Автоматизация аналитических процессов с помощью GitHub Actions: практический гайд
Автор статьи — Алёна Лесихина, аналитик данных, выпускница курса Аналитик данных, автор канала Select * from аналитика. Алёна прошла путь из социологии в аналитику и сейчас много работает с автоматизацией рутинных процессов и пет-проектами. В этой статье она делится практическим опытом использования GitHub Actions — простого и бесплатного способа автоматизировать сбор и анализ данных без серверов и сложной инфраструктуры.
Содержание

Хочу поделиться своей историей того, как я пришла к GitHub Actions в попытках автоматизировать сбор аналитики для личного использования.
Статья будет полезна аналитикам, которые хотят автоматизировать сбор и анализ данных для своих небольших пет‑проектов. Важное слово тут — небольшие, так как у этого способа автоматизации есть конкретные ограничения по суммарному времени отработки скрипта в месяц 🙂
Почему я искала автоматизацию
Возвращаясь в самое начало — у меня была задача: парсить данные и отправлять готовый мини‑отчёт в Telegram‑чат. Сама задача довольно простая, поэтому разбирать в статье скрипты для парсинга и анализа данных я не буду. Основной фокус — на способе автоматизации. При планировании я руководствовалась тремя принципами:
- Не тратить деньги. Никаких платных сервисов и аренды серверов.
- Не запускать вручную. Скрипты должны работать сами по расписанию.
- Простота создания. Без сложной инфраструктуры и администрирования.
Первый вариант — cron
Первое, что приходит на ум — запуск на локальной машине, как пример — классический cron на Linux. Способ рабочий, но есть существенное ограничение: система должна быть включена. Если отчёт нужен каждый день в 7 утра, то и ноут должен быть включён в это время. Это сразу нарушает второй принцип.
Варианты с сервером или облаком
Следующий вариант — поднять сервер или арендовать его. Но для небольшого проекта это слишком: нет желания тратить деньги, а ещё нужно время на настройку. Аналитики обычно не админы, и в такие дебри углубляться не хочется. Да, можно было бы использовать Google Cloud Scheduler, но все файлы у меня уже хранятся в гите, поэтому вариант с использованием нескольких сервисов для проекта выглядит не оптимальным.
Финальный вариант — GitHub Actions
Думаю, что мой выбор сервиса для проекта уже стал очевиден. Я нашла наводку на GitHub Actions во время реализации. Сам github использовала уже давно, но этот функционал ранее использовать не доводилось. Существенных отличий от аналога выше, на самом деле, я не заметила. В моем случае удобно использовать именно actions, так как все репозитории храню в гите. Собственно, actions позволяет запускать скрипты:
- По расписанию (cron).
- По событию (push, pull request, создание релиза и т. д.).
- Вручную.
Для аналитика это возможность настроить:
- ежедневный парсинг данных и сохранение их в репозиторий;
- запуск скриптов для анализа;
- отправку отчётов в Telegram или любую другую систему;
- мелкие задачи для автоматизации своей работы.
Ограничения бесплатного тарифа
Сразу отмечу, что я использовала только free-тариф, так как оплаты противоречат первому требованию проекта. В бесплатный тариф GitHub Free входит ограничение на время и хранилище для приватных репозиториев: 2 000 минут выполнения в месяц и 500 МБ для артефактов (файлы, которые получаются в результате выполнения workflow: логи, csv-файлы и т.п). Для небольших задач этого более чем достаточно. В моём примере за 20 дней было израсходовано всего 133 минуты.
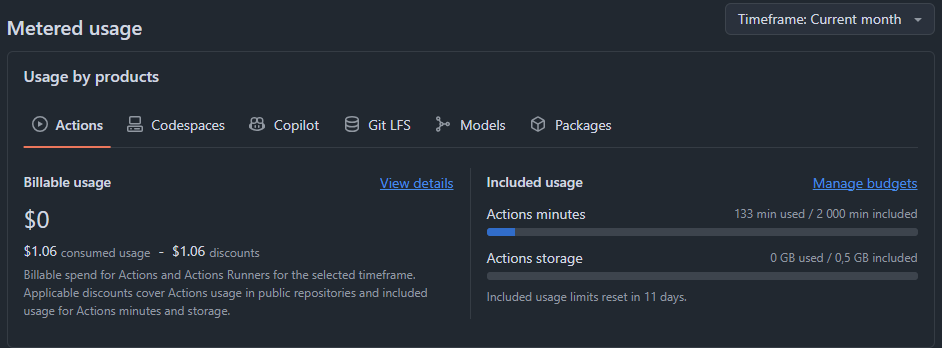
Скрин с моего проекта
Архитектура: как это работает
Весь репозиторий выглядит следующим образом. Ниже разберем подробнее все пункты.
TEST_REPO_FOR_HABR
│
├── .github
│ └── workflows
│ └── run_daily.yml
│
├── .gitignore
├── requirements.txt
├── parser.py
├── delete_old_data.py
├── parsed_data.csv
├── README.md
Пишем скрипт для парсинга/ любой другой цели
В моем примере выше лежит два скрипта на python:
- parser.py для парсинга и отправки данных в тг. Он же создает и обновляет parsed_data.csv
- delete_old_data.py для удаления старых данных старше 3-х месяцев
Создаем репозиторий на GitHub
- Делаем его приватным, если хотим скрыть данные.
- Добавляем директорию .github/workflows/ — здесь будут храниться YAML‑файлы c описанием workflow.
- Внутри папки создаем YAML‑файл, где определяем:
- расписание запуска (cron);
- виртуальную среду (Linux, Windows, macOS);
- последовательность шагов (установка зависимостей, запуск скриптов, коммит файлов и т. п.)
- Добавляем в репозиторий py и csv скрипты, которые указаны в yml-файле.
Пример yml-файла
Ниже показан упрощённый workflow daily.yml, который каждый день в 07:00 UTM запускает скрипт для парсинга, фиксирует изменения в CSV и удаляет устаревшие данные:
# Придумываем название
name: Daily bot
# Устанавливаем расписание
on:
schedule:
— cron: ‘0 7 * * *’
# Возможные дополнения для запуска по push:
push:
branches:
— main
# Глобальные переменные окружения (подтягиваются из Secrets)
env:
BOT_TOKEN: ${{ secrets.tg_token }}
CHANNEL_ID: ${{ secrets.channel }}
jobs:
daily-run:
runs-on: ubuntu-latest # GitHub-hosted runner
steps:
# 1. Выгружаем код репозитория
— name: Checkout Code
uses: actions/checkout@v4
# 2. Устанавливаем зависимости
— name: Install dependencies
run: python -m pip install -r requirements.txt
# 3. Запускаем парсер
— name: Run parser
run: python parser.py
# 4. Коммитим CSV, если он изменился (используем встроенный токен для пушей)
— name: Commit CSV if changed
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
git config user.name «github-actions[bot]»
git config user.email «github-actions[bot]@users.noreply.github.com»
git add parsed_data.csv
git diff —cached —quiet || git commit -m «Update CSV with latest data»
git push
# 5. Запускает скрипт для удаления старых данных
— name: Delete old data
run: python deleting_old_data.py
Ключевые моменты:
- Cron принимает расписание в формате UTC; если вы в другом часовом поясе, учитывайте смещение.
- Секреты (tg_token, channel) хранятся в разделе Settings → Secrets and variables → Actions (про это поговорим ниже);
- Встроенный токен GITHUB_TOKEN позволяет коммитить и пушить изменения без дополнительных настроек.
- При необходимости можно добавить дополнительные шаги — например, очистку временных файлов или отправку уведомлений.
Работа с Secrets
Токены и другие чувствительные данные нельзя хранить в открытом виде. Чтобы их использовать, создаём секреты в репозитории:
- Открываем настройки репозитория: Settings → Secrets and variables → Actions.
- Нажимаем New repository secret, задаём имя (например, TELEGRAM_TOKEN) и значение.
- В workflow обращаемся к нему как ${{ secrets.TELEGRAM_TOKEN }}.
После создания секретов мы сможем их увидеть в настройках, но просмотреть значение — уже никак 🙂
В Python получаем переменные через os.getenv (через функцию, которая позволяет получать переменные окружения). Ниже пример блока с отправкой сообщения в телеграм-чат.
import os, requests
from dotenv import load_dotenv
load_dotenv()
# Предшествующий блок с парсингом и анализом, который не рассматриваем
metrics_text = «Рандомный текст для чата»
bot_token = os.getenv(‘BOT_TOKEN’)
channel_id = os.getenv(‘CHANNEL_ID’)
send_text_url = f’https://api.telegram.org/bot{bot_token}/sendMessage’
payload = {
‘chat_id’: channel_id,
‘text’: metrics_text,
‘parse_mode’: ‘HTML’
}
requests.post(send_text_url, data=payload)
Таким образом можно скрыть все конфиденциальные данные от чужих глаз.
Технические моменты
Не забываем про то, что наш репозиторий содержит .gitignore и requirements.txt.
Чтобы GitHub Actions (и любой другой разработчик) понимал, какие пакеты нужно установить для работы скрипта, принято хранить список зависимостей в файле requirements.txt. Это гарантирует, что при каждом запуске GitHub Actions будут установлены именно те версии библиотек, которые нужны проекту.
Requirements мы устанавливаем через yml-файл в этом блоке:
— name: Install dependencies
run: python -m pip install -r requirements.txt
А сам файл можно создать в терминале следующим образом:
pip freeze > requirements.txt
И, возвращаемся к .gitignore — он определяет файлы, которые игнорируются при обновлении репозитория. Это могут быть временные CSV и кэшированные файлы.
В нашем случае .gitignore включает в себя только три типа данных:
.env
.csv
.yml
Собственно, это вся настройка автоматизации по нашей задаче. Скрипты будут выполняться по расписанию, указанному в yml-файле. Вcе ошибки и проблемы можно просматривать через вкладку Actions → Jobs. Для отладки всегда можно добавить логирование или отслеживать ключевые моменты через print → так ошибки можно просмотреть через actions.
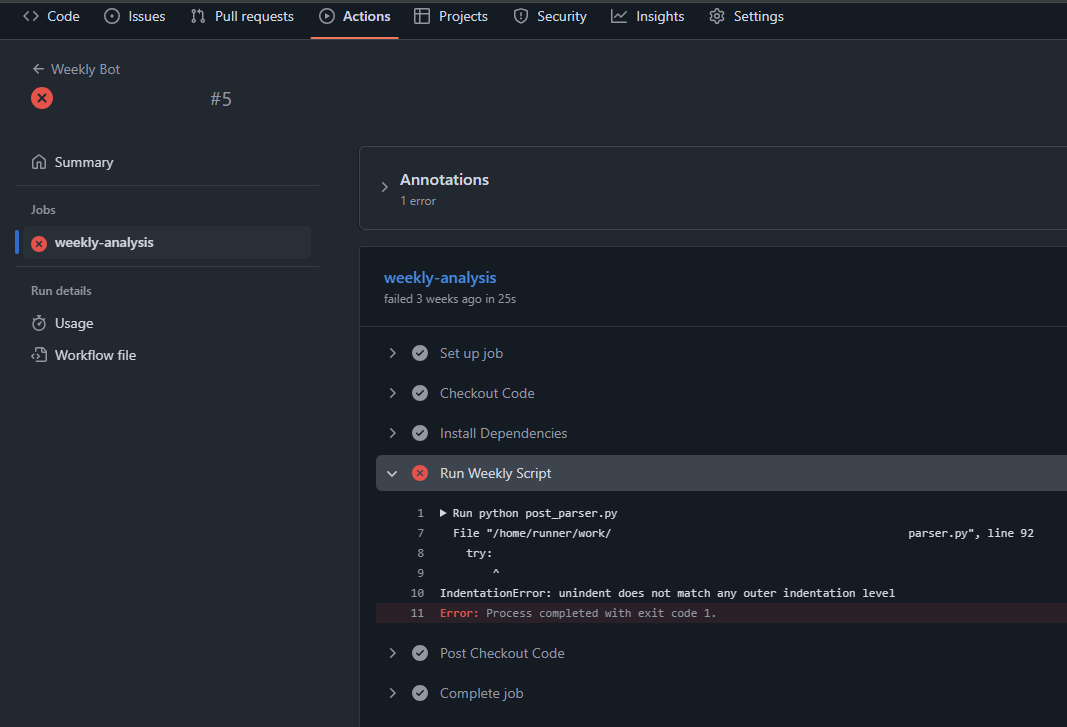
Пример этапов выполнения по задаче
Полезные советы
- Начинайте с самого простого: запустите workflow с одним шагом по cron, чтобы убедиться, что всё работает.
- Все токены и ключи храните только в Secrets.
- Сначала отрабатывайте скрипты локально или в интерактивной среде, чтобы не тратить лимит минут на поиск ошибок.
- Добавь логирование ошибок, если хочешь их отслеживать или выводи через print, если хочешь смотреть их через actions.
- Если в проекте несколько задач, используйте разные jobs или workflows — это позволит параллелить выполнение и не смешивать логику.
- Следите за потреблением минут: использование macOS‑runner’ов расходует в 10 раз больше минут, чем Linux.