание спроса, выявление аномалий — метод хорош везде, где точность важнее прозрачности, а данные достаточно объемны.

Метод k-средних (K-Means)
Самый известный и широко применяемый алгоритм кластеризации. Его задача — разбить множество объектов на заданное количество групп так, чтобы объекты внутри одной группы были максимально похожи друг на друга, а объекты из разных групп максимально различались.
У него широкие возможности для применения.
- Сегментация клиентов — выделение групп по поведению, доходам, предпочтениям для персонализации маркетинга.
- Категоризация товаров на основе покупательских паттернов.
- Сжатие цветовой палитры изображений.
- Выявление аномалий — если какой-то объект не вписывается ни в один кластер, это повод присмотреться к нему внимательнее.
В реальных проектах метод k-средних часто становится первым шагом: выделили сегменты, проанализировали их профили, а затем для каждого сегмента уже строят отдельные предсказательные модели.
Нейронные сети (Neural Networks)
Вдохновленные работой человеческого мозга, нейросети состоят из узлов (нейронов), которые передают сигналы друг другу. Хорошо справляются с распознаванием сложных шаблонов и зависимостей в информации. Особенно полезны, когда данных много и они неструктурированные, например, изображения или звук.

У нейронных сетей три серьезных ограничения.
- Им нужны огромные объемы размеченных данных. На малых выборках они бесполезны и легко переобучаются.
- Обучение требует мощного железа и времени.
- Объяснимость: нейросеть — это абсолютный черный ящик. Почему она решила, что на снимке опухоль? Почему отказала в кредите? Даже создатели порой не могут этого объяснить.
Нейросети стоит выбирать, когда вы точно знаете, что более простые методы исчерпали себя, а объем сведений и вычислительные мощности позволяют сделать следующий шаг. Например, для распознавания речи, генерации текста, управления автопилотами.
Как выбрать алгоритм машинного обучения
Когда перед вами конкретная задача, последовательный ответ на несколько вопросов сужает круг кандидатов с десятков до двух-трех. Вот пошаговый чек-лист.
- Определите тип задачи.
- Узнайте, есть ли у вас размеченные данные.
- Оцените объем и качество данных.
- Выясните, что важнее: точность или объяснимость.
- Оцените сложность зависимостей в данных.
- Поймите, есть ли ограничения по времени и ресурсам.

Примеры применения алгоритмов машинного обучения в жизни
- Финансы: скоринг и одобрение кредитов
Задача: по анкетным данным решить, одобрить кредит или нет. Это бинарная классификация. Данных много, они табличные, но главное требование — объяснимость.
Банк не может просто сказать заявителю «Алгоритм отказал», нужно обоснование для регулятора и самого клиента. Поэтому выбор падает на логистическую регрессию: она дает не просто ответ «Да/Нет», но и вероятность дефолта с понятными весами каждого фактора. Второй кандидат — дерево решений, если нужно предъявить конкретную цепочку правил. Бустинг дал бы большую точность, но не пройдет по требованию прозрачности. Нейросети здесь избыточны и также неприемлемы по объяснимости.
- Маркетинг: сегментация клиентов
Задача: разбить клиентскую базу на осмысленные группы, чтобы для каждой запустить персонализированные рассылки. Готовых ответов нет — никто заранее не знает, сколько сегментов существует и как они выглядят. Это кластеризация, обучение без учителя. Выбор — K-Means. Он быстро обрабатывает базу, находит группы, а маркетолог уже интерпретирует их: «Охотники за скидками», «Премиум-клиенты», «Спящие». На основе профилей кластеров строятся отдельные стратегии коммуникации.
- Промышленность: предсказание поломок оборудования
Задача: по показаниям датчиков предсказать, выйдет ли станок из строя в ближайшие сутки. Это бинарная классификация, но с нюансом: поломки крайне редки, классы несбалансированы. Данные — временные ряды с сенсоров: вибрация, температура, давление.
Метод опорных векторов здесь может показать себя лучше логистической регрессии, потому что хорошо работает с четкими границами между нормальным и аномальным состоянием даже при малом числе примеров поломок. Нейросети тоже применимы, если данных достаточно и нужно улавливать сложные паттерны во временных рядах.
Заключение
Мы прошли путь от самых основ ML до конкретных алгоритмов и критериев их выбора. Теперь у вас есть не просто список методов, а навигатор: вы знаете, что такое алгоритмы машинного обучения, их виды, что они позволяют решать в бизнесе и, главное, в какой ситуации какой инструмент брать в руки.
Начинайте с простого и интерпретируемого. Усложняйте модель только тогда, когда это дает измеримый прирост. И помните: качественные данные и правильно поставленная задача важнее всего.











