RAG (Retrieval Augmented Generation): как ИИ-ассистенты работают с вашими данными
Бизнес все чаще сталкивается не с нехваткой информации, а с невозможностью быстро использовать данные. Когда сотрудники не могут найти нужный документ, а клиенты получают противоречивые ответы, это напрямую влияет на скорость работы, качество сервиса и прибыль.
Содержание
- Что такое RAG: объяснение простым языком
- Как работает и из каких компонентов состоит технология
- Ключевые преимущества RAG для бизнеса
- В каких областях RAG наиболее эффективен
- Ограничения RAG
- RAG vs Fine-tuning и другие подходы: гид по выбору
- Что дальше
- Итоги и стратегия внедрения: с чего начать ваш проект
- Заключение
RAG (Retrieval Augmented Generation, извлечение информации с последующей генерацией ответа) — это технология, которая дает ИИ доступ к вашим данным и позволяет отвечать точно, актуально и проверяемо. Она превращает разрозненные документы в единый источник знаний, доступный в формате диалога.
Рассказываем, как работает технология, какие выгоды дает бизнесу и в каких сценариях ее внедрение действительно оправдано.

Что такое RAG: объяснение простым языком
Допустим, сотруднику нужно срочно ответить клиенту: действуют ли для него старые условия скидки из договора 2023 года, что прописано в новой редакции регламента по возвратам или как оформить поставку в новый регион. Информация спрятана в десятках папок с PDF, устаревших версиях документов в SharePoint, переписке в почте и обсуждениях в чатах. Чтобы найти истину, приходится тратить полчаса, уточнять у коллег или рисковать и давать неточный ответ.
Обычные AI-модели типа ChatGPT тут бесполезны. Они сформулируют красивый, убедительный ответ, но будут опираться на устаревшие знания или, что хуже, выдумают несуществующий пункт договора. Они просто не знают, какие правила действуют именно в вашей компании в этот момент.
Retrieval Augmented Generation решает эту проблему. Это подход, при котором ИИ работает как связка библиотекаря и аналитика.
- Библиотекарь (Retrieval): мгновенно ищет и извлекает релевантные фрагменты во всей вашей корпоративной базы знаний — договоры, инструкции, презентации, история обращений в CRM.
- Аналитик (Generation): анализирует найденные документы и формулирует четкий, структурированный ответ строго на их основе, добавляя при необходимости контекст и объяснения.
В результате нейросеть отвечает не абстрактно, а прямо цитируя конкретные источники. Например, раздел 5.2 Общих условий поставки от 15.01.2024. Это делает ответ проверяемым и надежным. А если документы обновились, то и ответы ИИ мгновенно меняются, без дорогостоящего переобучения модели и ручных правок.
Если принцип работы RAG вас заинтересовал и вы хотите не просто понимать технологию, а научиться собирать такие системы, записывайтесь на интенсив «RAG-боты и автоматизация LLM». Курс создан для разработчиков, DevOps, аналитиков.
За 2 недели вы погрузитесь в актуальный стек и научитесь:
- Создавать и настраивать RAG-ассистентов для реальных задач.
- Работать с no-code-инструментами (Flowise, Langflow) и low-code-интеграциями.
- Развертывать LLM в корпоративном контуре и создавать ИИ-агентов (например, Telegram-ботов).
Это программа от практика из индустрии: вы получите навыки для сборки прототипов, проверки гипотез и для внедрения ИИ внутри компании.
Как работает и из каких компонентов состоит технология
На уровне пользователя все выглядит просто: человек задает вопрос — ИИ отвечает. Но внутри это не одна модель, а отлаженный конвейер, который превращает разрозненные файлы в точные ответы. Чтобы разобраться, как это работает на практике, разделим процесс на две ключевые фазы:
- подготовку и структурирование данных;
- работу с пользовательским запросом в реальном времени.
Разберем обе фазы по шагам и отдельно остановимся на основных компонентах технологического стека, из которых собирается RAG-система.
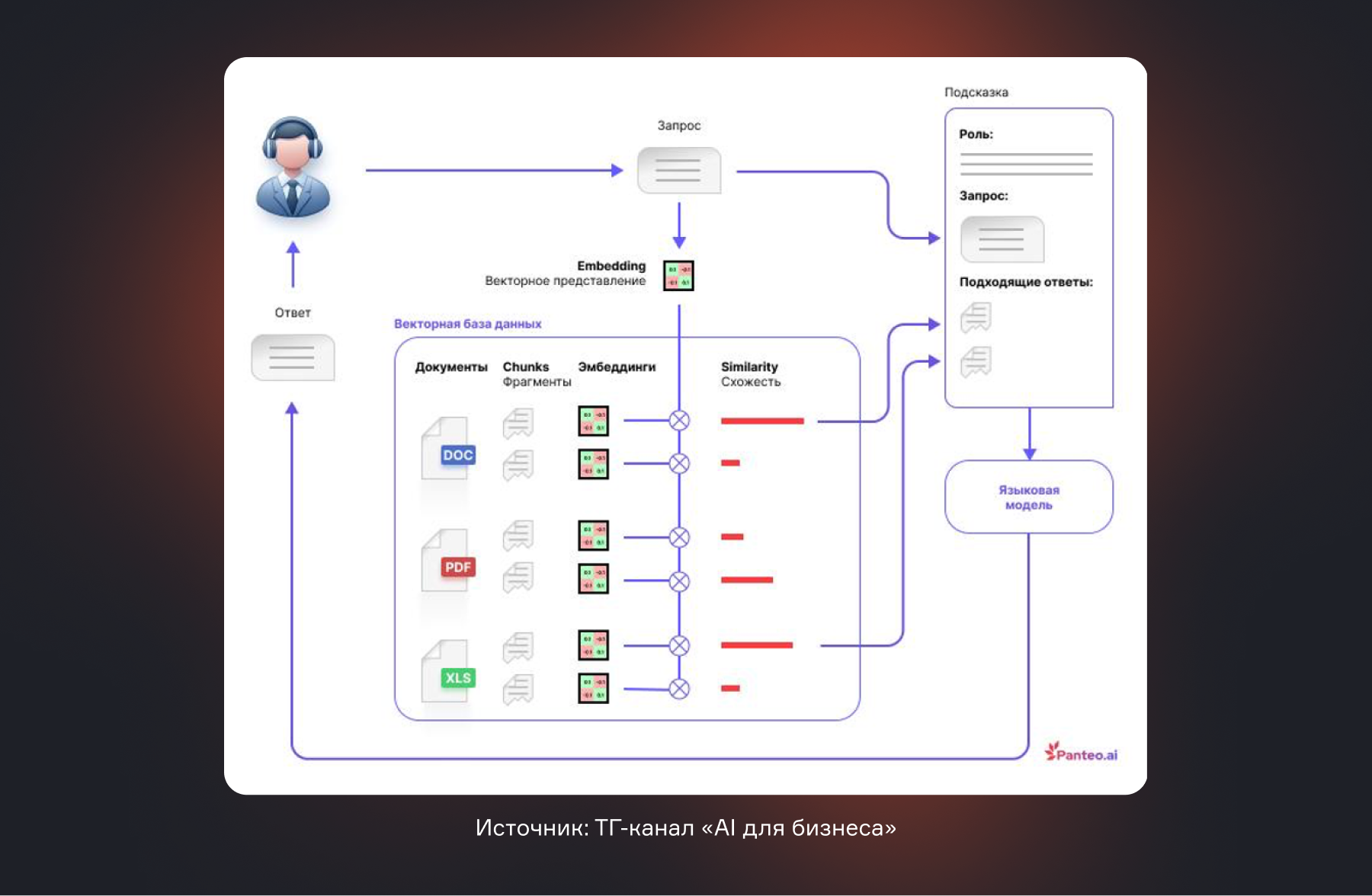
Фаза индексации: готовим базу знаний
Здесь закладывается фундамент для качественных ответов. Если в память загружен мусор или обрывки, даже самый умный ИИ даст сбой. Процесс можно сравнить с систематизацией бумажного архива в идеальную электронную картотеку.
1. Сбор данных
В систему загружаются все источники знаний: PDF-документы (договоры, инструкции), Word-файлы (регламенты), презентации, страницы Wiki, переписка из тикет-систем (например, Jira).
Важно
RAG не требует единого формата — данные могут быть разнородными.
2. Очистка и нормализация
Из документов удаляют служебные элементы, колонтитулы, дубликаты. Текст приводится к единому виду, чтобы модель работала с содержанием, а не с формой.
3. Фрагментация или Чанкинг (от англ. chunk — «кусок, фрагмент»)
Большие документы делят на логические блоки — по абзацам, разделам или смыслу. Это критически важно: RAG ищет не 100-страничный PDF целиком, а конкретный абзац, где описан нужный процесс. Плохая фрагментация — главная причина неточных ответов.
Примеры стратегий чанкинга:
- По разделителям. Документ режется по заголовкам, маркерам списков или знакам конца абзаца.
- Фиксированный размер. Текст делится на блоки, например, по 500 символов с небольшим перекрытием чтобы не разрывать мысль на середине предложения.
- Семантический чанкинг. Более сложные алгоритмы пытаются делить текст по смысловым границам, учитывая завершенность мысли.
4. Векторизация
Каждый текстовый фрагмент с помощью специальной модели (embedding) преобразуется в вектор — уникальный набор чисел, отражающий его смысл. Простая аналогия: это как перевести смысл документа в штрих-код, который понимает ИИ. Благодаря этому поиск идет не по словам («возврат»), а по смыслу («процедура возврата товара клиентом»).
5. Сохранение в векторной БД
Полученные векторы сохраняются в специальное высокоскоростное хранилище — векторную базу данных. Теперь это — оперативная цифровая память компании, готовая к запросам.
Фаза выполнения: от запроса к ответу
Когда сотрудник или клиент задает вопрос, запускается отлаженный процесс, который обычно занимает доли секунды.
1. Обработка запроса
Вопрос «Как оформить возврат для клиента из Казахстана?» превращается в вектор. Это позволяет понять смысл, а не просто найти документы со словами «оформление» и «Казахстан».
2. Семантический поиск
Система ищет в БД фрагменты, чей смысл наиболее близок вектору запроса. Находит не один, а топ-N наиболее релевантных кусков текста. Ключевой принцип: если в базе знаний нет информации по Казахстану, RAG честно скажет «информация не найдена» и не станет ничего выдумывать. Это его главное отличие от галлюцинирующих нейросетей.
3. Формирование контекста
Найденные фрагменты собираются в один контекстный пакет — краткую, но исчерпывающую выжимку из ваших документов, на основе которой модель будет отвечать.
4. Генерация ответа
Большая языковая модель (LLM) получает четкую инструкцию: «Ответь на вопрос пользователя, используя только предоставленный контекст. Не используй свои знания». Она формулирует связный, человеческий ответ, опираясь на переданные ей документы.
5. Возврат ответа
Пользователь получает текст, например: «Для оформления возврата из Казахстана необходимо: 1. Заполнить форму №3 (ссылка на документ)…». В продвинутых системах ответ сопровождается ссылками на исходные документы, чтобы можно было проверить информацию.
Ключевые компоненты стека: векторные БД, модели, фреймворки
Архитектура RAG — конструктор из трех типов компонентов, которые можно гибко выбирать под задачи бизнеса.
Векторная база данных — «сердце» системы, где хранятся и быстро ищутся векторы. Это специализированные базы вроде Pinecone, Weaviate или Qdrant. Выбор конкретной БД для компании зависит от объема данных, скорости и бюджета.
Модели
- Embedding-модель — «переводчик» текста в векторы. От нее зависит, насколько точно система понимает смысл.
- Большая языковая модель (LLM) — «автор» итогового ответа (например, GPT-4, Claude или Llama). От нее зависит ясность и качество формулировок.
Фреймворки (оркестраторы) — «дирижер», который связывает все этапы в единый рабочий процесс. Такие инструменты, как LangChain или LlamaIndex, значительно ускоряют разработку, предоставляя готовые блоки для загрузки данных, поиска и генерации.
Важно
Такая модульная архитектура означает, что решение масштабируется и адаптируется. Можно начать с небольших open-source моделей, а по мере роста требований перейти на более мощные, не переписывая всю систему.
Ключевые преимущества RAG для бизнеса
Это практический инструмент, который напрямую влияет на скорость работы, качество решений и операционные затраты.
Конкретная польза для бизнеса
| Преимущество | На практике | Кто выигрывает и как |
| Мгновенный доступ к знаниям | Ответы на сложные вопросы — за секунды, а не часы поиска по папкам и почте. Так новый менеджер за 10 секунд узнает все условия работы с ключевым клиентом, изучая выжимку из десятков документов. | Все сотрудники. Сокращается онбординг, ускоряется принятие решений, высвобождается до 30% рабочего времени на творческие задачи, а не на поиск информации. |
| Меньше нагрузки на экспертов и поддержку | До 80% типовых запросов (о регламентах, статусах, простых процедурах) закрываются ИИ-ассистентом без участия человека. | Отдел поддержки, юристы, методологи, HR. Они перестают быть справочной, фокусируются на сложных кейсах и развитии процессов, а не на рутине. |
| Актуальность как стандарт | ИИ всегда отвечает только на основе самой последней версии документов. Исправления в инструкции или обновление прайса мгновенно меняют все будущие ответы системы. | Менеджеры и клиенты. Исчезает проблема устаревших данных. Все работают по одной, актуальной версии правды, что критично для качества сервиса. |
| Меньше ошибок и рисков | Ответ привязан к источнику, что исключает галлюцинации. Система не противоречит внутреннему регламенту. | Руководство и риск-менеджеры. Минимизируются юридические, финансовые и репутационные риски, вызванные человеческим фактором или неверной информацией. |
| Масштабируемость без роста издержек | Один RAG-ассистент может одновременно обслуживать сотни сотрудников и тысячи клиентов 24/7. Его производительность не падает, а нагрузка распределяется автоматически. | Бизнес в целом. Позволяет масштабировать сервис и операции без пропорционального увеличения штата поддержки или затрат на обучение. |
Технологические преимущества для разработки
- Без переобучения моделей
Для обновления знаний достаточно обновить данные в базе.
- Модульная архитектура
Можно менять модели, базы данных и фреймворки независимо друг от друга.
- Прозрачность и контроль
Ответы можно связать с конкретными источниками, что важно для аудита и доверия.
- Быстрое внедрение
RAG проще и дешевле запускать в продакшн по сравнению с кастомным обучением моделей.
Главное преимущество перед обычной генерацией
Обычная генерация текста всегда основана на вероятности — модель угадывает лучший ответ. Retrieval Augmented Generation сначала находит факты, а потом формулирует ответ.
Это означает:
- меньше галлюцинаций;
- больше точности;
- возможность проверять и объяснять ответы.
В каких областях RAG наиболее эффективен
Там, где накоплены большие объемы знаний, но доступ к ним остается медленным, разрозненным или завязанным на отдельных экспертов. В таких сценариях технология дает быстрый и измеримый бизнес-эффект.

Корпоративные базы знаний и внутренние ассистенты
Чат-бот работает с регламентами, инструкциями, IT-документацией и политиками компании, отвечая на вопросы сотрудников на основе конкретных источников. Это ускоряет онбординг и снижает нагрузку на внутренние команды поддержки.
Поддержка клиентов и контакт-центры
Модель, дополненная поиском по внутренним данным, отвечает клиентам с опорой на актуальные тарифы, правила и инструкции. В результате снижается количество ошибок, а скорость обслуживания растет без расширения штата.
Юридические и комплаенс-задачи
Поиск по договорам, нормативным документам и внутренним политикам становится диалоговым. Специалисты быстрее находят нужные формулировки и снижают риск неверной трактовки требований.
Продажи и пресейл
Менеджеры получают быстрые и точные ответы о продуктах, условиях и кейсах из внутренней документации, не привлекая экспертов. Это ускоряет сделки и повышает качество коммуникации с клиентами.
Аналитика и работа с отчетами
Retrieval Augmented Generation позволяет задавать вопросы к отчетам, исследованиям и презентациям на естественном языке, извлекая нужные факты без ручного просмотра документов.
Во всех этих сценариях технология выполняет одну ключевую функцию — превращает корпоративные документы из пассивного архива в активный источник знаний, доступный бизнесу в любой момент.
Ограничения RAG
Технология отлично решает задачу доступа к знаниям, но не заменяет экспертизу и не исправляет проблемы с качеством данных. Ее эффективность начинается не с модели, а с порядка в информации.
Возможности
- Дает доступ к актуальной информации без переобучения модели.
- Снижает количество галлюцинаций за счет опоры на реальные документы.
- Позволяет масштабировать доступ к знаниям без роста нагрузки на экспертов.
- Делает ответы проверяемыми и привязанными к источникам.
Ограничения
- Качество ответов напрямую зависит от качества данных. Неактуальные, плохо структурированные или противоречивые документы приводят к таким же ответам.
- Система не понимает информацию глубже, чем она представлена в источниках. Если знания не зафиксированы в документах, бот их не придумает.
- Требует поддержки инфраструктуры: хранилища данных, индексации, контроля обновлений.
- Может давать неполные ответы, если поиск вернул нерелевантный или недостаточный контекст.
Где вообще не подходит
Технология плохо работает с задачами без стабильной базы знаний: креатив, стратегическое мышление, прогнозирование без данных. В этих случаях модель по-прежнему остается инструментом генерации, а не источником фактов.
RAG vs Fine-tuning и другие подходы: гид по выбору
При внедрении ИИ для работы с корпоративными данными бизнес обычно выбирает между несколькими подходами. Ниже сравниваем их по основным параметрам.
| Подход | Что это | Когда подходит | Плюсы | Ограничения |
| Retrieval Augmented Generation (генерация, дополненная поиском) | Модель ищет информацию в базе знаний и формирует ответ на ее основе | Внутренние ассистенты, поддержка, юристы, продажи, базы знаний | Актуальные данные, меньше ошибок, не требует переобучения, быстрые обновления | Зависит от качества документов и поиска |
| Fine-tuning (дообучение готовой LLM) | Модель дообучается на данных компании | Узкие, повторяющиеся задачи с устойчивыми формулировками | Консистентный стиль ответов, меньше контекста | Дорого, долго, знания «зашиваются» в модель, сложно обновлять |
| Классический поиск | Поиск по ключевым словам | Когда нужен точный документ, а не ответ | Прозрачность, простота | Нет объяснений, не очень удобно пользователям |
| Чистая генерация (LLM без данных) | Ответы на основе общего обучения | Идеи, тексты, креатив | Быстро, универсально | Не знает данных компании, высокий риск галлюцинаций |
Как выбрать?
- Если нужна работа с актуальными документами и проверяемыми ответами — выбирают RAG.
- Если задача узкая и почти не меняется — возможен fine-tuning.
- Если требуется просто найти файл — достаточно поиска.
- Если данные не критичны — подойдет обычная генерация.
Часто наилучший результат дает комбинация подходов: RAG обеспечивает доступ к актуальным данным, а слегка дообученная (fine-tuned) модель — идеально подгоняет итоговый ответ под корпоративный стиль.
Что дальше
Технология быстро развивается и выходит за рамки «поиска + генерации». В ближайшие годы она станет основой корпоративных ИИ-систем, где важны точность, контроль и соответствие требованиям безопасности.
От простого поиска к умным системам
RAG постепенно превращается из вспомогательного слоя в центральную архитектуру. Вместо одного способа поиска используются гибридные подходы: сочетание смыслового поиска, классических алгоритмов и дополнительной фильтрации результатов. Это повышает точность ответов и снижает количество ошибок.
Больше автономности и логики
Новые реализации используют агентный подход: ИИ может сам уточнять запрос, задавать дополнительные вопросы системе и поэтапно собирать ответ. В сложных случаях это позволяет работать не с отдельными документами, а с логикой процессов и связями между данными.
Работа со связанными знаниями
Все чаще используются графы знаний — структуры, где данные связаны между собой. Такой подход помогает отвечать на сложные вопросы, требующие понимания контекста и взаимосвязей, а не поиска одного фрагмента текста.
Фокус на безопасность
Появляются решения с встроенной защитой данных, контролем доступа, маскированием персональной информации и возможностью развертывания в закрытом контуре. Это критично для финансов, промышленности, медицины и госсектора.
Выход за пределы текста
Следующий шаг — мультимодальные системы, которые работают не только с текстом, но и с изображениями, видео и другими форматами. Это открывает новые сценарии: от анализа документов с графиками до работы с техническими схемами и инструкциями.
Итоги и стратегия внедрения: с чего начать ваш проект
1. Определите конкретную задачу
Лучше всего начинать с одного сценария: внутренняя база знаний, поддержка клиентов, юридические документы или продажи. Универсальные ассистенты для всего почти всегда дают слабый результат.
2. Проведите аудит данных
Проверьте, где хранятся документы, насколько они актуальны и структурированы. RAG усиливает данные, но не исправляет хаос.
3. Запустите пилот
Небольшой MVP позволяет проверить гипотезу, качество ответов и реакцию пользователей без больших инвестиций.
4. Настройте обновление и контроль
Важно сразу продумать процессы обновления данных, контроля источников и ограничений доступа. Это основа доверия к системе.
5. Масштабируйте постепенно
После успешного пилота можно расширять набор данных, сценарии и аудиторию, не меняя базовую архитектуру.
Главная стратегия — рассматривать Retrieval Augmented Aeneration как инфраструктуру знаний, а не как разовую ИИ-функцию. Такой подход позволяет внедрять технологию предсказуемо, безопасно и с понятной бизнес-ценностью.
Хотите избежать ошибок на старте и увидеть реальные кейсы? Посмотрите запись нашего вебинара «Прототипирование LLM: как создаются AI-ассистенты для реальных задач». Здесь дают экспертные ответы на вопросы, которые неизбежно возникают при первых шагах в мире корпоративного ИИ.
Заключение
Новые технологии меняют сам подход к использованию ИИ в бизнесе. Речь уже не об умных чатах и экспериментах с генерацией текста, а о системах, которые работают с реальными данными компании и дают проверяемые, актуальные ответы. Компании, которые раньше упирались в хаос документов и зависимость от отдельных экспертов, получают управляемый слой знаний поверх всех процессов.
Если вы работаете с информацией, принимаете решения на основе документов или масштабируете экспертизу внутри компании, изучение RAG — это инвестиция в эффективность и устойчивость. Чем раньше бизнес начинает выстраивать такую архитектуру знаний, тем проще ему адаптироваться к следующему этапу развития корпоративного ИИ.
