Apache Spark для аналитика: как начать обрабатывать терабайты данных
В статье разберем, как начать работать с Apache Spark, решать типовые аналитические задачи и не совершать ошибок, которые замедляют вычисления.
Содержание

Для чего «Спарк» нужен
Объем данных растет постепенно. Сначала увеличивается время выполнения запросов. Затем становится сложнее объединять большие таблицы и строить витрины. В какой-то момент аналитик начинает тратить больше времени на ожидание результатов, чем на их анализ. Это верный признак того, что пора что-то менять.
Точка отказа
Предположим, вам нужно проанализировать поведение пользователей интернет-магазина за последний год. То есть обработать несколько таблиц — события пользователей, заказы, карточки товаров, данные о клиентах. Каждая из них содержит десятки, а то и сотни миллионов записей.
Можно попробовать решить задачу привычным способом, на SQL в корпоративной базе данных. Однако запрос выполняется 40–60 минут, а любое изменение условий — другой временной интервал, дополнительный фильтр, новый показатель — потребует повторного запуска и еще получаса ожидания.
Тогда возникает идея выгрузить данные для дополнительного анализа. Но файл оказывается слишком большим для Excel: приложение либо отказывается его открывать, либо зависает при построении первой же сводной таблицы. Попытка загрузить ту же информацию в pandas на локальном компьютере упирается в нехватку оперативной памяти.
Проблема не обязательно связана с плохо оптимизированным запросом или недостаточно мощным ноутбуком. Когда для расчета метрики требуется регулярно обрабатывать сотни гигабайт или терабайты данных, одного компьютера уже не хватает. Нужен инструмент, который умеет распределять вычисления между несколькими машинами.
Для таких сценариев и применяют Apache Spark. Он позволяет выполнять привычные аналитические операции не на одном сервере, а на кластере, объединяющем десятки и сотни узлов.
Почему аналитику обязательно уметь работать с платформой «Спарк»
Еще пять-семь лет назад считалось, что этот инструмент больше всего нужен дата-инженерам. Аналитику достаточно было знать SQL, Python и какой-нибудь BI-инструмент. Сегодня ситуация изменилась, и на это есть три причины.
- Рост объемов данных
Бизнес научился собирать и хранить информацию практически обо всем: каждый клик пользователя на сайте, каждое событие в мобильном приложении, каждая транзакция, каждый запрос в службу поддержки. То, что раньше удаляли за ненадобностью, теперь сохраняется в сыром виде, на всякий случай. Теперь даже в относительно небольших компаниях объемы сведений измеряются терабайтами.
- Слияние ролей аналитика и дата-инженера
Все чаще специалисту приходится самостоятельно забирать сырые данные из хранилища, очищать их, объединять между собой и только затем строить отчет. Apache Spark становится компромиссом: он дает доступ к терабайтам информации без необходимости осваивать весь стек инженерных технологий.
- Трансформация рынка труда
Работодатели ищут специалистов, способных не просто написать SELECT и GROUP BY, но и понимающих, как выполнить те же операции на массивах, которые не помещаются в память одного сервера. Это уже не конкурентное преимущество, а базовый минимум в сегменте компаний, работающих с большими данными.
Реальные конкурентные преимущества дает онлайн-магистратура «Аналитика больших данных». Программа создана совместно с НИУ ВШЭ, поэтому сочетает в себе академическую экспертизу с актуальностью знаний в гибком формате. Студенты получают индивидуальную траекторию обучения с фокусом на практику. Предусмотрены налоговый вычет, отсрочка от армии и образовательный кредит под 3% годовых.
Что такое Apache Spark на самом деле
Разные статьи называют Spark фреймворком, платформой для обработки информации, вычислительной системой и даже базой данных. Последнее в корне неверно.
БД предназначена прежде всего для хранения и предоставления доступа к сведениям. «Спарк» ничего не хранит самостоятельно. Обычно он работает с данными, которые уже находятся в хранилищах: базах, файлах форматов Parquet, CSV и JSON, объектах в облаке.
Разбираемся в терминологии
Apache Spark — это распределенный вычислительный движок. Он может прочитать данные из внешнего источника, обработать в оперативной памяти и вернуть результат: обратно в хранилище, в файл или в виде таблицы для дальнейшего анализа.
Термины «фреймворк» и «платформа» тоже применимы, но в разных контекстах.
Фреймворк — программная основа, потому что Spark предоставляет готовый набор библиотек и API для построения сценариев обработки информации: Spark SQL для структурированных запросов, MLlib для машинного обучения, Structured Streaming для потоковой обработки.
Платформа — потому что вокруг движка сформировалась экосистема инструментов, позволяющих решать сквозные аналитические задачи от загрузки сырых данных до построения отчетов.
Как работает Spark: от кода на Python до выполнения на десятках серверов
- Драйвер и исполнители
Когда вы запускаете Spark-приложение, включаются два типа процессов. Драйвер управляет приложением: создает SparkContext/SparkSession, формирует логический и физический планы (через DAGScheduler и TaskScheduler), запрашивает ресурсы у менеджера кластера (YARN/Kubernetes/Standalone/Mesos) и отправляет задачи исполнителям. Исполнители (executors) — процессы, запущенные на узлах кластера; каждый содержит набор слотов (cores) и выполняет задачи, хранит кешируемые данные (cache/persist) и пишет/читает промежуточные файлы перетасовки.
- Ленивые вычисления
Трансформации в Apache Spark (например, map, filter, select или join) выполняются не сразу после вызова. Вместо этого система запоминает последовательность операций и строит план обработки данных. Такой подход называется ленивыми вычислениями.
Реальное выполнение начинается только после вызова действия (action), например count(), collect(), save() или take(). К этому моменту Spark анализирует всю цепочку операций, оптимизирует ее и преобразует в граф выполнения задач (DAG, Directed Acyclic Graph).
Затем граф разбивается на стадии. Если данные можно обрабатывать без обмена между узлами кластера, операции остаются в рамках одной стадии. Такие преобразования называют узкими (narrow transformations). Если же требуется перераспределить данные между узлами, например при некоторых видах join или groupBy, движок выполняет перетасовку данных и создает новую стадию. Такие преобразования называют широкими (wide transformations).
- Партиции и параллелизм
Для параллельной обработки Spark разбивает сведения на партиции — логические части набора данных. Каждая партиция обрабатывается независимо от остальных, что позволяет распределять работу между исполнителями.
Количество партиций напрямую влияет на уровень параллелизма. Например, если набор данных разбит на 100 партиций, движок сможет распределить их обработку между несколькими исполнителями и выполнять множество задач одновременно. Если партиций слишком мало, часть ресурсов кластера будет простаивать. Если слишком много — возрастут накладные расходы на управление задачами.
Поэтому выбор количества партиций считается одним из базовых приемов оптимизации Spark-приложений.
- Шаффл
Некоторые операции требуют перераспределения данных между узлами кластера. Например, при соединении таблиц или группировке по ключу записи с одинаковыми значениями должны оказаться на одном исполнителе. Для этого система выполняет шаффл (shuffle) — процесс обмена информацией между узлами кластера.
Шаффл обычно включает сериализацию данных, передачу по сети и, при необходимости, запись промежуточных результатов на диск. Это одна из самых ресурсоемких операций в Spark, поэтому часто становится причиной медленного выполнения запросов.
PySpark и Spark SQL
Вы можете писать код на Python, Scala, Java или R, а можете использовать привычный SQL. Это сделано специально: кому-то удобнее строить обработку данных через программный код, а кто-то предпочитает решать задачи с помощью SQL-запросов.
На практике аналитики чаще всего используют PySpark — Python-интерфейс для Apache Spark. Он позволяет работать с платформой, не выходя из привычной экосистемы Python. При этом сам движок продолжает выполнять все вычисления и управлять распределенной обработкой данных.
Основной объект в PySpark — DataFrame. Его можно представить как таблицу с колонками и типами данных. Если вы работали с pandas, многие операции покажутся знакомыми. Однако есть важное отличие: DataFrame в Spark может храниться не на одном компьютере, а быть распределенным между несколькими узлами кластера.
Например, с помощью DataFrame можно:
- отбирать нужные строки:
df.filter(col(«status») == «active»)
- группировать данные и рассчитывать агрегаты:
df.groupBy(«region»).agg(…)
- объединять таблицы:
df.join(other_df, on=»id», how=»inner»)
Spark SQL — это модуль, позволяющий писать SQL-запросы к данным внутри Spark. Чтобы им воспользоваться, достаточно зарегистрировать DataFrame как временное представление командой createOrReplaceTempView(«table_name»). После этого к нему можно обращаться через стандартный синтаксис SELECT, JOIN, GROUP BY — точно так же, как если бы вы работали с реляционной БД. При этом сведения могут находиться где угодно. Модуль абстрагирует вас от физического местоположения информации и дает работать с ней через единый интерфейс.
На практике аналитики часто комбинируют оба подхода: очищают и подготавливают данные через PySpark, затем регистрируют их как таблицы и строят финальные витрины на Spark SQL.
Решаем типовые аналитические задачи с помощью Spark
Вот три сценария, с которыми специалисты сталкиваются ежедневно. Приведем для каждого пример кода.
Загрузка и чтение данных
На этом этапе приходится учитывать типы данных в Spark: от них зависит, как система будет интерпретировать значения, выполнять вычисления и использовать память кластера. На локальной машине вы, скорее всего, открывали CSV через pd.read_csv(), JSON — через pd.read_json(), а Excel-файлы — через pd.read_excel(). Здесь механика похожая, но есть несколько принципиальных отличий, незнание которых может привести к ошибкам или замедлению работы с первых минут.
CSV: читаем правильно
CSV — это текстовый формат, один из самых распространенных для обмена данными, но для Spark он не оптимален. Когда система читает такой файл, то не знает заранее ни типы колонок, ни корректность структуры. Если схема не задана явно, приходится дополнительно анализировать содержимое файла и определять типы данных автоматически. На больших объемах это будет долго.
Тем не менее на практике CSV-файлы встречаются постоянно, и вот как с ними работать:
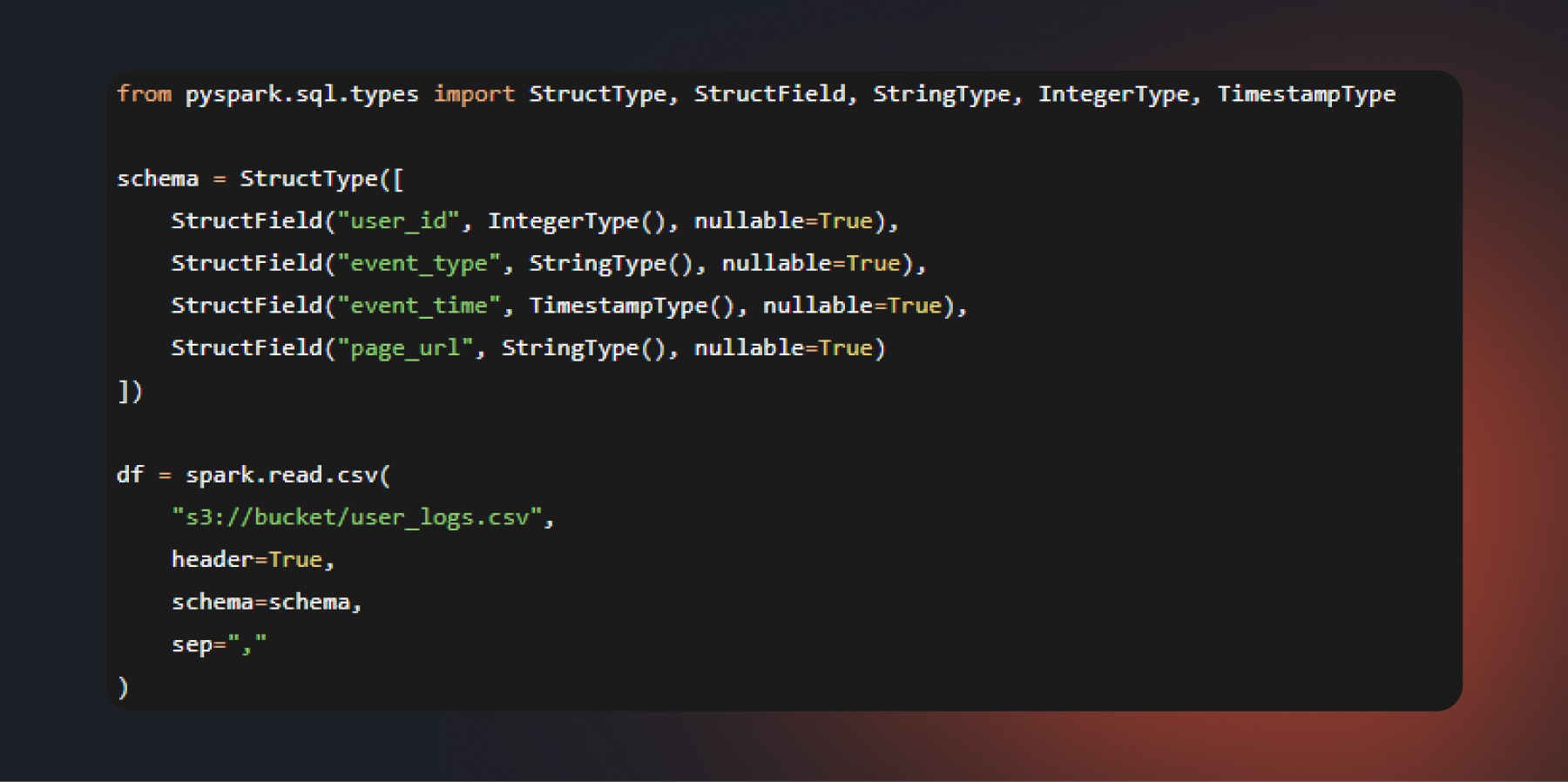
header=True указывает, что первая строка файла содержит названия колонок. sep=»,» задает символ-разделитель; здесь он передан явно, хотя запятая и является значением по умолчанию. Такой подход делает код более понятным и упрощает изменение настроек, если формат данных изменится. Параметр nullable=True в определении схемы тоже можно не указывать, поскольку это значение используется по умолчанию. Однако его явное указание помогает документировать структуру данных и показывает, в каких колонках допустимы пропуски.
Главный элемент здесь — явно заданная схема через StructType. Альтернативный путь — использование inferSchema=True, когда Spark самостоятельно определяет типы колонок. Для этого ему приходится дополнительно анализировать данные, что на больших файлах может заметно увеличить время чтения. Кроме того, автоматически определенные типы не всегда совпадают с ожиданиями. Например, колонка с датами может быть прочитана как строка, а идентификаторы — как числовые значения, хотя ведущие нули в них имеют значение. Если вы явно зададите схему, то избежите подобного
Еще один параметр, о котором стоит знать, — multiLine. Если внутри полей CSV-файла встречаются переносы строк, без multiLine=True Spark может некорректно интерпретировать структуру файла. Однако этот режим снижает производительность, поэтому его стоит включать только при реальной необходимости.
Parquet: формат, с которым движок работает быстрее всего
Это колоночный формат хранения данных, оптимизированный для аналитических запросов. В отличие от CSV, где каждая строка хранится целиком, в Parquet данные организованы по колонкам. Когда запрос затрагивает только две колонки из двадцати, фреймворк читает только необходимые данные, не загружая остальные.
Кроме того, Parquet хранит схему, метаданные и служебную статистику для отдельных частей набора данных. Благодаря этому система может пропускать фрагменты информации, которые заведомо не подходят под условия фильтрации, и запрос выполняется еще быстрее.
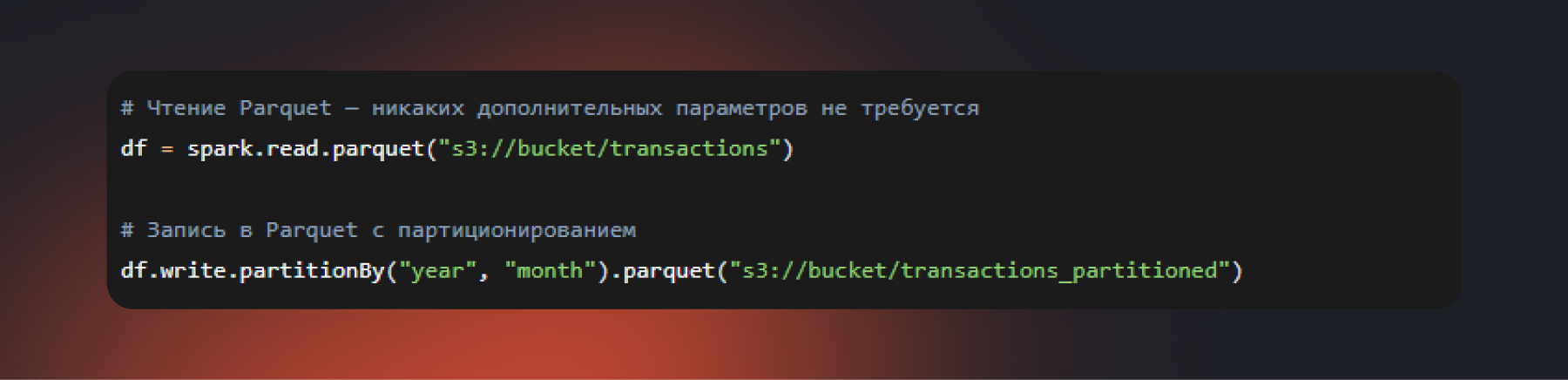
Схема встроена в формат, типы данных определены однозначно, никаких header и inferSchema передавать не нужно. На практике, если у вас есть возможность выбирать формат для хранения данных, всегда предпочитайте Parquet. Скорость чтения и записи по сравнению с CSV отличается в разы, особенно на больших массивах.
JSON: удобен для вложенных структур, но требует осторожности
Часто встречается в логах приложений и ответах интерфейса (API). Платформа Spark умеет работать как с плоскими структурами, так и со сложными вложенными объектами. Однако JSON остается текстовым форматом, поэтому его чтение обычно требует больше ресурсов, чем работа с Parquet.
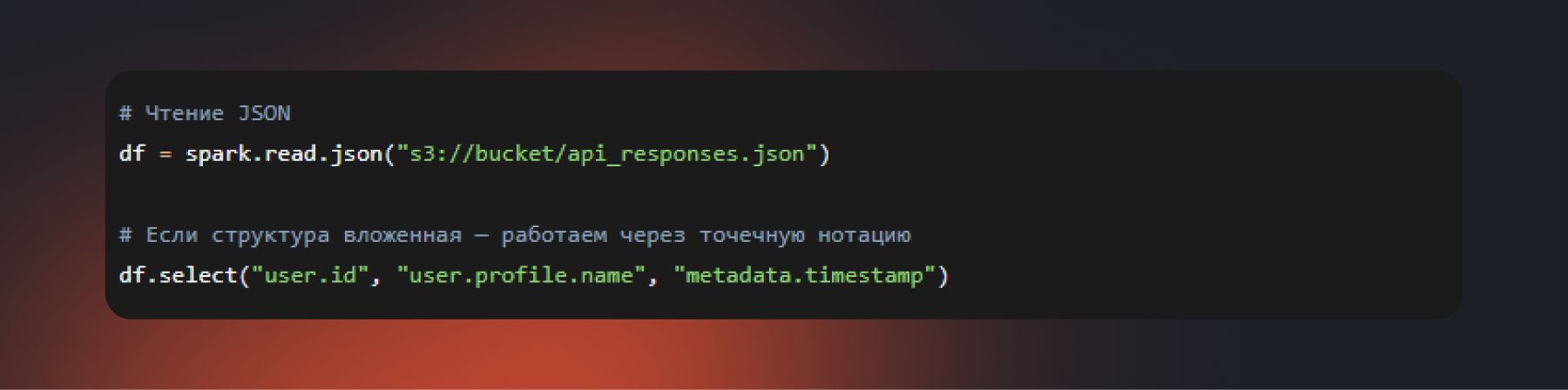
Система автоматически разбирает вложенную структуру JSON в отдельные столбцы, что упрощает дальнейшую работу с данными. Однако для больших наборов JSON не всегда эффективен: при каждом чтении его нужно заново разбирать. Поэтому если данные используются регулярно, их стоит один раз преобразовать в Parquet — это ускорит последующие чтения и снизит нагрузку на кластер.
Excel: что делать, когда вам передали .xlsx
Excel-файлы — наверное, самый неудобный формат для такого движка. У них нет встроенной схемы, они бинарные, запакованные, и Apache Spark не умеет читать их с помощью встроенных средств. Если вам передали .xlsx и требуют с ним работать, стандартный подход — конвертировать в один из поддерживаемых форматов до загрузки в систему.
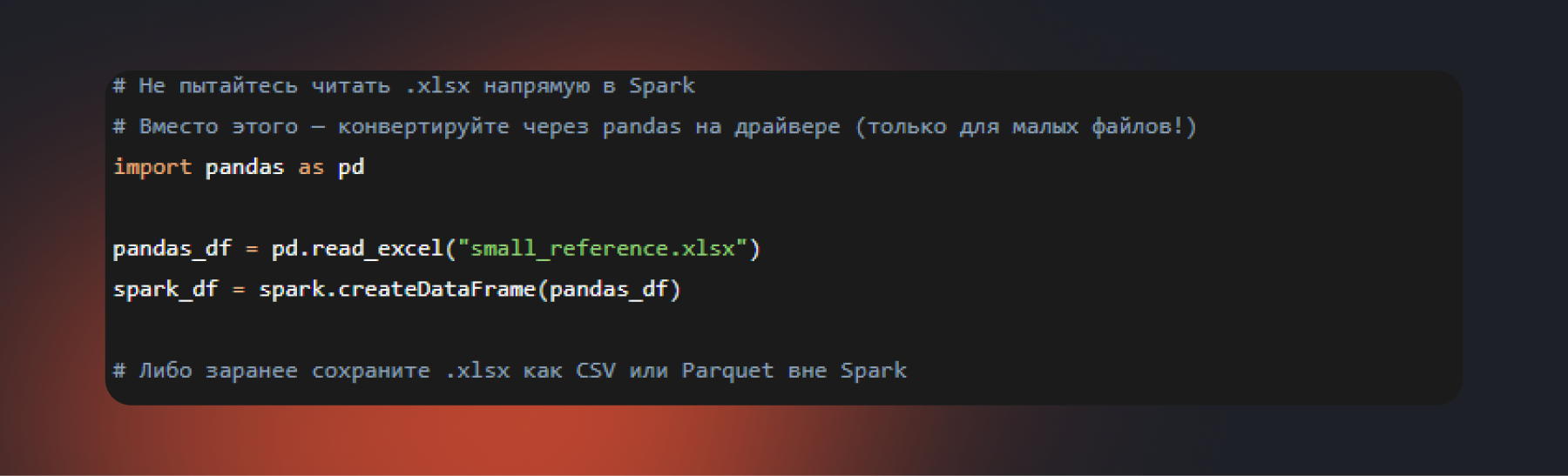
Способ работает только для файлов, которые помещаются в память драйвера, то есть для небольших справочников и классификаторов. Если вам регулярно передают терабайтные Excel-файлы (что само по себе аномалия), единственный разумный путь — договариваться о смене формата на CSV или Parquet на стороне источника.
Очистка и трансформация
Начинается этап, на который обычно уходит большая часть времени аналитика. Здесь удаляются некорректные записи, обрабатываются пропущенные значения, рассчитываются новые признаки и выполняются агрегации. В Spark эти операции выглядят знакомо для тех, кто работал с SQL или pandas, однако при больших объемах данных важно учитывать стоимость каждой операции.
Рассмотрим простой пример. Предположим, необходимо проанализировать только завершенные заказы за текущий год и посчитать выручку по категориям товаров.
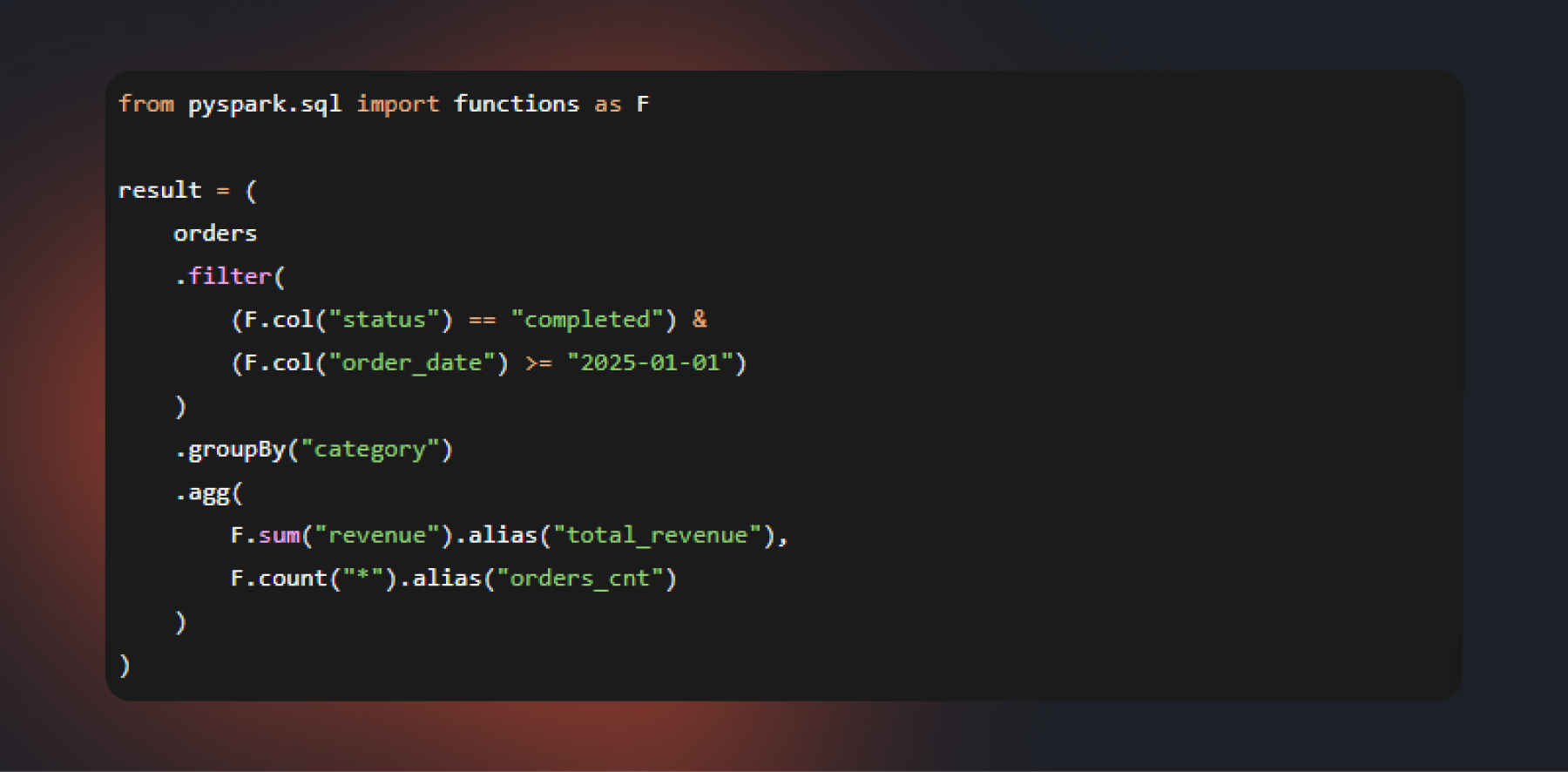
На первый взгляд код мало отличается от аналогичного запроса на SQL. Однако обработка данных в Spark устроена иначе. Каждая операция не выполняется отдельно. Благодаря механизму ленивых вычислений система строит общий план и пытается оптимизировать его перед запуском. Поэтому длинная цепочка трансформаций не обязательно означает несколько последовательных проходов по данным. Условия фильтрации, переданные через &, Spark объединит в один этап, что делает код одновременно и читаемым, и производительным.
Отдельного внимания заслуживает работа с пропусками. В небольших наборах пропущенные значения часто обрабатываются вручную, но на сотнях миллионов строк такой подход невозможен. Для начала оцените масштаб проблемы:

Может выясниться, что проблема затрагивает лишь несколько десятков записей — тогда их можно просто удалить. А может оказаться, что пропуски присутствуют в значительной части сведений и требуют более аккуратного подхода. Spark предоставляет встроенные методы для обоих сценариев:
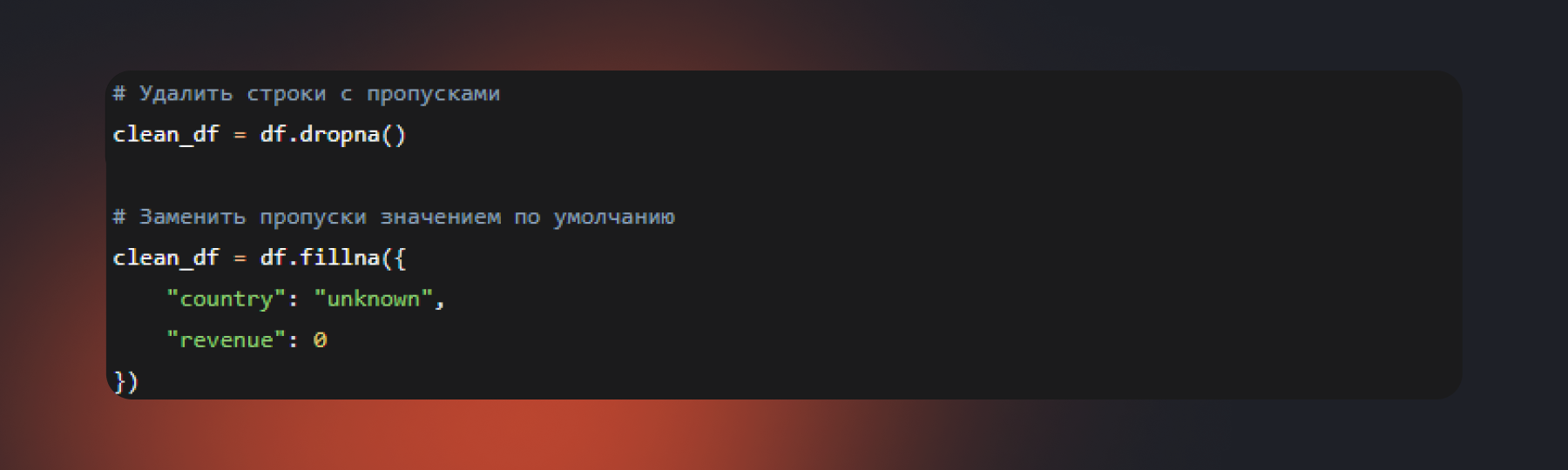
Метод dropna() удаляет все строки, в которых встречается хотя бы один пропуск. Это быстрое решение, но применять его стоит только после диагностики: если пропуски разбросаны по разным колонкам, можно потерять значительную долю данных. Метод fillna() заменяет пропуски указанными значениями — нулем для числовых показателей, специальной меткой вроде «unknown» для категориальных. Выбор стратегии всегда остается за аналитиком и зависит от контекста.
Еще одна распространенная задача — расчет агрегатов. Вы можете строить витрину для расчета показателей по пользователям, регионам или продуктам. В таких сценариях важно помнить, что группировка (groupBy) относится к числу наиболее ресурсоемких операций. Для выполнения агрегации системе обычно приходится выполнять шаффл, собирая записи с одинаковыми ключами на одних и тех же исполнителях.
По этой причине при работе с большими данными полезно придерживаться простого правила: сначала максимально сократить объем обрабатываемой информации с помощью фильтрации, а уже затем выполнять группировки и другие тяжелые операции. Это универсальный принцип работы с этим движком: чем меньше сведений попадет в агрегацию, тем быстрее будет выполнен запрос.
Анализ данных в Spark
Именно на этом этапе особенно заметны преимущества движка при работе с большими объемами информации.
Одна из самых распространенных операций в аналитике — соединение таблиц (join). Например, может потребоваться объединить журнал событий пользователей с данными о клиентах или связать заказы с каталогом товаров. При работе с сотнями миллионов строк именно соединения часто становятся самым дорогим этапом вычислений.
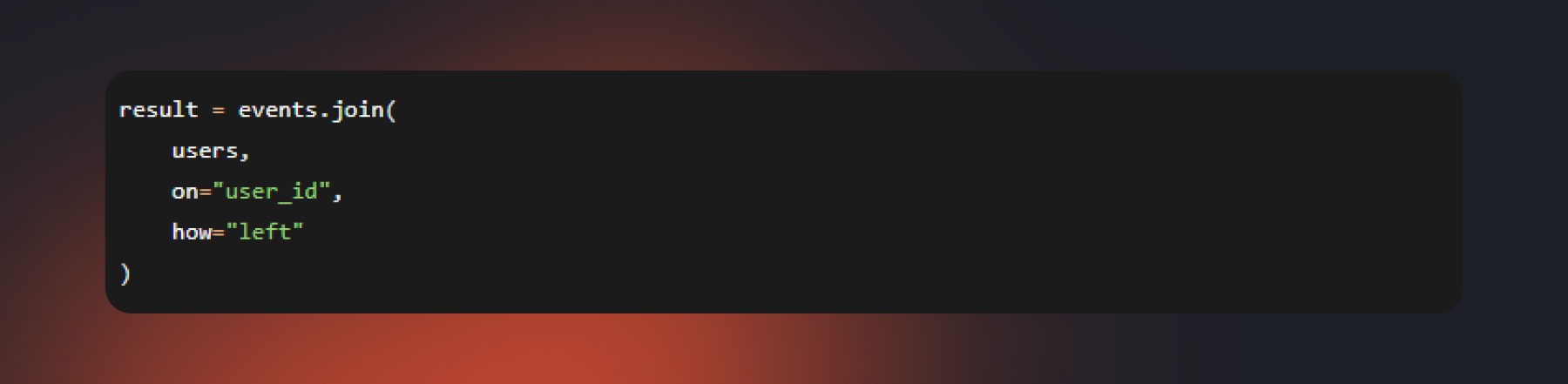
Помните, что при соединении больших таблиц система нередко перераспределяет данные между узлами кластера. Как этого избежать, расскажем в блоке про оптимизацию Spark.
Оконные функции позволяют выполнять расчеты внутри групп данных без схлопывания результата в одну строку. Например, можно посчитать порядковый номер заказа для каждого пользователя, накопительную выручку или сравнить текущее значение показателя с предыдущим.
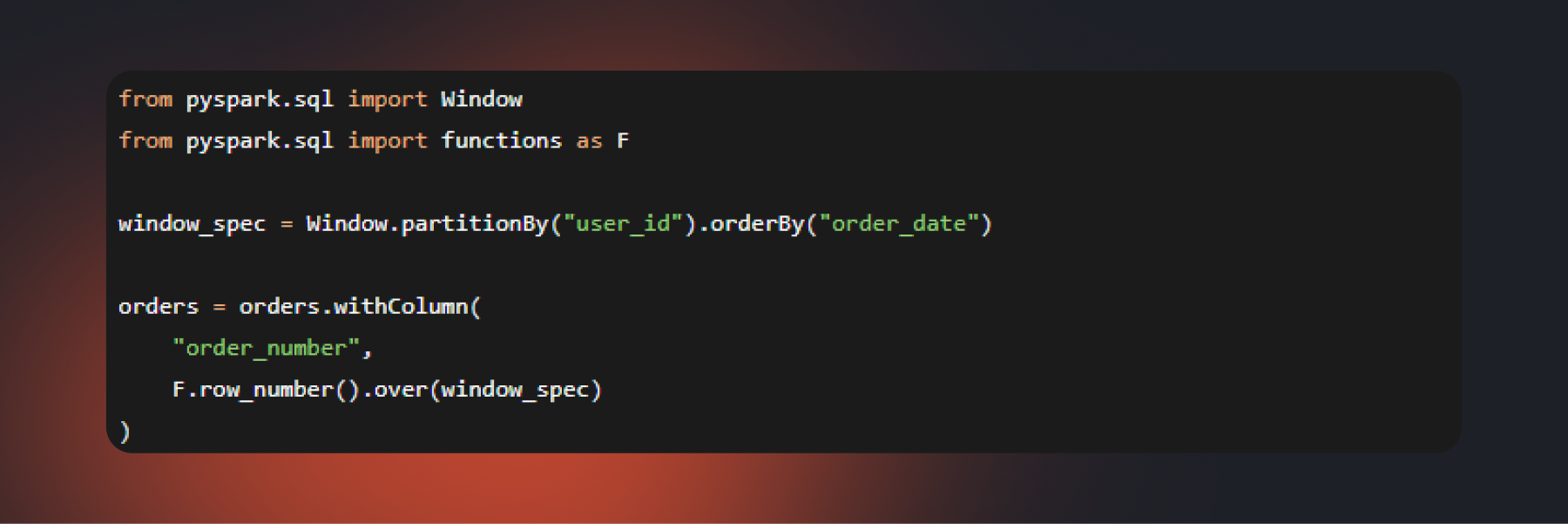
Значительная часть задач, связанных с расчетом когорт, удержания пользователей или LTV (Lifetime Value — пожизненная ценность клиента), решается именно с их помощью.
Полезно помнить, что оконные функции без partitionBy() собирают все данные в одну партицию, что на больших объемах неизбежно приводит к перекосу и резкому падению производительности. Всегда указывайте столбец для разбиения на группы, даже если кажется, что этого не требуется.
Следующий уровень работы с данными — построение витрин. Их используют BI-системы, аналитические сервисы и модели машинного обучения Вместо того чтобы каждый раз пересчитывать выручку по клиентам из сырых таблиц, аналитик может создать витрину со всеми необходимыми метриками и обновлять ее по расписанию. Вокруг этого строится значительная часть корпоративной отчетности.
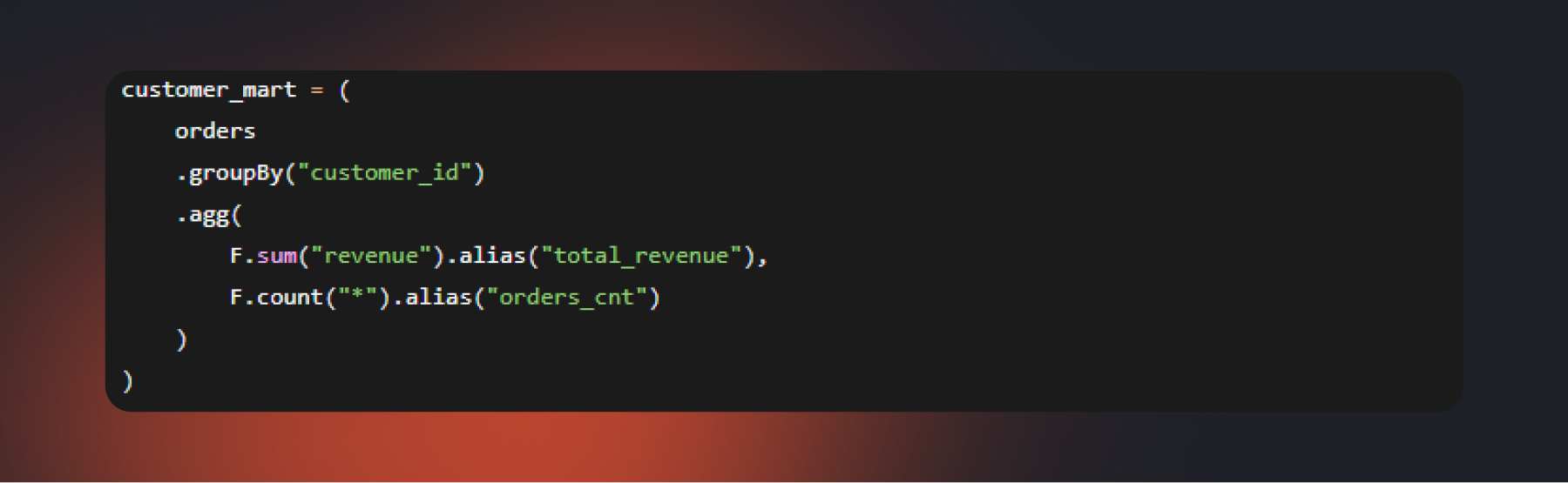
Основы оптимизации для начинающих
Повседневная аналитика в Spark требует не только умения писать корректный код, но и понимания того, как этот код будет выполняться в реальных условиях. Собрали три практические рекомендации, которые помогают ускорить выполнение запросов и не перегрузить кластер.
Совет 1. Используйте broadcast join для соединения с небольшими таблицами
Мы уже упоминали, что соединение двух больших таблиц вызывает шаффл. Это стандартное поведение, но оно же и самое дорогое.
Но если одна из соединяемых таблиц относительно невелика, ее можно целиком разослать каждому исполнителю с помощью broadcast join. Вместо того чтобы двигать по сети обе таблицы, система копирует маленькую таблицу в память каждого узла, а большая таблица обрабатывается на месте. Никакого перераспределения.
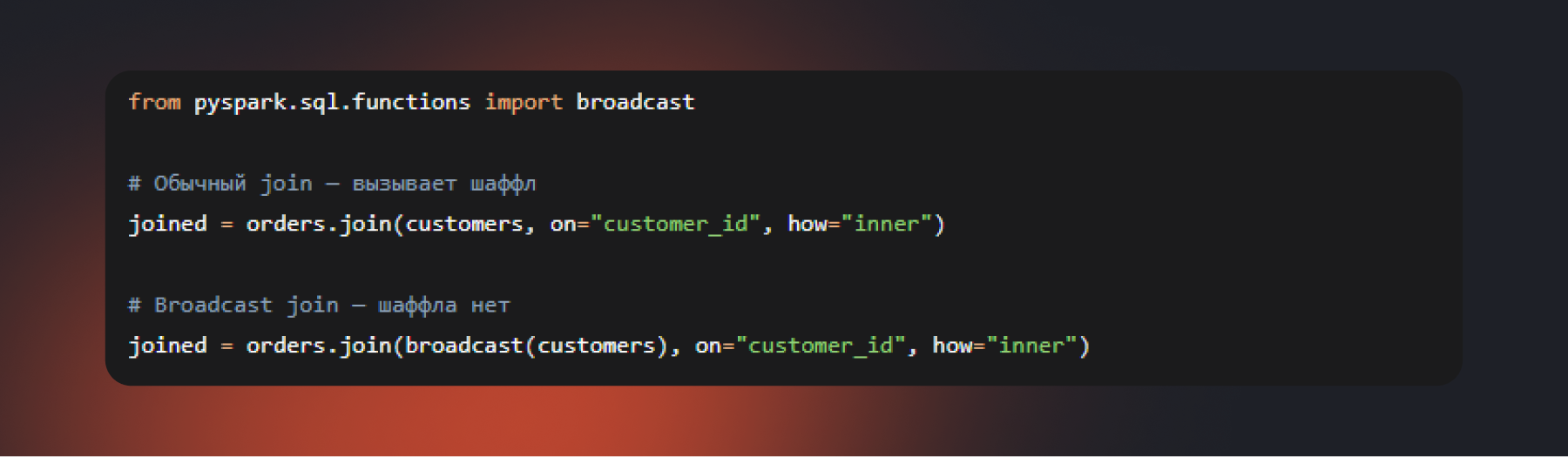
Если размер таблицы в сжатом виде не превышает 100–200 мегабайт, используйте эту операцию. Подходят большинство справочников: таблица клиентов, каталог товаров, список регионов, курсы валют.
Важно
Spark автоматически определяет подходящие таблицы, ориентируясь на параметр spark.sql.autoBroadcastJoinThreshold (по умолчанию 10 МБ). Но полагаться только на автоматику не стоит: явное указание broadcast() дает предсказуемый результат и работает даже для таблиц, превышающих автоматический порог, но все еще разумного размера.
Совет 2. Что делать, когда один ключ портит все
Перекос данных (data skew) — одна из самых неприятных проблем в распределенных вычислениях. Представьте, что группируете заказы по городам и считаете выручку. В большинстве городов количество заказов исчисляется тысячами, но на Москву приходится 40% всех записей. Исполнитель, которому достался ключ «Москва», будет обрабатывать гигабайты данных в одиночку, в то время как остальные исполнители уже закончат работу и будут простаивать. Время выполнения всего запроса задается самым медленным исполнителем — это и есть эффект перекоса.
Для начала, проверьте распределение данных по ключу, который планируете использовать в группировке или соединении:

Если на один или несколько ключей приходится непропорционально много записей, можно применить технику salted join: добавить к ключу случайную компоненту и тем самым распределить записи проблемного ключа между несколькими исполнителями.
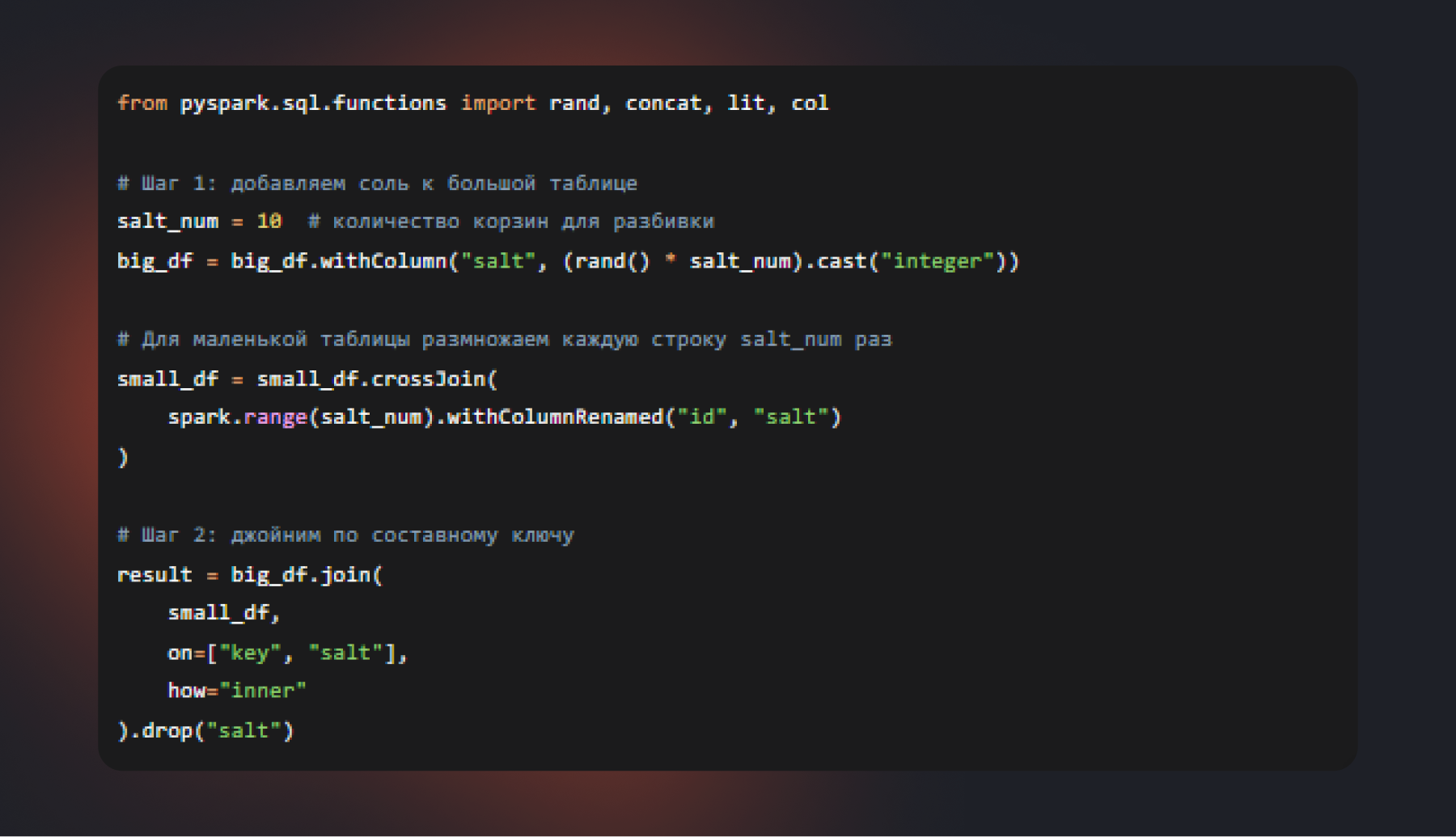
Этот подход увеличивает время выполнения для неперекошенных ключей незначительно, но для перекошенных дает многократный выигрыш за счет равномерного распределения нагрузки.
Совет 3. Не кешируйте все подряд
Это прямой путь к нехватке памяти и падению задач.
Метод cache() сохраняет DataFrame в памяти исполнителей, чтобы при повторном обращении не перечитывать данные с диска и не пересчитывать всю цепочку трансформаций заново. Это полезно, но память кластера не бесконечна.
Кеширование оправдано, если:
- Данные используются многократно в рамках одного сценария. Например, вы несколько раз соединяете с одним и тем же очищенным DataFrame или многократно фильтруете его под разные срезы отчета.
- После дорогостоящих операций — шаффла, сложных оконных функций, — результат которых нужен для нескольких следующих шагов.
- При итеративных алгоритмах, где одни и те же данные обрабатываются в цикле.
Важно
Всегда освобождайте закешированные данные вызовом unpersist(), когда они больше не нужны. Это хорошая привычка, которая предотвращает утечки памяти в длинных ETL-процессах.
Заключение
Теперь вы знаете, что такое «Спарк», как устроена обработка данных на кластере и какие задачи аналитик решает с помощью PySpark и Spark SQL. Следующий шаг — практика. Именно она помогает понять, зачем нужен Spark и как пользоваться программой в реальных проектах: от построения витрин до обработки миллиардов строк данных.
