Что должен знать и уметь инженер данных — и как освоить профессию с нуля
Многие восхищаются аналитиками и ML-инженерами. Графики у них красивые, модели умные, прогнозы как из будущего. Но все это было бы невозможно без фундамента, который подготовил инженер данных — надежной инфраструктуры и чистых данных, подготовленных к работе. Рассказываем, что нужно знать для работы в Data Engineering и как готовят таких специалистов в karpov.courses.
Содержание
Чем занимается Data Engineer
Без дата-инженера нет данных, а без данных — аналитики. Он как архитектор и строитель в одном лице. Проектирует инфраструктуру так, чтобы к данным всегда был быстрый и комфортный доступ.
В обязанности инженера данных входит:
- Строить хранилища данных, в которых они лежат по полочкам
- Настраивать потоки данных — чтобы все приходило куда надо и не терялось
- Собирать, очищать и готовить данные к работе
- Создавать и внедрять эффективные инструменты для работы аналитиков и ML-инженеров
- Автоматизировать рутинные процессы: скрипты, пайплайны, алерты
- Оптимизировать процессы так, чтобы работа с данными происходила дешевле и быстрее
Подробнее о задачах инженера данных рассказали основатель дата-консалтинга LEFT JOIN Николай Валиотти и CEO karpov.courses Анатолий Карпов — советуем посмотреть.
Что должен знать и уметь инженер данных
У вас должно быть системное понимание того, как устроена инфраструктура данных, как строятся пайплайны, где возникают узкие места, как их устранять.
DWH — хранилища данных
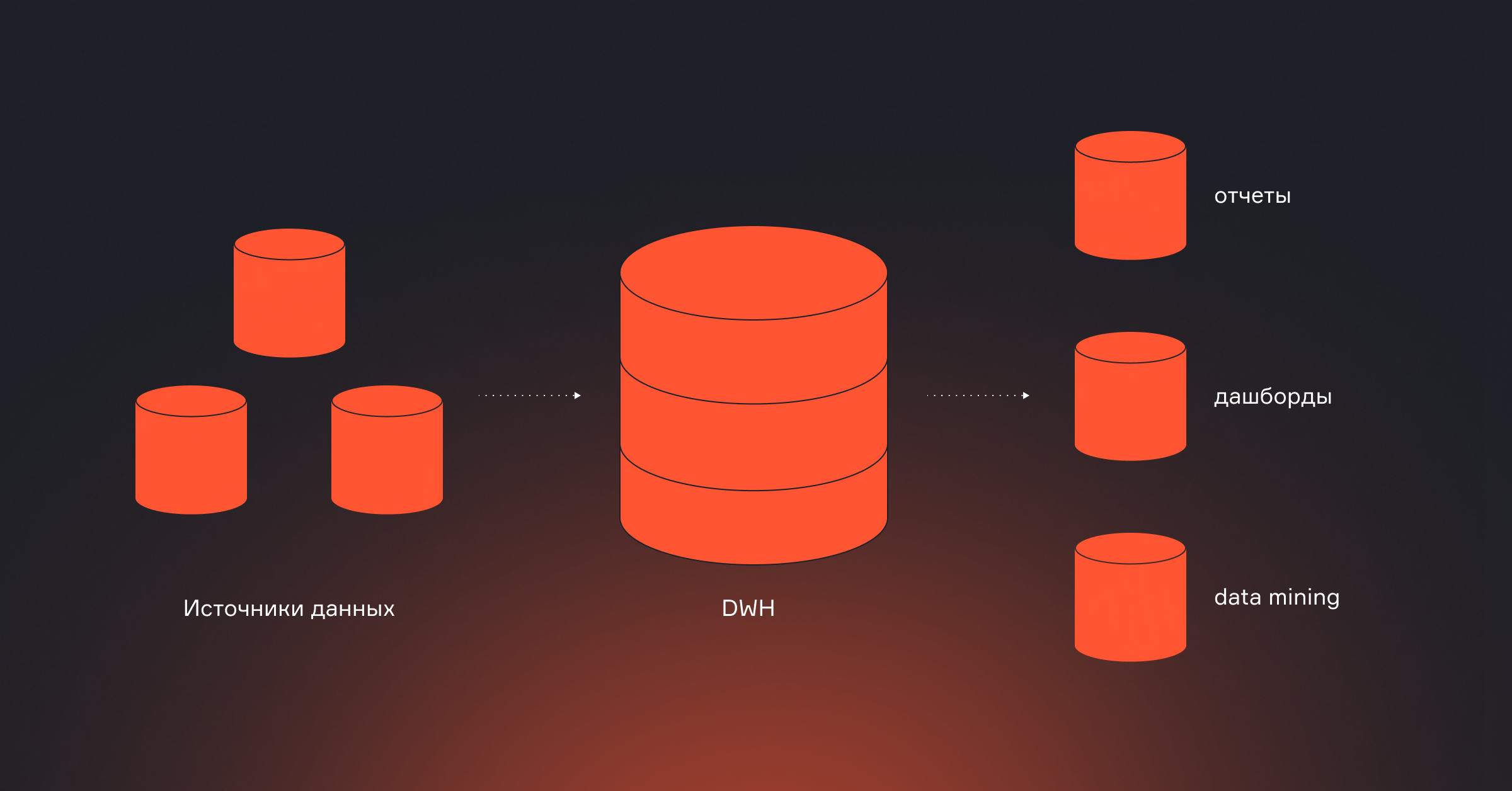
Хранилище данных — это ядро data-инфраструктуры. Здесь данные из разных источников собираются, агрегируются, трансформируются и хранятся в удобной форме для аналитиков, ML-инженеров и BI-систем.
Что должен уметь инженер:
- Понимать разницу между операционными базами (OLTP) и аналитическими хранилищами (OLAP)
- Проектировать схему хранилища: звезда, снежинка, Data Vault
- Настраивать слои хранилища: Raw → Staging → Core → Mart
- Работать с партиционированием и кластеризацией данных
- Обеспечивать версионирование и отслеживание изменений (SCD, CDC)
- Прогнозировать нагрузку: как изменится хранилище через 3–6 месяцев
| Почему это важно Если хранилище спроектировано плохо — аналитики получают медленные отчеты, пайплайны регулярно падают, а каждая доработка проходит мучительно. |
Уровень владения навыками зависит от грейда.
Например, на курсе «Инженер данных с нуля», где мы готовим джунов, студенты учатся основам программирования на Python, SQL, основам баз данных на примере PostgreSQL и Clickhouse.
На программе «Инженер данных», где учатся студенты с опытом, идет работа с продвинутыми концепциями: строят архитектуру с учетом бизнес-требований, внедряют Data Vault и контролируют качество данных.
Системы управления базами данных
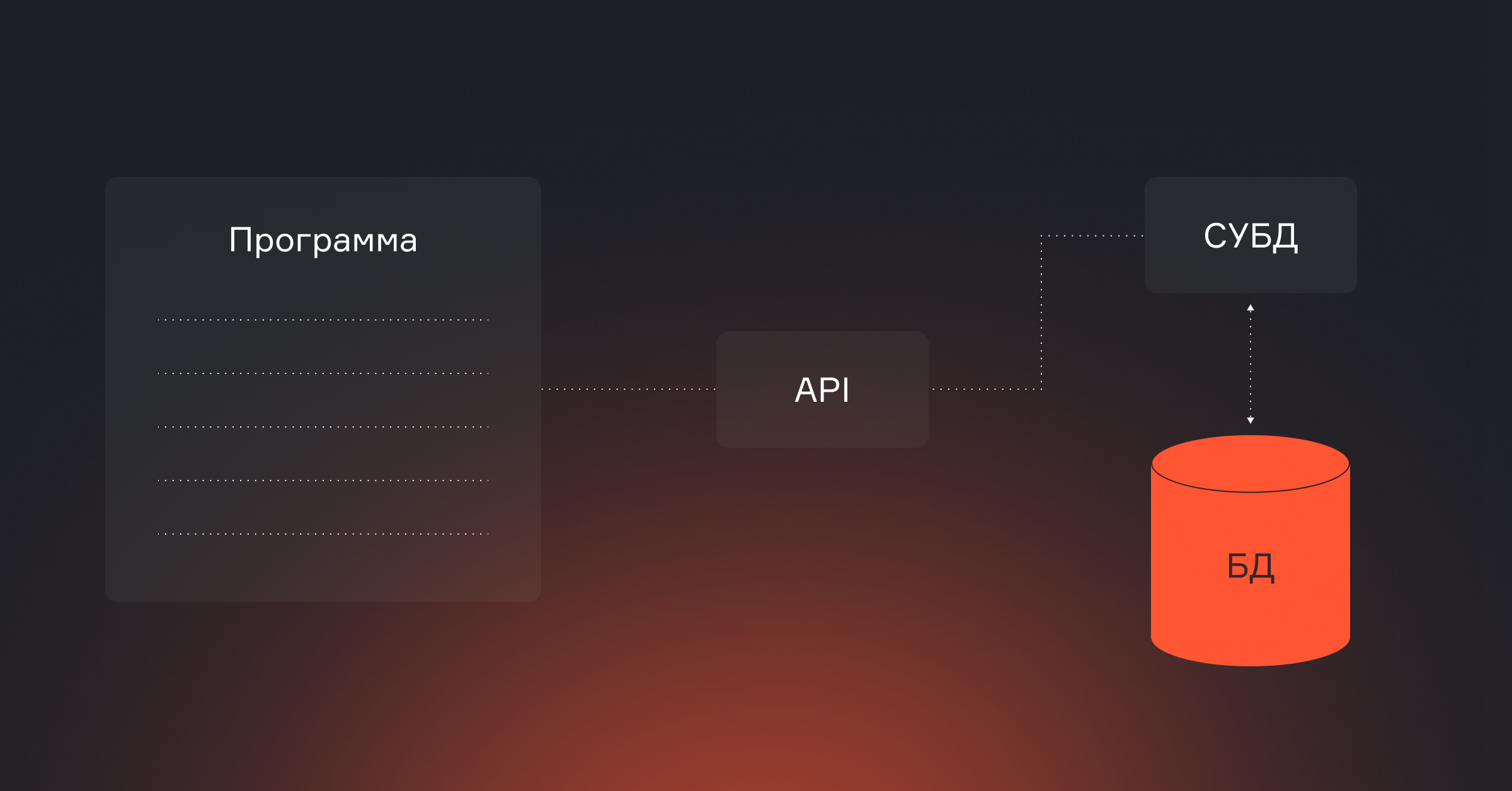
Чтобы проектировать устойчивые хранилища и оптимизировать пайплайны, инженер данных должен понимать, как устроены базы под капотом. Важно уметь:
- Писать SQL-запросы с подзапросами, оконными функциями, CTE
- Оптимизировать их с помощью EXPLAIN, индексов, join-стратегий
- Работать с транзакциями, уровнями изоляции, блокировками
- Знать, как устроены реляционные СУБД (PostgreSQL, MySQL) и MPP-системы (Greenplum, ClickHouse, Redshift, BigQuery)
- Понимать, как масштабируются MPP-системы: распределенные join’ы, шардирование, репликация
| Почему это важно Дата-инженер просто строит пайплайны — он отвечает за скорость, устойчивость и масштабируемость всей инфраструктуры. Ошибки на уровне СУБД могут замедлить отчеты, перегрузить систему или привести к потере данных. |
На курсе «Инженер данных с нуля» можно освоить базу: PostgreSQL и ClickHouse, научиться писать эффективные SQL-запросы и разбирать EXPLAIN.
А на курсе «Инженер данных» добавляются продвинутые инструменты, вроде Greenplum. Здесь вы научитесь проектировать схемы под большие нагрузки, строить архитектуру с учетом масштабирования и обеспечивать прод-стабильность.
Автоматизация ETL-процессов
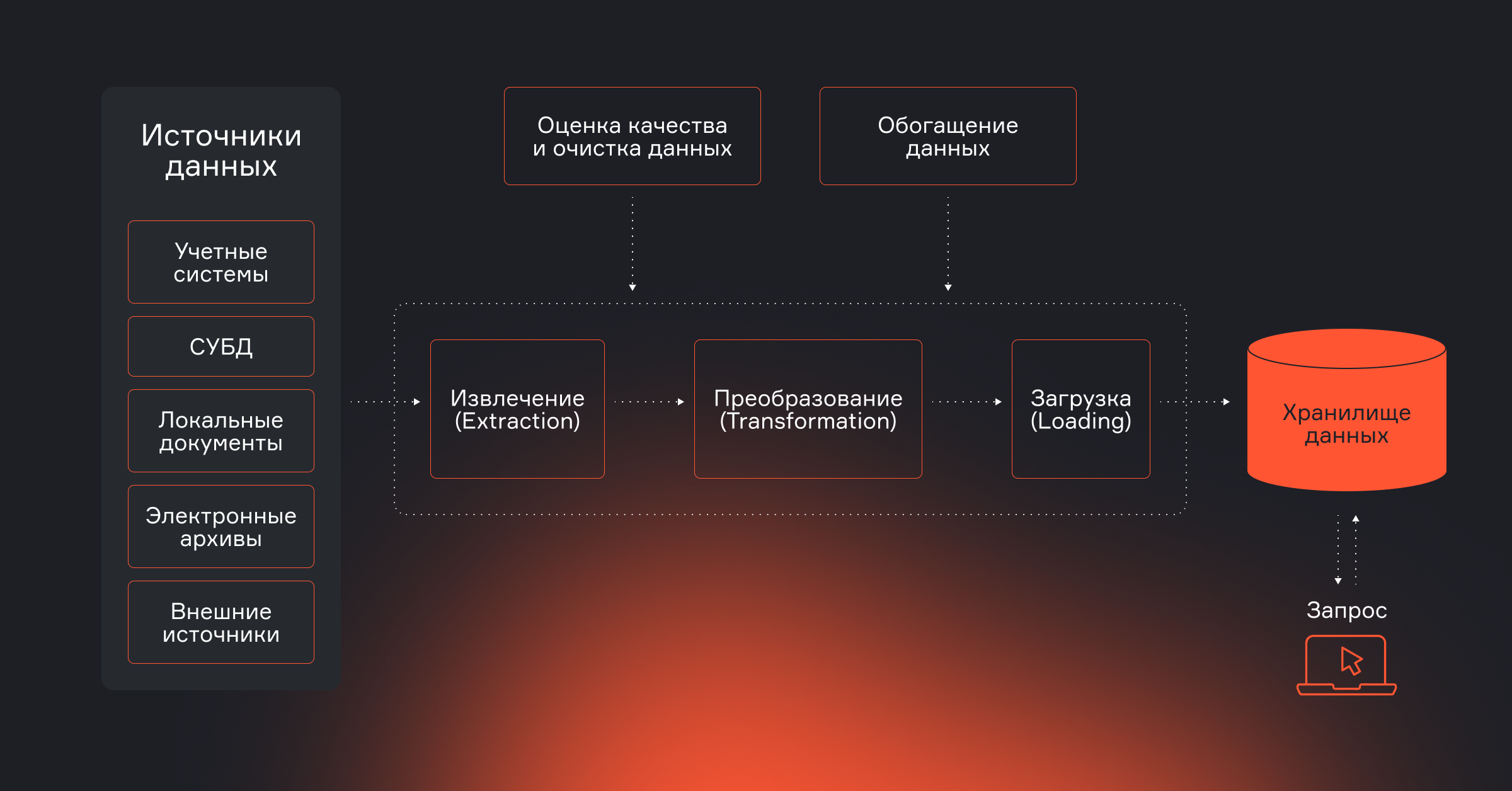
Пайплайны — сердце Data Engineering. Именно через них данные из разных источников попадают в хранилище, очищаются, трансформируются и становятся пригодными для анализа. Если делать все вручную, высок риск сбоев, потерь и задержек. В продакшене так нельзя: процессы должны быть автоматизированы, прозрачны и устойчивы к сбоям.
Дата-инженер должен уметь:
- Настраивать ETL-процессы от и до: подключать источники, обрабатывать, загружать в хранилище
- Работать с Airflow: строить DAG’и, настраивать зависимости, ретраи, алерты
- Писать Python-скрипты для обработки, трансформаций, валидации
- Использовать dbt для декларативных SQL-трансформаций
- Обеспечивать логгирование, мониторинг, тесты — чтобы пайплайны внезапно не падали
- Работать с внешними источниками: API, FTP, S3, Kafka
- Использовать шаблоны и конфиги — чтобы код был переиспользуемым и масштабируемым
| Почему это важно Если ETL-процессы не автоматизировать — данные приходят с задержками, ошибки незаметны, а инженер постоянно тратит время на ручные перезапуски. Автоматизация и масштабируемость обеспечивают стабильную работу и быстрый доступ к данным для бизнеса. |
На курсе для новичков вы шаг за шагом соберете первые рабочие пайплайны с Airflow и Python, научитесь работать со Spark, подключать реальные источники данных — освоите все, чтобы уверенно стартовать в профессии.
На продвинутом курсе — выйдете на новый уровень: научитесь строить масштабируемые продакшн-пайплайны с CI/CD, мониторингом и автоматическими тестами.
Какие еще навыки нужны в работе
В зависимости от компании и специализации инженер данных может брать на себя дополнительные задачи: помогать ML-команде, работать с Big Data, готовить дашборды, управлять метаданными. Эти навыки не обязательны на старте, но делают инженера сильнее и заметнее на рынке, ускоряют карьерный рост.
Big Data
Когда данных становится слишком много для обработки на одном сервере, в игру вступают распределенные системы — Hadoop, Kafka. Их используют, если нужно обрабатывать события в реальном времени, обогащать потоки, строить витрины или агрегаты по миллиардам строк.
Что должен уметь инженер:
- Работать со Spark: писать пайплайны, выбирать стратегии партиционирования
- Понимать архитектуру Kafka, уметь читать и писать события
- Настраивать распределенную обработку: кластер, ресурсы, шардирование
- Оценивать, когда Big Data-решения действительно нужны
| Почему это важно Вместе с бизнесом растет и нагрузка на инфраструктуру. Переход на Big Data — способ масштабироваться без потери скорости и устойчивости. |
На курсе «Инженер данных» студенты собирают продвинутые пайплайны со Spark и Kafka, учатся обрабатывать большие объемы данных и настраивать отказоустойчивость.
Облачное хранилище
Большинство компаний работают в облаке — Amazon, Google, Яндекс. Поэтому дата-инженеру нужно уметь:
- Работать с облачными СУБД: BigQuery, Redshift, Yandex DataLens
- Настраивать хранилища: S3, Google Cloud Storage
- Управлять доступами, конфигурациями, billing
- Понимать ограничения и возможности облачной архитектуры
В продвинутом курсе по инженерии данных вы на практике освоите работу с BigQuery и Redshift, научитесь разворачивать пайплайны в облаке, контролировать стоимость запросов и масштабировать решения без потери стабильности.
Визуализация данных
Инженер не обязан делать красивые графики. Но ему полезно уметь делать черновую визуализацию, чтобы убедиться, что данные корректны и готовы к передаче. Иногда — и собрать BI-дашборд под конкретную задачу. Пригодятся навыки:
- Строить быстрые графики с помощью Pandas, Matplotlib, Seaborn
- Использовать BI-инструменты: Tableau, Power BI, DataLens
- Подготавливать данные в формате, удобном для визуализации
- Настраивать права доступа и обновление дашбордов
Big ML
В некоторых командах Data Engineer помогает ML-инженерам: готовит данные, подключает модели, настраивает автоматизацию. Для этого важно:
- Разбираться в структуре ML-задач и требованиях к данным
- Участвовать в построении feature store
- Готовить датасеты с учетом особенностей ML: outliers, leakage, балансировка
- Работать с MLflow и аналогами
- Понимать, как проходит обучение и инференс моделей
Управление моделями
За моделями нужно следить, обновлять, логировать. Инженер данных может взять на себя эти задачи, если в команде нет MLOps-специалиста:
- Настраивать пайплайны для обучения и инференса
- Выполнять мониторинг моделей: метрики, отклонения
- Подключать retraining при ухудшении качества
- Обеспечивать воспроизводимость моделей
На курсе «Инженер данных» вы узнаете, как работать в ML-команде и какие подходы важны для устойчивости моделей в продакшене.
Управление данными
Чем больше данных, тем выше риск потерять важную информацию и остаться в хаосе. Для порядка нужны четкие процессы. Для этого инженеру нужно уметь:
- Настраивать тесты данных и отслеживать отклонения
- Документировать источники, витрины, пайплайны
- Управлять правами доступа и шифрованием
- Работать с data lineage и data catalog
Эти темы подробно раскрываются на нашем продвинутом курсе. Вы с самого начала учитесь строить понятную, прозрачную и устойчивую инфраструктуру, где каждый шаг можно отследить и воспроизвести.

Как выбрать курс по Data Engineering

Давайте наглядно сравним курсы «Инженер данных с нуля» и «Инженер данных».
| Название курса | Инженер данных с нуля | Инженер данных |
| Для кого | Для новичков без опыта или с базовыми знаниями в SQL и Python | Для джунов и middle-инженеров, специалистов смежных направлений |
| Сколько длится | 6 месяцев | 5 месяцев |
| Какие инструменты рассматривает | PostgreSQL, ClickHouse, Airflow, dbt, работа с реальными источниками данных | PostgreSQL, ClickHouse, Airflow, dbt, работа с реальными источниками данных, BigQuery, Redshift, Greenplum, Spark, Kafka, облачные хранилища |
| Что с практикой | 230 практических задач, 7 проектов по реальным бизнес-кейсам | Промежуточный практический проект, который воссоздает etl-процессы (airflow) крупной двухуровневой платформы данных |
| Результат обучения | Освоите профессию инженера данных за 6 месяцев и сможете пройти первое собеседование | Сможете вырасти в грейде: выбирать инструменты под любые задачи и охватить архитектуру DWH целиком |
Если хочется больше деталей, посмотрите видеоролик от хедлайнера курса «Инженер данных». Евгений Ермаков рассказал, чему мы учим и какие знания нужны на старте.
Резюме: как стать дата-инженером
- Освойте базу. Начните с SQL — научитесь писать сложные запросы, использовать оконные функции, оптимизировать джоины. Освойте Python — для парсинга, трансформаций, API-запросов и быстрой автоматизации.
- Постройте первые пайплайны. Изучите Airflow: DAG-и, расписания, сенсоры, кастомные операторы. Разберитесь с dbt — это must-have инструмент для управления SQL-трансформациями, тестов и документации.
- Погрузитесь в архитектуру и стриминг. Освойте Spark: построение распределенных пайплайнов, партиционирование и кэширование. Добавьте Kafka — для потоковой передачи событий и построения real-time витрин.
- Узнайте, как масштабировать СУБД (PostgreSQL, ClickHouse, BigQuery). Изучите, как проектировать надежные пайплайны, строить мониторинг, обрабатывать сбои и настраивать CI/CD.
- Уделяйте время практике. Соберите проекты, которые можно показать на собеседованиях: пайплайны, витрины, feature store, документацию.
- Подготовьтесь к собеседованиям. Практикуйтесь в SQL- и Python-задачах. Научитесь презентовать себя.
Все шаги — реальные и достижимые. Можно изучать все самостоятельно: по статьям и видеороликам в интернете. А можно — пройти путь быстрее и комфортнее в karpov.courses: получить нужную теорию, поддержку менторов и практику на реальных задачах.
