Большая языковая модель (LLM): что это такое, принцип работы и применение
Из статьи вы узнаете, как большие языковые модели LLM устроены изнутри, в каких бизнес-задачах дают максимальный эффект и что нужно, чтобы начать их использовать — со знанием программирования или без.
Содержание
- LLM что это? Объясняем за 3 минуты
- Принцип работы без сложных терминов
- Какие бывают LLM: модели, примеры и как выбрать
- От чат-ботов до бизнес-анализа
- Как использовать LLM: пошаговое руководство для всех
- Обзор инструментов и сервисов: от ChatGPT до корпоративных платформ
- LLM для разработчиков: Python, библиотеки и практика
- Как создают большие языковые модели с нуля
- Внедрение LLM в бизнес и продукты
- Ограничения, проблемы и риски: что важно знать
- Будущее языковых моделей и тренды 2026-2027
- Заключение и выводы

Материал включает комментарии Ярослава Шуваева, эксперта в области цифровой трансформации и практического внедрения ИИ-решений в бизнес-процессы, автора курса «RAG-боты и автоматизация LLM». Чтобы быть в курсе трендов и новостей из мира AI, подписывайтесь на официальный Telegram-канал Ярослава: @yaroslav_shuvaev.

Я внедряю ИИ в корпоративном секторе более 10 лет, и LLM стали безусловно поворотной точкой для нашей деятельности, позволив внедрять универсальные модели. Наш основной фокус — LLM в закрытом контуре. Это могут позволить себе немногие: в основном крупные компании государственного сектора или с государственным участием.
Наши заказчики — Администрация Президента, региональные Минцифры и Минздрав. Мы также проводили пилотирование решений для «Газпром нефти» и Ак Барс Банка.
LLM что это? Объясняем за 3 минуты
Представьте очень эрудированного человека, который прочитал миллионы книг, статей, диалогов, но не запомнил их дословно. Он запомнил:
- какие слова обычно идут друг за другом;
- как строятся вопросы и ответы;
- как выглядят объяснения, инструкции, шутки, письма.
LLM делает ровно это — угадывает следующее слово, опираясь на контекст.
Наиболее надежные задачи, которые можно доверить LLM без дополнительного контроля, — это проверка текста на ошибки и переводы с языка на язык.
Наиболее маржинальные для бизнеса задачи — генерация программного кода. Самые востребованные в бизнес-применении — извлечение и суммаризация данных из документов, а также смысловой поиск по документам.
Как расшифровывается LLM и чем отличается от ИИ и ChatGPT
LLM (Large Language Model, большая языковая модель) — это конкретная технология, архитектура (чаще всего трансформер), которая является частью искусственного интеллекта.
ИИ (искусственный интеллект) — это широкая область компьютерных наук, в которой разрабатывают системы, способные делать то, что обычно требует человеческого интеллекта: распознавать образы, принимать решения, играть в шахматы и т.д.
ChatGPT — это продукт, удобный чат-интерфейс, построенный на основе конкретной языковой модели (например, GPT-5 от OpenAI).
Если использовать простую аналогию, то ИИ — это концепция транспортного средства. LLM — конкретный тип двигателя, например, электродвигатель. ChatGPT — марка электромобиля, допустим, Tesla, в которой используется этот двигатель.
Что делают большие языковые модели и как понимают контекст
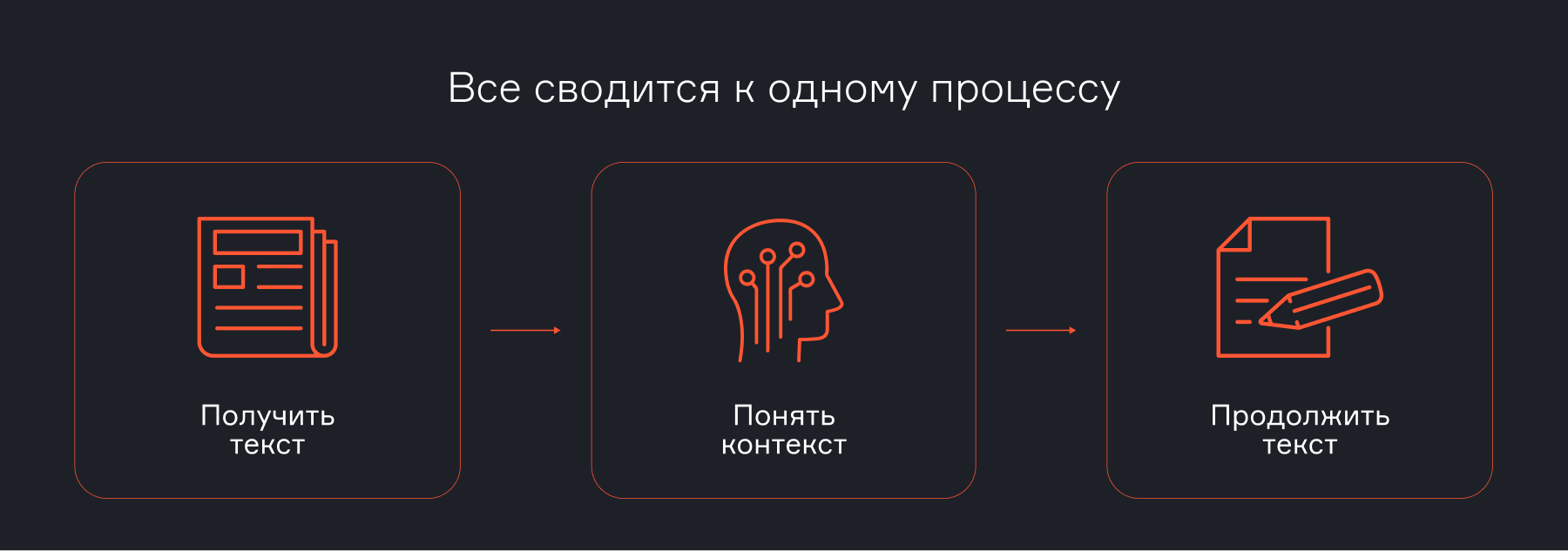
Основная техническая задача LLM — предсказать следующее слово (токен) в последовательности. Все, что делает модель, по сути представляет собой очень сложное и продвинутое автодополнение.
Large Language Model умеет:
- отвечать на вопросы;
- переформулировать и сокращать тексты;
- писать статьи, письма и сценарии;
- объяснять сложные вещи простыми словами;
- поддерживать диалог.
Самое частое заблуждение: LLM галлюцинируют, если их просят ответить на вопрос, на котором они не обучались. Еще два года назад это действительно было объективной реальностью.
Современные модели научились использовать поиск в интернете. Если модель сомневается в ответе, она обращается за «помощью зала»: анализирует поисковую выдачу и возвращается с актуальным и проверяемым ответом.
Внутри организаций LLM могут делать запросы к корпоративной базе знаний и возвращаться с актуальными данными — товарами, ценами, складскими остатками и другой информацией.
Языковая модель не понимает контекст как человек. Она не осознает смысл, а распознает закономерности.
Благодаря архитектуре «трансформер» LLM обрабатывает весь входной текст параллельно на уровне токенов и использует механизм внимания, чтобы учитывать, какие части запроса важнее для ответа. Она опирается не только на последнее сообщение, а на весь диалог, который помещается в ее окно контекста — ограниченный объем текста, доступный модели в один момент времени.
Именно в пределах этого окна модель «помнит» предыдущие реплики и инструкции. Это позволяет ей поддерживать длительную беседу на одну тему и учитывать комментарии пользователя, пока они остаются внутри доступного контекста.
Принцип работы без сложных терминов
Представьте, что учите ребенка языку: показываете предложение, где нужно угадать пропущенное слово. Модель обучается по схожему принципу, но в других масштабах.
1. Обучение (предварительная тренировка)
Модель «читает» гигантские массивы текстов — книги, статьи, код, диалоги. Она не запоминает факты, а вычисляет статистические связи между словами: как часто они встречаются вместе, в какой последовательности, в каких контекстах.
2. Обработка запроса
- Токенизация: ваш текст разбивается на мелкие части — токены. Это могут быть слова, слоги или даже отдельные символы.
- Векторизация: Каждый токен превращается в набор чисел (вектор), который отражает его смысловые связи с другими словами.
- Анализ контекста: модель одновременно анализирует все слова в запросе, определяя их взаимную важность.
3. Генерация ответа
Модель предсказывает самое вероятное следующее слово, основываясь на всех вычисленных вероятностях. Затем добавляет его к запросу и повторяет процесс, пока не сформируется полный ответ.
Важно понимать несколько базовых концепций.
RAG (Retrieval-Augmented Generation, генерация с дополнением поисковой выдачей) — это подход, при котором в запрос к LLM добавляются результаты поиска в интернете или корпоративной базе данных для повышения качества ответа.
Рассуждение (reasoning) — вместо того чтобы сразу выдавать ответ, модель разбивает решение на цепочку шагов и последовательно приходит к финальному результату. Это значительно повышает качество ответов.
Tool Calling — способность большой языковой модели вызывать внешние инструменты. Это критически важно для разработки, так как позволяет создавать агентов, которые взаимодействуют с системами и сервисами.
MCP (Model Context Protocol) — технология, позволяющая подключать новые инструменты к агенту без перепрограммирования самого агента. Таким образом, агент может получать новые возможности в реальном времени и сразу начинать ими пользоваться.
Автономные агенты — одна из самых актуальных тем. Большой языковой модели предоставляется возможность сначала сформировать план действий, затем выполнить его с использованием инструментов, а после проверить соответствие результата цели и при необходимости перепланировать шаги. Это позволяет агентам выполнять длинные цепочки действий и дает наиболее ощутимый эффект, особенно в области программирования.
Какие бывают LLM: модели, примеры и как выбрать
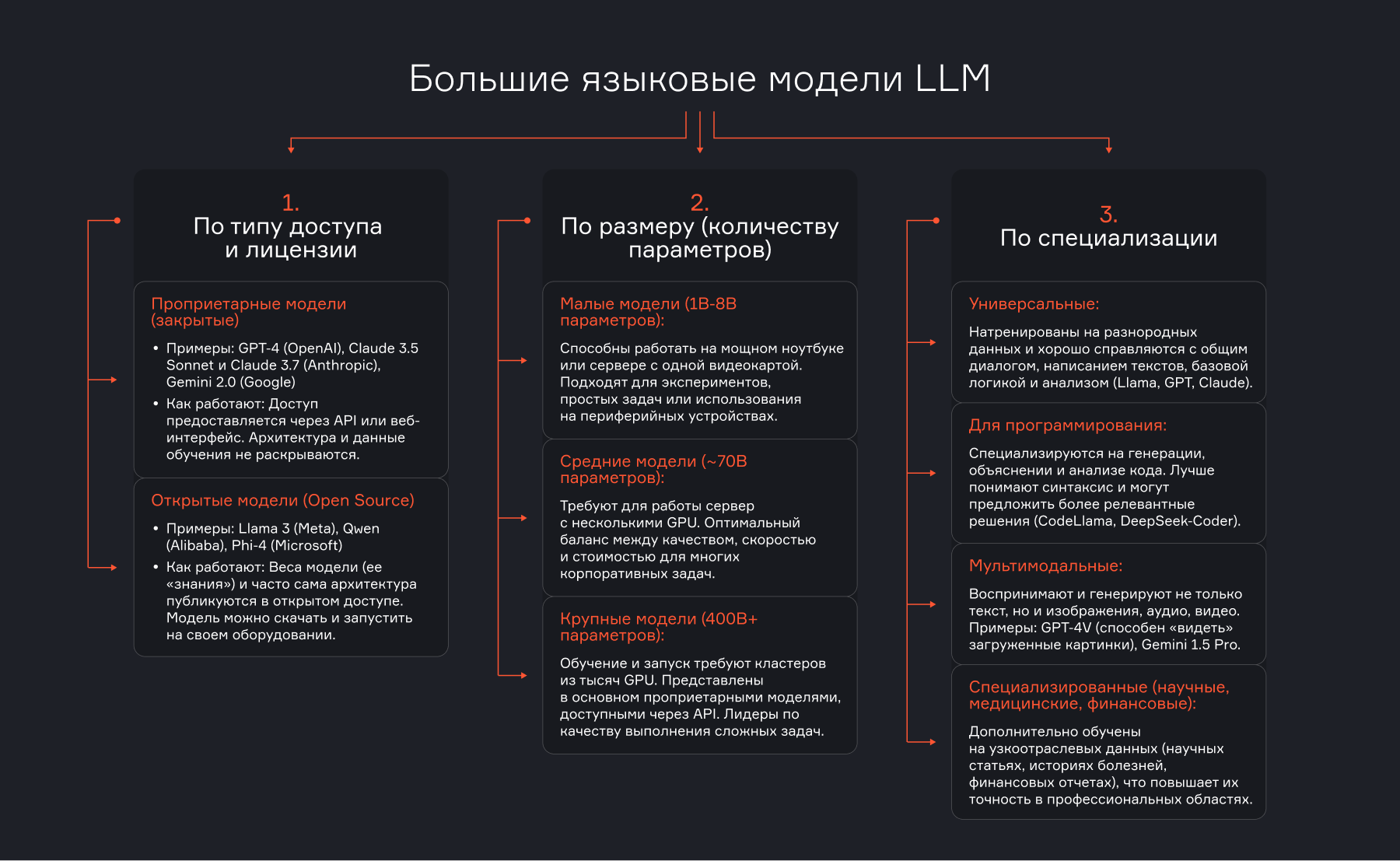
Алгоритм, как выбрать модель
1. Определите приоритет: данные или качество
Если ваши данные конфиденциальны (юридические, медицинские, финансовые документы), выбирайте открытые модели для развертывания внутри вашего контура (on-premise).
Если данные несекретные, начинайте с топовых проприетарных моделей через API (GPT-5, Claude 3).
2. Протестируйте на своих данных
Создайте небольшой набор реальных задач. Например, 10 типичных запросов к документам. Проверьте, как с ними справляются 2-3 кандидата. Измеряйте не только качество, но и скорость, стоимость.
3. Учитывайте экосистему
Нужна ли интеграция с облаком? Есть ли готовые плагины? Это может склонить чашу весов в сторону конкретного вендора.
Главное отличие корпоративных платформ в том, что они разворачиваются локально, в закрытом контуре, часто без внешнего доступа в интернет, и подключаются к внутренним источникам данных.
Как правило, такие платформы используются для поиска по знаниям компании и создания отчетов на основе корпоративных данных. На российском рынке в их основе чаще всего лежат модели с открытым исходным кодом.
От чат-ботов до бизнес-анализа
LLM перешли из стадии технологического чуда в категорию рабочих инструментов. Их применение сегодня дает измеримый бизнес-эффект, автоматизируя рутину и усиливая аналитические возможности команд.
На первом месте для меня — среда разработки Cursor. Я использую ее не только для написания кода, но и для создания инструментов, которые применяю в повседневной работе: систем бронирования встреч, монтажа видео и других решений, закрывающих мои регулярные потребности.
На втором месте — браузер Comet от Perplexity. Применяю его как поисковик и переводчик, а также для работы с сайтами и документами прямо в браузере: заполнения форм, редактирования Google-документов по описанию и выполнения других рутинных задач.
Далее идет ChatGPT, который я использую для обработки больших объемов текста, глубоких исследований и генерации изображений.
Применение в бизнесе
Большие языковые модели используют в бизнесе так:
- Чат-боты и поддержка клиентов — отвечают на вопросы, ведут диалог, сокращают нагрузку на сотрудников.
- Анализ данных — суммируют отчеты, извлекают ключевые идеи, помогают принимать решения быстрее.
- Генерация контента — пишут статьи, посты, маркетинговые тексты и автоматизируют создание документов.
Эти инструменты экономят время, повышают эффективность и ускоряют процессы в компании.
Ситуация на рынке меняется очень быстро: практически каждую неделю обновляется рейтинг самых мощных моделей для текста, графики и видео, появляются новые лидеры. Поэтому сложно однозначно говорить о переоцененных или недооцененных инструментах.
Если говорить про наш рынок, то инструменты Google (Gemini), которые недоступны в регионе без VPN, представляют большой интерес. С одной стороны, они бесплатны, с другой — по качеству уже сравнимы, а иногда и превосходят решения других разработчиков, в том числе в области генерации изображений.
LLM в программировании
В программировании LLM используют для двух ключевых задач:
- Ассистенты для кода — помогают писать функции, исправлять ошибки, объяснять код, предлагать улучшения. Примеры: GitHub Copilot, ChatGPT с кодовым режимом.
- Автоматизация рутинных задач — генерация скриптов, создание шаблонов, автоматизация тестов и документации.
Это ускоряет разработку, снижает количество ошибок и облегчает обучение новым языкам и инструментам.
Как использовать LLM: пошаговое руководство для всех
Внедрение LLM не требует немедленного найма команды специалистов. Это поступательный процесс, который можно начать уже сегодня.
Для того, чтобы написать первый промпт для нейросети, не нужно специальных знаний. Но если вы хотите понимать логику работы AI-ассистентов, создавать полезные инструменты на основе ИИ, интегрировать LLM в IT-инфраструктуру компании, нужно практиковаться. Двухнедельный интенсив «RAG-боты и автоматизация LLM» — это 4 вебинара, на которых вы вместе с Ярославом Шуваевым подготовите универсальную основу для сборки AI-агента.
Как начать использовать языковые модели без навыков программирования
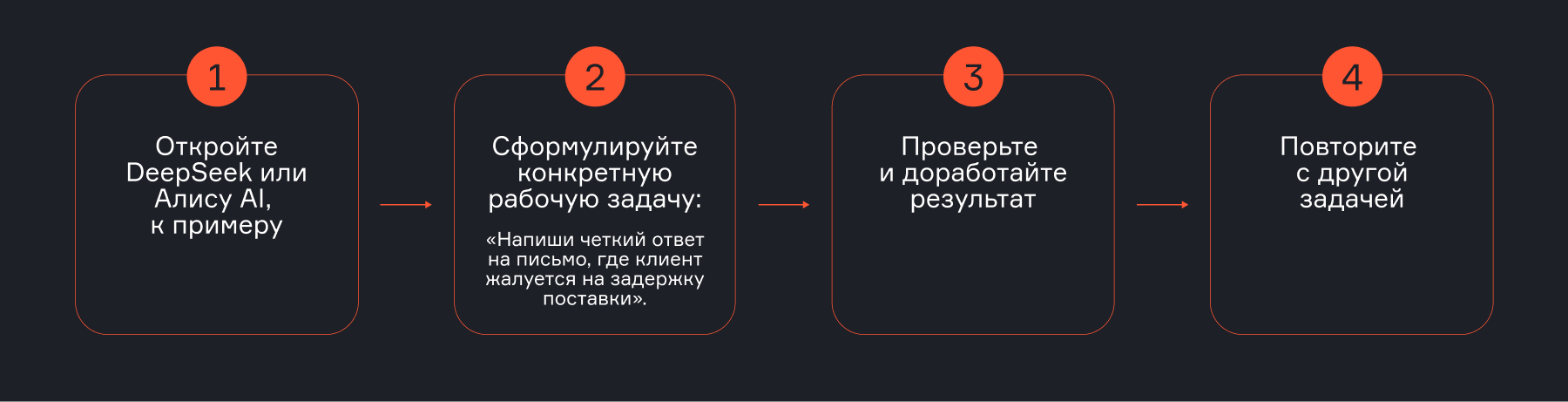
Существует много доступных для нашего рынка моделей, таких как GigaChat, Яндекс GPT, DeepSeek, которые уже сейчас дают прикладную ценность.
На базовом уровне это привычные GPT-ассистенты, с помощью которых можно писать и редактировать тексты, обрабатывать неструктурированные данные, делать переводы, исправлять ошибки и даже генерировать программный код — без глубоких технических знаний.
Следующий шаг — no-code и low-code инструменты для работы с LLM. Существуют облачные решения, такие как Flowise и Langflow, которые позволяют через визуальный интерфейс собирать простейших агентов: настраивать логику диалога, подключать источники данных, использовать RAG, инструменты и цепочки действий — без написания кода или с минимальным его количеством.
Навык написания промтов при этом важен, но не как отдельная дисциплина, а как часть общего понимания того, как формулировать задачи для LLM, как задавать контекст и ограничения. В первую очередь стоит научиться ясно формулировать цель, понимать, какие данные нужны модели, и выбирать подходящий инструмент — от простого ассистента до визуального no-code конструктора.
Обзор инструментов и сервисов: от ChatGPT до корпоративных платформ
В 2025 году рынок инструментов LLM разделился на три ключевых сегмента: публичные чат-боты для повседневного использования, open-source модели для разработчиков и корпоративные платформы (enterprise-решения) с функциями RAG и LLMOps.
Примеры публичных интерфейсов (для старта и личного использования)
- ChatGPT (OpenAI) — флагман рынка с самой мощной моделью GPT-5.
- Claude (Anthropic) — лидер по работе с длинными контекстами и аналитике.
- GigaChat/YandexGPT (Россия) — локальные лидеры с поддержкой русского языка и региональной специфики.
Enterprise-платформы (для бизнеса)
- Microsoft Azure OpenAI Service — лидер рынка, полная интеграция с Azure Cloud.
- AWS Bedrock — доступ к множеству моделей (Anthropic, Meta, Amazon) в инфраструктуре AWS
Open-source модели и фреймворки
- Модели: Llama 3 (Meta), Mixtral (Mistral), Qwen (Alibaba).
- Фреймворки: LangChain, LlamaIndex, Haystack — для построения сложных цепочек с LLM.
- Платформы: Hugging Face, Replicate — для доступа и развертывания.
Существует несколько уровней требований к информационной безопасности, от которых и зависит выбор модели: международные облачные, российские облачные или модели с открытым исходным кодом.
Если при обработке данных с помощью LLM не используются персональные данные, коммерческая тайна или государственная тайна, можно применять общедоступные облачные модели, такие как ChatGPT или Claude. Это лучшее соотношение цены и качества, хотя могут возникать сложности с оплатой зарубежных сервисов.
Если же вы работаете с персональными данными, то в соответствии с законодательством необходимо использовать сервисы, размещенные на территории Российской Федерации, например GigaChat или Яндекс GPT.
Если требования к информационной безопасности не допускают, чтобы данные покидали контур организации, используются модели с открытым исходным кодом, развернутые внутри компании. По этому пути часто идут банки, промышленные корпорации и организации с государственным участием.
LLM для разработчиков: Python, библиотеки и практика
Появление агентов-кодеров снижает потребность в глубоком знании конкретных языков программирования. На первый план выходит умение читать и понимать код.
Знание одного языка и базового синтаксиса уже позволяет с высокой степенью свободы разрабатывать приложения с помощью инструментов vibe-кодинга. Ключевыми становятся базовые концепции современной разработки, включая RAG, Tool Calling, MCP и reasoning, а также понимание инструментов быстрого прототипирования и проверки гипотез.
Сюда относятся no-code и low-code платформы, такие как Langflow, Flowise, n8n и другие.
Универсального стека инструментов для большинства задач нет. Если бы не было специфических потребностей, не существовало бы такого количества языков программирования. Поэтому сложно выделить один универсальный вариант.
Если говорить о продуктах, основанных на LLM, и о разработке с использованием vibe-кодинга, можно выделить несколько ключевых направлений.
Стек Node.js для frontend, back-for-front и backend. Сложившиеся архитектурные паттерны и организация файловой структуры очень удобны для разработки с помощью LLM: агенты-кодеры могут изолированно разрабатывать модули, не ломая остальной код. Кроме того, этот стек обладает богатой экосистемой библиотек и способен решать практически любые задачи.
Python — исторически основной язык для искусственного интеллекта. Он имеет наибольшее количество библиотек для работы с LLM, нативно поддерживает ИИ-задачи и включает инструменты для математики, статистики и обработки данных, что делает его одним из ключевых языков в этом направлении.
Основные библиотеки
Даже минимальные современные приложения используют десятки библиотек с открытым исходным кодом.
Если говорить о продуктах на базе LLM в закрытом контуре, стоит обратить внимание на Ollama. Это комплексная система для работы с локальными моделями: с одной стороны — сервер с API, совместимым с протоколом ChatGPT, с другой — набор библиотек для работы с локально развернутыми моделями из кода.
Также популярны библиотеки LangChain, которые включают стандартные модули для большинства задач: RAG, MCP, Tool Calling и другие. Эти библиотеки совместимы с no-code и low-code инструментами для построения рабочих процессов на базе LLM, такими как Langflow (нативно для Python) и Flowise (стек Node.js).
Как создают большие языковые модели с нуля
1. Формирование датасета (Data Curation)
Собирают гигантские объемы текстовых, кодовых и иногда мультимодальных данных из интернета, книг, статей. Удаляют дубликаты, некачественный контент, токсичные высказывания.
2. Предобработка и токенизация
Тексты очищаются, нормализуются и разбиваются на токены (части слов или целые слова) с помощью специального алгоритма, например, Byte-Pair Encoding — BPE. Создается словарь токенов модели.
3. Выбор и разработка архитектуры
В абсолютном большинстве случаев основой служит архитектура Transformer, благодаря ее механизму внимания (attention), эффективно работающему с контекстом любой длины.
4. Предобучение (Pre-training)
Модель на кластерах из тысяч GPU учится предсказывать маскированные (скрытые) слова в последовательности или следующее слово (задача causal language modeling). Параметры модели корректируются методами оптимизации (например, AdamW) через обратное распространение ошибки и градиентный спуск. Этот этап длится недели или месяцы и требует многомиллионных инвестиций.
5. Выравнивание и тонкая настройка (Alignment & Fine-tuning)
После предобучения модель дообучают (fine-tune) на наборах диалогов и инструкций, чтобы она лучше следовала указаниям человека. Используются методы вроде RLHF (Reinforcement Learning from Human Feedback) или более новые DPO (Direct Preference Optimization).
6. Тестирование и оценка
Качество модели оценивают не только на общепринятых бенчмарках (MMLU, HellaSwag, GSM8K), но и с помощью краудсорсинговой оценки (human eval) по критериям: полезность, фактологическая точность, безопасность, отсутствие предвзятости. На основе результатов возможны дополнительные итерации дообучения.
Внедрение LLM в бизнес и продукты
Большие языковые модели в бизнесе — это инструмент автоматизации, и для оценки эффекта их внедрения давно существуют стандартные метрики.
Чаще всего для B2B-продуктов используют метрику роста продуктивности на одного сотрудника — увеличение количества выполняемых операций. Иногда применяют метрику сокращения штатных единиц за счет автоматизации, но, на мой взгляд, она не является показательной.
Более корректной метрикой я считаю рост прибыли на одного сотрудника после развертывания системы.
Наибольший возврат инвестиций от использования LLM наблюдается в создании программного кода — в первую очередь в разработке программного обеспечения. При этом код может использоваться и для других задач: создания презентаций, обработки и визуализации данных.
Вторая по эффективности область — работа с неструктурированными данными: поиск по документам и извлечение данных из документов.
На третьем месте — виртуальные сотрудники, которые в диалоговом режиме обрабатывают запросы, например в службе поддержки, помогают с продажами и работают с внешними и внутренними пользователями компаний.
Ограничения, проблемы и риски: что важно знать
LLM могут галлюцинировать и иметь определенные смещения, связанные со страной или организацией, на данных которых они обучались. Поэтому в чувствительных сферах, связанных с репутационными и юридическими рисками, LLM следует использовать так, чтобы финальное решение всегда оставалось за человеком, который несет ответственность за результат.
Важно помнить, что даже на первый взгляд безобидные запросы, отправляемые во внешние системы, могут использоваться для так называемых мозаичных атак, когда по фрагментам данных восстанавливается целостная картина.
Этот риск значительно усиливается с развитием искусственного интеллекта, который способен автоматически выявлять такие векторы атак. Поэтому для организаций с повышенными требованиями к информационной безопасности использование публичных облачных сервисов с LLM для интеллектуальной обработки данных зачастую исключено. В таких случаях применяются локально развернутые модели.
Будущее языковых моделей и тренды 2026-2027
К 2026–2027 годам LLM будут компактными, специализированными и энергоэффективными. Основной тренд — уход от гигантских универсальных моделей к Small Language Models для локальных устройств и отраслевых решений. Полная мультимодальность станет стандартом: текст, изображения, аудио и структурированные данные обрабатываются в единой модели, позволяя создавать интерактивные презентации и прототипы.
LLM интегрируются в роботов и IoT для голосового и жестового управления, а персональные модели обеспечат приватность и глубокую персонализацию через локальное обучение. В итоге они эволюционируют в универсальную платформу и «операционную систему» для управления цифровым миром через естественный язык.
Однозначно будет развиваться агентный подход: агенты станут более автономными. Если сейчас за ними нужно регулярно следить, то в будущем это потребуется все реже, а задачи, которые они смогут выполнять, станут более сложными.
Если говорить о самих моделях, наиболее значимым изменением, вероятно, станет появление пластичности нейронов — возможности дообучения в процессе работы. Это откроет широкие перспективы, прежде всего в робототехнике.
В этом видео обсуждаем, как современные агентские системы переходят от хайпа к рабочим практикам.
Заключение и выводы
LLM — это мощный инструмент для работы с текстом и контекстом. Они помогают создавать контент, анализировать данные, автоматизировать задачи и ускорять процессы в бизнесе и программировании. При грамотном использовании модели эффективны, но важно учитывать ограничения и контролировать качество ответов.
Какой совет вы дали бы специалисту, который хочет использовать LLM?
Во-первых, определить требования к информационной безопасности: будет ли система работать в закрытом или открытом контуре, допустимо ли использование зарубежных облачных API или необходимо ограничиться отечественными решениями.
Во-вторых, понять, можно ли использовать no-code и low-code инструменты. Сегодня с их помощью можно решить до 90% задач или как минимум реализовать основную логику backend.
И в-третьих, использовать инструменты vibe-кодинга, такие как Cursor, чтобы быстро реализовать рабочий вариант и запустить продукт.
