ETL для аналитика: как собирать данные из разных источников
Представьте: руководство требует отчет, а аналитик вместо поиска инсайтов часами объединяет файлы, исправляет ошибки и борется с разными форматами. Ведь информация о продажах лежит в CRM-системе, рекламные показатели — в таблицах, сведения о пользователях — в базе данных.
Содержание
- Разберемся в базе
- Как устроен ETL-процесс: 3 ключевых этапа
- ETL и ELT: в чем разница и что выбрать аналитику
- Что такое пайплайн данных и как он связан с ETL
- Как ETL помогает аналитику в повседневных задачах
- Обзор ETL-инструментов
- От данных к дашбордам
- Пошаговое построение ETL-процесса для аналитика
- Заключение
Чтобы не тратить полдня на подготовку, специалист должен наладить процессы. В статье поговорим об аббревиатуре ETL: что это простыми словами и что такое в контексте анализа данных, из каких этапов состоит процесс и почему стал важной частью современной аналитики.

Разберемся в базе
Если вы когда-нибудь пытались собрать отчет вручную, то знаете, что это похоже на детективную работу. Скачиваете файлы, открываете, пытаетесь понять, по какому ключу их склеить. Обнаруживаете, что в одной таблице клиент записан как «ООО Ромашка», а в другой — как «Ромашка ООО». Пока вникните и почистите, пройдет часа три. А завтра информация обновится, и все придется начинать сначала.
Нужен способ автоматизировать всю эту рутину и получать готовые данные к тому моменту, когда вы садитесь за анализ.
Расшифровка ETL и его роль в аналитике
Акроним ETL расшифровывается как Extract, Transform, Load — извлечение, преобразование и загрузка. Проще говоря, это конвейер, который забирает данные из всех систем, приводит их к общему знаменателю и складывает в одно место.
Возьмем к примеру интернет-магазин. Каждый день в нем появляются новые заказы, сведения о пользователях, расходы на рекламу и информация о платежах. Информация приходит из разных систем и может отличаться по формату: где-то дата записана как «17.06.2026», где-то — «2026-06-17», а названия одного и того же показателя могут быть разными.
ETL создает единый поток. Сначала данные извлекаются из источников, затем очищаются и приводятся к нужному формату, после чего попадают в хранилище или аналитическую систему.
В результате аналитик получает одну большую таблицу (или несколько связанных), с которой можно сразу работать: строить отчеты, искать закономерности и отвечать на вопросы бизнеса.
Почему аналитику важно понимать ETL-процессы
От этого напрямую зависит скорость и качество его работы. Например, вместо еженедельной ручной сборки отчета из десяти таблиц можно настроить процесс, который будет сам обновлять данные по расписанию.
Интеграция ETL в аналитику помогает:
- быстрее собирать панели-дашборды;
- находить ошибки в отчетах;
- быстрее проверять гипотезы;
- работать с массивами информации;
- понимать ограничения данных.
Это связующее звено между сырыми данными и аналитическими выводами.
Видеть за цифрами бизнес-задачи учат на курсе «Аналитик данных». Студенты не просто пишут код и строят графики, а выстраивают процесс работы с данными от начала до конца. На практике вы соберете дашборд, настроите автоматическую выгрузку отчетов и поймете, как экономить часы рабочего времени. В обновленной программе есть отдельный модуль по Airflow, где вы научитесь создавать ETL-пайплайны, чтобы стать более востребованным и универсальным специалистом.
Как устроен ETL-процесс: 3 ключевых этапа
Допустим, наш интернет-магазин хочет понять, какие рекламные каналы приносят больше всего продаж. Для этого нужно объединить данные о заказах, клиентах и рекламных расходах. Рассмотрим конвейер подробнее.
1. Как извлечь данные
На этом шаге система получает информацию из всех нужных источников.
Например:
- база данных;
- CRM-система;
- рекламный кабинет;
- файлы Excel и Google Sheets;
- внешние сервисы через интерфейс API.
Когда нужно посчитать эффективность рекламы, ETL забирает данные о расходах из рекламных платформ, а информацию о заказах — из CRM или базы данных.
Главная задача этапа извлечения (Extract) — собрать все необходимые данные в одном процессе и регулярно получать обновления.
2. Как превратить сырые данные в готовые для анализа
В извлеченных сведениях могут быть пропуски, дубли, разные форматы и ошибки. На этапе преобразования (Transform) данные приводятся к единому виду. Например:
- даты переводятся в один формат;
- удаляются повторяющиеся записи;
- объединяются таблицы из разных источников;
- рассчитываются новые показатели.
Здесь вместо отдельных таблиц с заказами и рекламными расходами появляется единая таблица: дата, канал, количество продаж, выручка и стоимость привлечения клиента.
3. Как и куда загрузить подготовленные данные
Заключительный этап — загрузка готовых данных в систему, где с ними будет работать аналитик. В зависимости от задач компании это может быть:
- Хранилище данных (Data Warehouse) — централизованная база, куда стекается информация из всех систем компании. Продажи, клиенты, логистика, маркетинг — все в одном месте. Это позволяет аналитику делать кросс-функциональные отчеты, не дергая разные источники по отдельности. Например, можно легко сопоставить рекламные расходы с выручкой по каждому региону за один день.
- Аналитическая база данных — более легкий и быстрый вариант, когда вам нужно оперативно выполнять сложные запросы к большим объемам данных. Такие базы оптимизированы именно для чтения и агрегации, а не для постоянной записи новых транзакций.
- BI-система — Power BI, Tableau, DataLens или аналоги. В некоторых случаях данные загружаются напрямую в BI-инструмент, минуя отдельное хранилище. Это подходит для небольших проектов или когда отчет нужно сделать быстро и без лишней инфраструктуры. Но у такого подхода есть ограничения: BI-системы не всегда справляются с очень большими массивами и сложными преобразованиями.
- Среда для машинного обучения — если подготовленные данные нужны для тренировки модели. Например, вы собрали историю поведения пользователей, очистили ее, сформировали признаки и теперь загружаете готовый набор данных в Jupyter Notebook или в специализированный ML-инструмент.
После обработки данных интернет-магазина ETL может загрузить итоговую таблицу в хранилище. В ней будут все необходимые поля: дата заказа, клиент, товар, канал привлечения, сумма покупки и другие показатели. Аналитик подключает к ней BI-инструмент и создает отчет по продажам.
Важно
На этапе загрузки (Load) часто настраиваются правила обновления информации: например, отчет может автоматически получать новые данные каждый час, день или неделю. Благодаря чему специалист работает с актуальной информацией и не тратит время на повторные выгрузки и ручное обновление.
ETL и ELT: в чем разница и что выбрать аналитику
На первый взгляд эти подходы похожи: оба помогают собрать данные из разных источников и подготовить их для анализа. Разница в том, на каком этапе происходит преобразование данных.
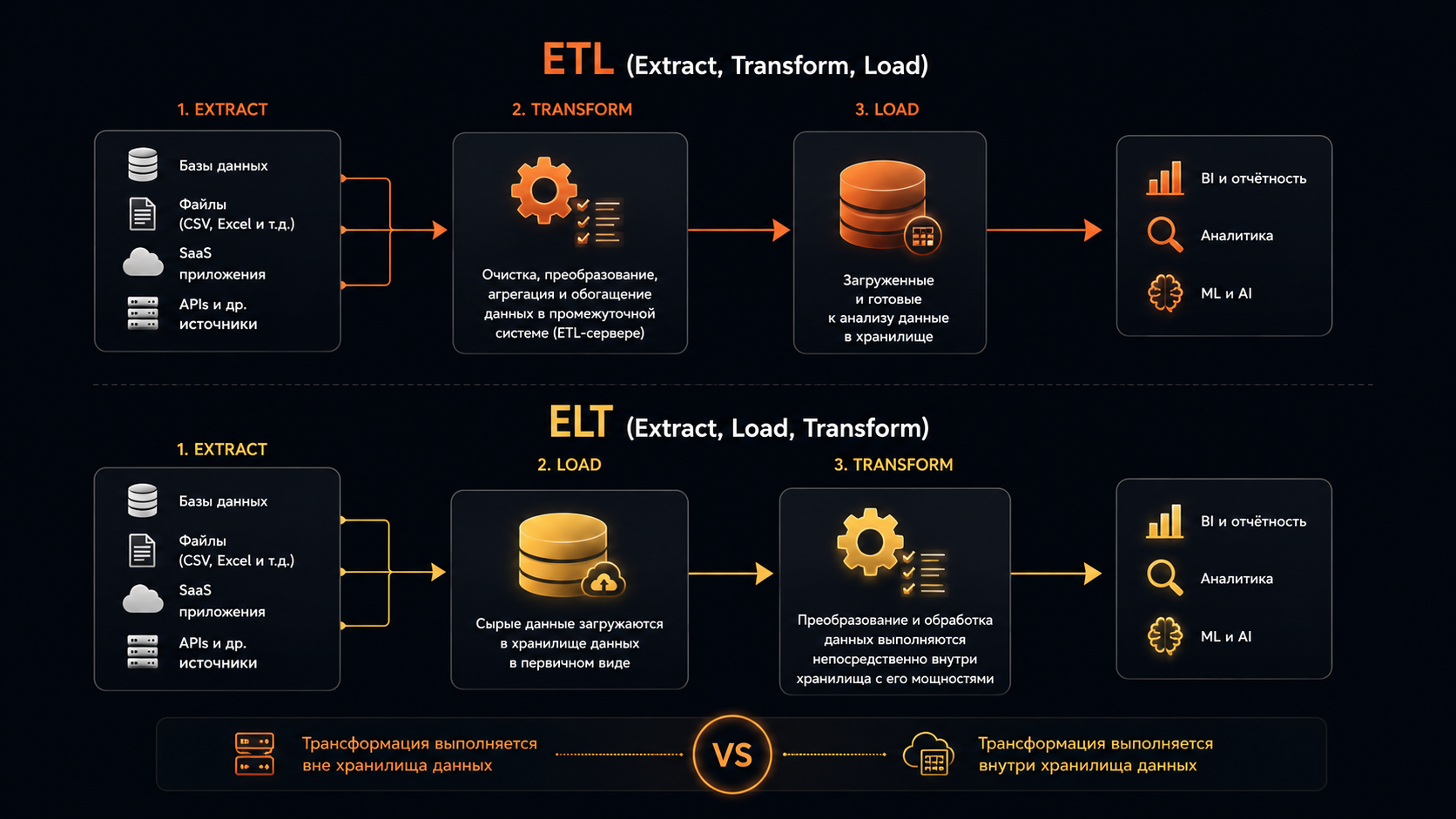
ELT — это:
- извлечение (Extract) → данные забираются из источников;
- загрузка (Load) → сырые данные загружаются в хранилище;
- преобразование (Transform) → обработка происходит уже внутри хранилища.
Такой подход используют современные аналитические платформы, которые умеют быстро обрабатывать большие объемы данных. Сначала сохраняется исходная информация, а нужные преобразования выполняются уже во время работы с ней.
Например, компания может загрузить все данные о заказах, пользователях и событиях сайта в единое хранилище, а затем создавать разные представления данных под конкретные задачи: отчеты, исследования или модели машинного обучения.
Для аналитика выбор между ETL и ELT обычно не вопрос личного предпочтения. Все зависит от того, как устроена инфраструктура компании.
| Критерий | Склоняемся к ETL | Склоняемся к ELT |
| Объем данных | Данных немного (до нескольких гигабайт), их можно обработать заранее без больших затрат ресурсов | Данных много (терабайты и больше), хранить и обрабатывать их выгоднее в облачном хранилище |
| Требования к актуальности | Отчеты обновляются раз в день или реже. Можно подождать, пока данные пройдут все этапы очистки | Нужна высокая скорость загрузки. Данные должны появиться в системе как можно быстрее, даже если они еще не обработаны |
| Гибкость в работе | Задачи аналитика фиксированные: одни и те же отчеты, одни и те же метрики. Изменения происходят редко | Аналитик часто экспериментирует: проверяет новые гипотезы, подключает незнакомые источники, меняет логику расчетов |
| Кто пишет преобразования | Преобразования настраивают инженеры или ETL-разработчики. Аналитик получает уже готовую витрину | Аналитик сам пишет SQL-запросы и строит витрины по мере необходимости |
| Хранилище данных | Используется классическое корпоративное хранилище (например, PostgreSQL, Oracle). Оно не оптимизировано для сложных вычислений на больших объемах | Используется современное облачное решение (Snowflake, BigQuery, Redshift). Оно позволяет делать преобразования прямо внутри хранилища, не создавая промежуточные слои |
| Качество исходных данных | Данные приходят из проверенных источников, но требуют строгой очистки перед использованием. «Мусор» не должен попадать в хранилище | Данные могут быть сырыми и неструктурированными. Их качество неизвестно, и лучше сохранить все как есть, а разбираться потом |
| Бюджет на хранение | Хранение дорогое, поэтому лучше держать только очищенные данные и не хранить лишнего | Хранение дешевое (особенно в облаках), поэтому можно позволить себе хранить все сырые данные без ограничений |
На практике аналитик может работать с обоими подходами. Главное — понимать, где находятся исходные сведения, какие преобразования они прошли и почему итоговые показатели выглядят именно так.
Что такое пайплайн данных и как он связан с ETL
Пайплайн данных (data pipeline) — это последовательность шагов и компонентов, по которым данные проходят от источников до потребителей (аналитики, ML-моделей, BI и т.д.). Он описывает маршруты доставки, преобразования, хранения и потребления данных, включая механизмы оркестрации, мониторинга и обеспечения качества.
Схематично путь выглядит так:
Источники → Сбор → Обработка → Хранение → Анализ → Отчеты
Вернемся к интернет-магазину. Каждый день здесь происходит множество событий:
- менеджеры оформляют заказы в CRM;
- на сайт заходят посетители, что фиксирует веб-аналитика;
- рекламные системы списывают бюджет на привлечение клиентов;
- в учетной системе обновляются остатки товаров.
Пайплайн автоматически забирает все эти сведения из каждого источника, обрабатывает их, складывает в хранилище и делает доступными для аналитиков.
Пайплайн — это весь маршрут доставки данных, а ETL — один из ключевых этапов этого маршрута.
Вся цепочка может выглядеть так:
- Система фиксирует новую продажу.
- Коннектор/CDC извлекает событие из CRM.
- Трансформации: очистка, обогащение (например, демография клиента), агрегации.
- Набор загружается в хранилище.
- BI-система обновляет отчет по продажам; метрики и алерты сигнализируют о проблемах с качеством данных.
В современных командах аналитики все чаще работают не только с готовыми отчетами, но и с процессами подготовки данных. Понимание того, как устроен пайплайн, помогает эффективнее использовать BI-инструменты, работать с большими массивами информации и взаимодействовать с инженерами данных.
Как ETL помогает аналитику в повседневных задачах
Быстрее собирать дашборды
С ETL данные обновляются автоматически, поэтому специалист может сосредоточиться на анализе, а не на подготовке таблиц.
Быстрее проверять гипотезы
Если данные уже собраны в едином формате, аналитик быстрее проводит исследование и получает выводы.
Повышать качество отчетов
Ручная обработка часто приводит к ошибкам, а настроенные ETL-процессы это исправляют. Ведь можно задать правила заранее: очистить данные, привести показатели к единому виду и сделать отчет более надежными.
Работать с большими объемами данных через хранилища и БД
Что особенно важно для аналитики и машинного обучения, где качество результата зависит от качества подготовленных сведений.
Обзор ETL-инструментов
Выбор зависит от задач компании, количества источников и объема информации.
- ETL-инструменты без кода и с минимальным программированием
Такие решения подходят аналитикам, которым нужно быстро подключить источники данных и настроить регулярные обновления.
С их помощью можно:
- подключать CRM, базы данных и файлы;
- настраивать очистку и преобразование данных;
- автоматизировать подготовку отчетов.
Обычно работа происходит через визуальный интерфейс. Специалист собирает процесс из готовых блоков, а не пишет код.
- ETL через SQL и базы данных
SQL — один из основных инструментов подготовки данных. Многие ETL-задачи выполняются прямо внутри БД:
- объединение таблиц;
- фильтрация записей;
- расчет показателей;
- создание аналитических витрин.
Например, аналитик может настроить запрос, который каждый день обновляет таблицу с показателями продаж или поведением пользователей.
- ETL с помощью Python и платформ для обработки данных
Python используют, когда простых инструментов уже недостаточно. Он позволяет работать с API, нестандартными форматами данных и сложными сценариями обработки.
Для больших объемов информации и потоковой обработки часто применяют специальные платформы, например Apache Spark и PySpark. Они позволяют распределять обработку между несколькими серверами и эффективно работать с массивами информации.
- Корпоративная инфраструктура ETL
В крупных компаниях конвейер обычно состоит не из одного инструмента, а из целой системы. Помимо самих процессов обработки данных используются инструменты оркестрации — они управляют последовательностью задач, расписанием запусков и зависимостями между этапами.
Например, Apache Airflow или Dagster могут запускать ETL-процессы по расписанию, следить за их выполнением и уведомлять об ошибках.
От данных к дашбордам
BI-системы помогают превращать данные в понятные отчеты. Но перед тем как построить график или вывести показатель, данные нужно подготовить.
ETL-процессы в Power BI
В Power BI аналитик может выполнять часть ETL-задач прямо внутри инструмента, не привлекая инженеров. Это удобно, когда нужно быстро прототипировать отчет или объединить данные из нескольких источников для разового анализа.
Работа обычно начинается с подключения к источникам данных: Excel/CSV, Google Sheets, базы данных, CRM, API, облачные хранилища и прочие внешние сервисы.
Далее используется Power Query — инструмент для подготовки данных. С его помощью можно удалять лишние строки и дубликаты, исправлять ошибки, изменять форматы, объединять таблицы и создавать вычисляемые поля.
После подготовки данные загружаются в модель данных Power BI (dataset), где аналитик создает визуализации в Power BI Desktop и публикует отчеты в Power BI Service.
Интеграция ETL в корпоративные BI-платформы
В больших компаниях BI обычно работает не напрямую с исходниками, а с подготовленными наборами информации.
Типичная цепочка выглядит так:
Источники данных → ETL-процесс → хранилище данных → BI-система → отчеты
Такой подход помогает поддерживать единые правила расчета показателей. Например, вся компания использует одно определение «активного клиента» или «выручки», а не разные версии в каждом отчете.
Пошаговое построение ETL-процесса для аналитика
Все начинается с бизнес-задачи. Например, онлайн-кинотеатр заметил, что количество новых подписок растет, но пользователи стали реже продлевать подписку после первого месяца. Команда хочет понять причину: какие факторы влияют на отток и что можно изменить.
Чтобы ответить на этот вопрос, аналитику нужно собрать информацию из нескольких систем.
Шаг 1. Определить задачу и источники данных
Сначала формулируются конкретные вопросы:
- пользователи с какой активностью чаще уходят;
- влияет ли количество просмотров на продление подписки;
- связаны ли обращения в поддержку с отказом от сервиса.
Для анализа понадобятся данные из:
базы пользователей — информация о клиентах и тарифах;
системы аналитики — история просмотров и действий;
биллинга — платежи и статус подписки;
CRM — обращения в поддержку.
Важно заранее понять, как эти данные связаны между собой. Например, общий идентификатор пользователя (user_id) позволит объединить таблицы.
Шаг 2. Извлечь данные из источников (Extract)
Теперь ETL-процесс автоматически забирает нужную информацию.
Например:
- данные пользователей обновляются раз в день;
- новые события просмотров загружаются каждый час;
- платежи подтягиваются при изменении статуса подписки.
Шаг 3. Подготовить данные (Transform)
Помимо работы над ошибками, тут создаются новые показатели, которых не было в исходниках.
Например:
- сколько минут пользователь смотрел контент в первую неделю;
- сколько раз обращался в поддержку;
- сколько дней прошло с последнего входа.
Так появляется единый набор данных.
Шаг 4. Загрузить данные в нужную систему (Load)
Например, аналитик подключает готовую витрину данных к Power BI и видит:
- какие пользователи чаще всего отменяют подписку;
- какая активность связана с удержанием;
- какие группы клиентов требуют внимания.
Шаг 5. Настроить обновление и контроль качества
Осталось сделать процесс стабильным. ETL запускается автоматически, а система проверяет:
- все ли источники работают;
- не пропали ли данные;
- не изменились ли форматы;
- нет ли резкого падения количества записей.
Если что-то ломается, команда получает уведомление и может исправить проблему до того, как ошибка попадет в отчет.
Заключение
Чем больше данных появляется в компании, тем важнее автоматизировать их подготовку. Теперь вы знаете, как расшифровывается ETL в контексте интеграции данных, его основные этапы, чем этот подход отличается от ELT и какие инструменты используются. Понимание этих процессов помогает быстрее находить ошибки, эффективнее работать с большими объемами информации и создавать более качественные аналитические решения.
