Градиентный бустинг — что это такое, как работает метод
Иногда, чтобы сделать что-то хорошо, нужно сделать это не с первого раза. Представьте, что пишете сочинение. Первый черновик не идеален: где-то нет логики, где-то не до конца раскрыта мысль. Вы перечитываете, исправляете слабые места. Опять читаете и снова правите. Так же работает градиентный бустинг — метод, который строит модель не сразу, а постепенно улучшает её.
Содержание
Определение
Допустим, вы хотите научить прототип предсказывать, сколько стоит квартира по заданным параметрам — площадь, этаж, район, год постройки. Один алгоритм пробует и выдает результат: «Эта квартира стоит семь миллионов». Но в реальности она стоит восемь. Значит, ошибка — миллион.
Тогда появляется второй алгоритм и говорит: «Хорошо, я попытаюсь угадать, сколько недосчитали». Он вставляет уточнение: «Добавь пятьсот тысяч». Итоговое предсказание — 7.5 миллионов. Уже ближе к реальности.
Третий попытается скорректировать, где был неправ второй, и так далее. Каждый следующий как будто говорит: «Дай-ка я поправлю, где ошиблись до меня».
Градиентный бустинг (англ. gradient boosting) — это метод машинного обучения, который помогает создавать точную сложную модель, объединяя множество простых. Обычно в этой роли выступают простые деревья решений.
Название связано с тем, что каждый следующий алгоритм в цепочке старается уменьшить ошибки предыдущих. Он работает в направлении, которое подсказывает градиент. А градиент в математике — это вектор, показывающий, куда и насколько сильно нужно сдвинуться, чтобы значение функции (в нашем случае — ошибка) уменьшалось как можно быстрее.
Для чего нужен
Допустим, интернет-магазин хочет предсказать, купит ли человек товар, когда зайдёт на сайт. Есть множество факторов: откуда пришёл пользователь, сколько времени проводит на странице, что смотрел до этого. Простая модель может ошибаться — ведь поведение людей непредсказуемо. Но градиентный бустинг анализирует все эти данные шаг за шагом, улучшая прогнозы на каждом этапе, пока не начнет угадывать с довольно высокой точностью.

Метод хорошо справляется с двумя основными типами задач:
- Классификация — когда нужно понять, к какому классу относится объект. Например, нажмет ли пользователь на рекламу, спам это письмо или нет, одобрить заявку на кредит или отказать.
- Регрессия — когда нужно предсказать число. Например, сколько заказов сделает клиент, сколько будет стоить квартира, какая будет погода завтра.
Градиентный бустинг деревьев решений — мощный инструмент машинного обучения, который активно используют в разных сферах: от банков и онлайн-магазинов до медицины и промышленных компаний. Он помогает делать точные прогнозы, находить скрытые зависимости в данных и принимать решения автоматически — без участия человека.
Если хотите разобраться, как работают такие модели и как применять их на практике, присмотритесь к курсу «Инженер машинного обучения». Это возможность освоить Machine Learning с нуля, на реальных задачах. Чтобы поступить, достаточно базовых знаний математики: уравнения, функции, векторы — всё, что проходили в школе.
Ансамбли, бэггинг и бустинг
Герой нашей статьи относится к семейству ансамблевых методов. Суть проста: алгоритм не полагается на одну модель, а использует сразу несколько и объединяет их усилия. Давайте разберемся, как это устроено.
Ансамбль
Так называют сочетание нескольких конфигураций, которые работают вместе над одной задачей. Идея похожа на коллективное принятие решений: если разные люди независимо отвечают на вопрос, их общий ответ часто оказывается точнее, чем у любого из них по отдельности. В машинном обучении то же самое: объединение моделей помогает уменьшить ошибки и повысить надёжность.
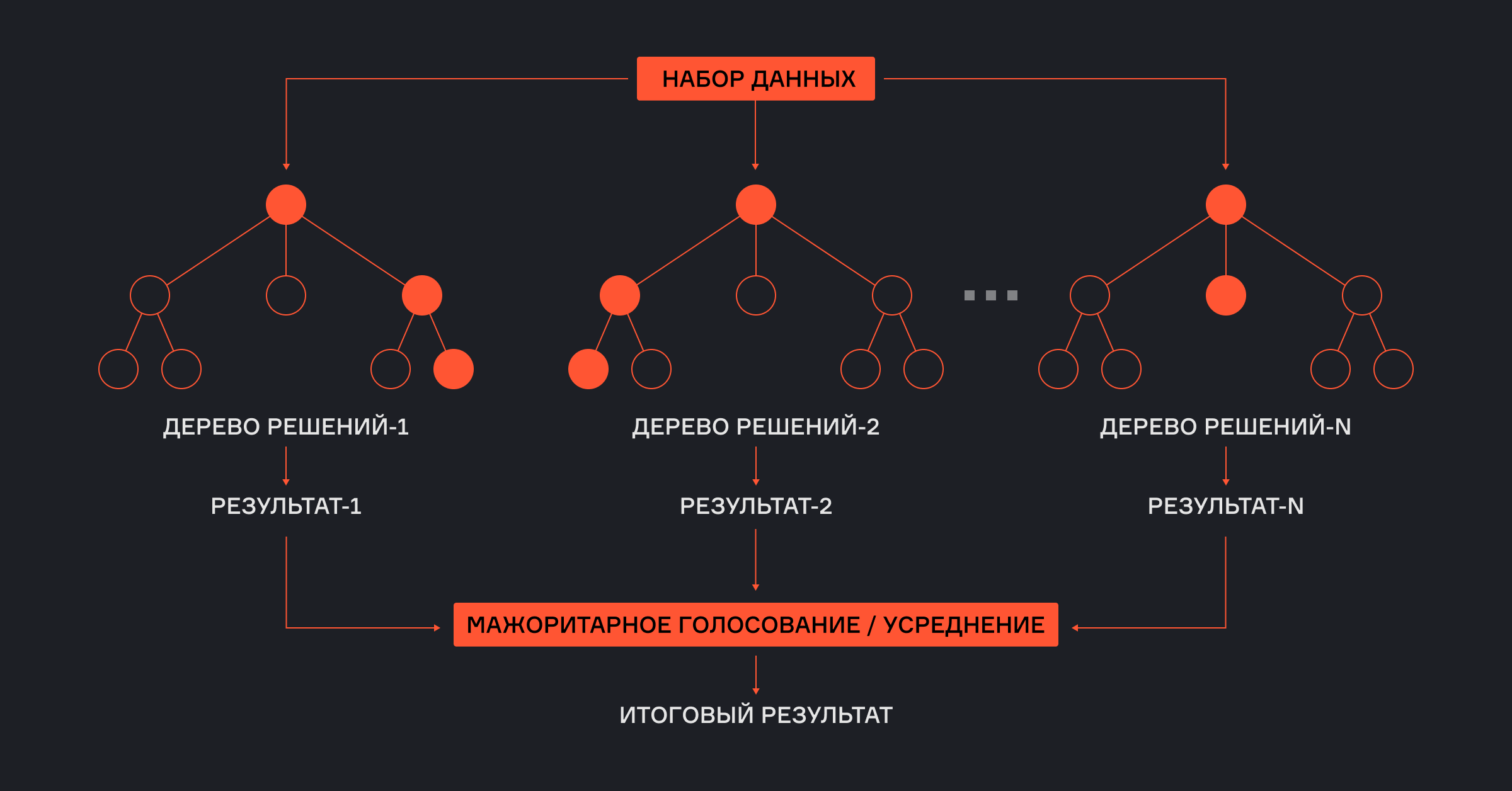
Бэггинг
Идет от английского bootstrap aggregating. Это способ, при котором несколько моделей обучаются параллельно на разных выборках из одних и тех же данных. Выборки получаются случайным образом: с повторами, как если бы мы каждый раз вытаскивали шарики из мешка, записывали их и клали обратно. Затем предсказания всех моделей объединяются. Например, берется среднее значение или проводится голосование.
Хороший пример бэггинга — метод Random Forest (случайный лес), в котором множество деревьев решений «голосуют» за итоговый ответ. Такой подход помогает снизить риск переобучения и делает системы более устойчивой.
Бустинг
Другой способ построения ансамбля, более последовательный. Вместо того чтобы обучать модели одновременно, мы делаем это по очереди. Сначала создается первая простая конфигурация. Затем смотрим, где она ошиблась, и обучаем следующую — так, чтобы она справилась именно с тем, что не удалось первой. Потом — третью, и так далее. В итоге каждая новая модель дополняет предыдущие и вместе они образуют сильную команду.
Gradient boosting — это и есть пошаговый бустинг, где направление для улучшений задает градиент ошибки. Именно благодаря такой последовательной настройке модели удается добиться высокой точности.
Отличия обычного метода от градиентного
Представьте, что предсказываете, сколько человек сделают заказ в интернет-магазине. Первая модель ошибается: одному клиенту она предсказала три покупки, а он сделал пять, другому — две, а он не купил ничего.
- В обычном бустинге следующий алгоритм просто сосредоточится на этих ошибках, переоценивая важность примеров, где промах был сильным.
- В градиентном — следующая модель посмотрит на разницу между реальностью и предсказанием. Изучит конкретные величины ошибок (например, +2 и —2) и построит прогноз так, чтобы как можно точнее подкорректировать предыдущее приближение.
Алгоритм последовательного улучшения планомерно двигается к более точному решению, шаг за шагом уменьшая общую ошибку.
Алгоритм градиентного бустинга
Главная задача любой обучающей модели — сделать так, чтобы её предсказания были как можно ближе к реальным данным. Для этого используется функция потерь — например, среднеквадратичная ошибка (MSE). Она показывает, насколько сильно наши прогнозы отличаются от настоящих значений.
Градиентный бустинг основан на идее градиентного спуска — шага по направлению, где ошибка уменьшается быстрее всего. На каждом шаге алгоритм обновляет предсказания, учитывая скорость обучения (learning rate), чтобы постепенно снижать неточности.
Проще говоря, мы постепенно подгоняем модель так, чтобы сумма отклонений от реальных значений стремилась к нулю.
Логика метода
Если вы знакомы с линейной регрессией (Linear regression), то знаете: она старается подобрать такую прямую, чтобы разница между предсказанными и настоящими значениями — отклонения — была минимальной и распределялась случайно вокруг нуля. Это значит, что модель не систематически ошибается в одну и ту же сторону.
Теперь перенесем эту идею в градиентный бустинг. Допустим, мы построили простую модель — например, решающее дерево. Она предсказывает не идеально, и в её ошибках можно найти закономерности — те самые отклонения. Алгоритм анализирует, где именно модель промахнулась, и строит следующую, которая старается исправить эти промахи, как если бы она училась на недочетах первой.
Так выглядит работа градиентного бустинга над решающими деревьями (gradient boosted trees). Вместо одной большой сложной модели мы получаем ансамбль из множества небольших деревьев, которые вместе дают точный результат.
Этот процесс продолжается, пока ошибки не перестают иметь структуру — становятся случайными, как в идеальной линейной регрессии. Это сигнал, что модель больше не может улучшиться и пора остановиться. Иначе есть риск переобучения.
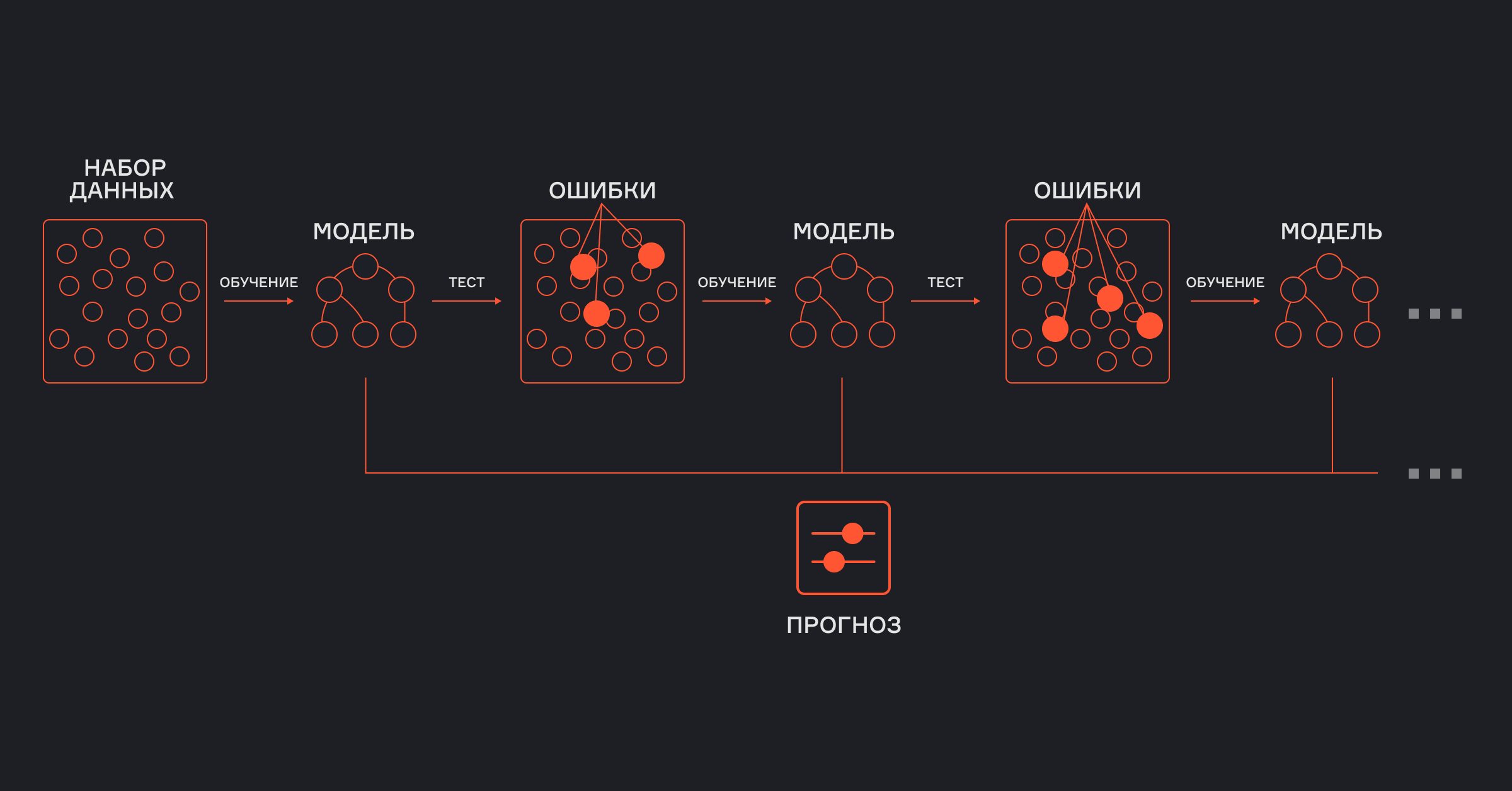
Шаги построения модели
На каждом этапе создается новая конфигурация, которая учится исправлять ошибки предыдущих. Так постепенно улучшается точность предсказаний. Ниже — подробное описание каждого процесса.
Шаг 1
Сначала алгоритм строит базовую модель — чаще всего это дерево решений. Оно делает первые приближенные предсказания. Неточности на этом этапе ещё существенные.
Шаг 2
Затем алгоритм вычисляет, насколько далеки предсказания от реальных значений — это и есть функция потерь. Именно по ней определяем, насколько плохо сработала первая конфигурация.
Шаг 3
Считаем, в каком направлении нужно двигаться, чтобы как можно быстрее уменьшить ошибку.
Шаг 4
На основе градиента строим вторую модель, которая учится на ошибках первой. Она не работает с нуля, а корректирует то, что не получилось в прошлый раз.
Шаг 5
Объединяем алгоритмы. Если первый промахнулся на 2, а второй подсказывает, как сдвинуть предсказание на 1, то итог будет уже ближе к цели.
Повторяем процесс, пока результат не станет достаточно точным или пока не достигнуто заданное число итераций.
В этом видео вместе с аналитиком-разработчиком Григорием Будорагиным разобрали, как алгоритм обучается на данных и прогнозирует числовые величины на примере цен домов.
Почему выбирают этот метод
- Высокая точность: эффективно минимизирует ошибки, комбинируя слабые модели.
- Гибкость: подходит для разных задач. Градиентный бустинг особенно хорош для классификации и регрессии.
- Обработка сложных зависимостей: точно улавливает нелинейные связи в данных.
- Устойчивость к шуму: фокус на исправлении ошибок снижает влияние выбросов.
- Настройка параметров: позволяет тонко настраивать модель (learning rate, глубина деревьев).

Современные библиотеки Gradient Boosting

Сегодня не нужно писать код вручную — достаточно воспользоваться готовыми решениями. Вот самые известные:
- XGBoost
Классика индустрии. Быстрая и мощная библиотека, лидер в соревнованиях на Kaggle. Оптимизирована для больших данных, поддерживает параллелизм и регуляризацию.
- LightGBM
Разработана Microsoft. Быстрая, экономит память благодаря гистограммному подходу. Идеальна для больших табличных датасетов.
- CatBoost
Библиотека от «Яндекса». Главное преимущество — сама умеет обрабатывать категориальные признаки. Можно использовать сразу, без сложной настройки или подготовки данных.
- Scikit-learn
Универсальная библиотека Python для ML. Включает GradientBoostingClassifier и GradientBoostingRegressor. Проста в использовании, подходит для экспериментов и небольших проектов, но менее производительна для Big Data.
Подведем итоги
Мы объяснили простыми словами, что такое градиентный бустинг в машинном обучении, как работает этот метод. Его сила — в последовательных улучшениях. Благодаря такому подходу, даже простые модели становятся частью мощного способа, который способен решать сложные задачи с высокой точностью.
Вопрос-ответ
Как указанный метод справляется с переобучением?
Для этого ограничивают глубину деревьев, снижают скорость learning rate, вводят регуляризацию и рано останавливают обучение, если качество на валидации перестаёт расти. Так модель учится постепенно и не подгоняется под шум в данных.
Как градиентный бустинг обрабатывает пропущенные значения в данных?
Сам по себе этот метод не умеет работать с этим — всё зависит от конкретной реализации. CatBoost и LightGBM могут автоматически обрабатывать пропуски: они определяют, в какую ветку дерева стоит отправить пустое значение, чтобы улучшить качество. А вот в XGBoost нужно заранее заполнить их вручную. Например, средним значением или медианой.
Какие модели используются в градиентном бустинге?
- Решающие деревья — основной и наиболее эффективный выбор.
- Линейные модели — теоретически возможно, но редко используется.
- Нейронные сети — редко, но возможно.
На практике почти всегда используют деревья решений, так как они хорошо работают с разными типами данных и легко поддаются улучшению шаг за шагом.



