Корпоративные хранилища данных для аналитика — сравниваем DWH, Data Lake, Lakehouse
Раньше корпоративной аналитике хватало классического хранилища Data Warehouse да SQL-отчетов. Сегодня компании работают с логами, потоковыми данными, моделями машинного обучения (ML) и JSON-форматами, поэтому одной архитектуры уже недостаточно.
Содержание
- Как архитектура данных влияет на работу аналитика
- Что такое корпоративное хранилище данных
- Современный подход: Data Lake — что это такое
- Гибрид будущего: Data Lakehouse
- Сравниваем три архитектуры для аналитика
- Подходы Инмона и Кимбалла
- Как работают с Data Warehouse и Data Lake на практике
- Где учиться
- Заключение
Разберем, чем отличаются DWH, Data Lake и Lakehouse и что важно понимать в этих подходах современному аналитику.

Как архитектура данных влияет на работу аналитика
Представьте два рабочих дня.
День первый: вы открываете корпоративное хранилище, где данные структурированы, связи прописаны, а метрики согласованы. Пишете SQL-запрос, и через десять минут интерактивный отчет-дашборд готов.
День второй: перед вами система Data Lake. Сотни файлов, нет схемы, нет документации. Час уходит только на то, чтобы понять, где нужные сведения и в каком они формате.
Один и тот же специалист, одна и та же задача. Но скорость и результат принципиально отличаются. Потому что архитектура данных определяет не только то, где хранится информация, но и как аналитик с нею работает, какие инструменты использует и сколько времени тратит на подготовку до начала самого анализа.
Что такое корпоративное хранилище данных
Представьте крупную компанию: данные о продажах лежат в CRM, маркетинговые расходы — в рекламных кабинетах, финансовые показатели — в ERP-системе, а поведение пользователей — в логах приложения. Если аналитик будет собирать все это вручную, отчеты начнут расходиться, а подготовка займет больше времени, чем интерпретация.
Корпоративное хранилище данных (или Data Warehouse, DWH, КХД) — это централизованная система, в которой данные из разных источников собираются, очищаются, приводятся к единому формату и подготавливаются для аналитики, BI-отчетности и принятия бизнес-решений.
Важно
Новичкам не всегда понятно, чем хранилище данных отличается от базы данных. Если просто, то первое заточено под быстрые аналитические запросы к большим объемам исторических данных, а вторая оптимизирована под быструю запись отдельных транзакций.
Структурированный порядок для отчетности
Ключевая особенность КХД — строгая организация данных. Прежде чем попасть в хранилище, информация проходит через моделирование и стандартизацию. Структура проектируется заранее: определяются таблицы фактов и справочников, связи между ними, типы полей и правила именования. Такой подход называют schema-on-write — «схема при записи». При этом в современных архитектурах нередко есть и raw/staging-слои, где данные сохраняются близко к исходному виду для трассируемости и последующей обработки.
Для аналитика все это означает:
- Предсказуемость
Таблица sales действительно содержит продажи, поле revenue — выручку по принятым бизнес-правилам, а customer_id связан со справочником клиентов. Не нужно каждый раз разбираться, что означает поле, или вручную приводить даты к единому формату. Это снижает риск ошибок и ускоряет анализ.
- Качество данных
В КХД обычно встроены проверки и правила валидации: дубликаты выявляются, пропущенные значения помечаются или заполняются по заданным правилам, а противоречивые записи отправляются на дополнительную обработку. В результате специалист работает не с сырьем, а с подготовленным и проверенным набором информации.
- Стабильность
Регламентная отчетность строится по расписанию, данные обновляются предсказуемо, а метрики рассчитываются по единым правилам. Один и тот же запрос, выполненный сегодня и через месяц на одних и тех же исторических данных, даст одинаковый результат. Это критично для финансовой, управленческой и регуляторной отчетности.
Для каких задач выбирают КХД (DWH)
Корпоративное хранилище особенно хорошо подходит для задач, где важны стабильность, согласованность метрик и предсказуемая структура сведений.
Регламентная отчетность и KPI. Например, если нужно каждую пятницу строить отчет по выручке, маржинальности или операционным метрикам.
Исторический анализ и тренды. Хранилище накапливает данные за месяцы и годы. Аналитик может сравнить продажи за аналогичный период прошлого года, построить регрессию или рассчитать скользящее среднее.
Кросс-функциональная аналитика. Данные из разных производственных систем собираются в единую модель. Специалист может связать информацию о клиентах с финансовыми показателями и данными по цепочке поставок, не собирая разрозненные выгрузки вручную.
Самообслуживание бизнес-пользователей. Четкая структура и понятные названия таблиц позволяют менеджерам и маркетологам самостоятельно строить простые отчеты в BI-инструментах, не дергая аналитика по каждому поводу.
Соответствие регуляторным требованиям. Для финансового аудита или отчетности в ЦБ критично, чтобы данные были неизменяемыми, их происхождение — прослеживаемым, а расчеты — воспроизводимыми.
Однако если данные неструктурированы и их схема меняется слишком часто, если нужно быстро прототипировать гипотезу на сырых логах или работать с потоковыми данными реального времени — хранилище будет тормозить, а не помогать. В этих случаях нужен другой подход.
Слои хранилища данных
Обычно КХД строится послойно: каждый слой отвечает за свою задачу — загрузку, очистку, хранение или подготовку для анализа. Одна из самых распространенных схем включает три уровня.
1. ODS (Operational Data Store) — слой первичной загрузки данных, куда информация поступает из разных систем почти без изменений. На этом этапе сведения приводят к базовому техническому стандарту: унифицируются форматы дат, типы полей и структура записей.
2. DDS (Detailed Data Store) — ядро хранилища, где данные очищаются, связываются между собой и раскладываются по бизнес-сущностям. Именно здесь появляются факты, измерения, связи между таблицами и единые правила расчета метрик. DDS обычно строится по моделям Инмона или Кимбалла, но к ним мы еще вернемся позже.
3. Витрины данных (Data Marts) — специализированные наборы таблиц под конкретные задачи бизнеса. Например:
- витрина продаж;
- маркетинговая витрина;
- финансовая отчетность;
- продуктовая аналитика.
Для типового дашборда или еженедельного отчета аналитик идет именно в витрину. Это быстро, безопасно и не нагружает нижние слои.
Процессы ETL и ELT в DWH-хранилище
Данные не попадают в витрины напрямую. Прежде чем специалист увидит готовую таблицу в BI-системе, информация проходит через процессы загрузки и обработки.
ETL=Extract→Transform→Load
ETL расшифровывается как «извлечь, преобразовать, загрузить». Сначала данные забираются из источников. Затем очищаются и преобразуются: удаляются дубликаты, стандартизируются форматы, рассчитываются метрики, объединяются данные из разных систем. И только после этого загружаются в централизованное хранилище данных.
Долгое время этот подход оставался основным для КХД, потому что позволял загружать уже проверенную информацию. Но архитектуры развивались, и появился
ELT=Extract→Load→Transform
В этом случае сведения сначала загружаются в хранилище почти без изменений, а преобразования выполняются уже внутри самой платформы. Такой подход стал особенно популярным с развитием облачных технологий, где вычислительные ресурсы масштабируются значительно проще.
Понимание ETL/ELT-процесса нужно аналитику для того, чтобы знать, в какой момент данные обновляются, сколько времени занимает их подготовка и на каком этапе искать проблему, если в отчете что-то пошло не так.
Современный подход: Data Lake — что это такое
Допустим, аналитик открывает папку в облачном хранилище. Внутри — тысячи JSON-файлов с событиями из мобильного приложения. Никакой структуры нет, но где-то здесь лежат ответы на вопросы: почему пользователи удаляют приложение после третьего запуска и какие действия предшествуют отказу. Чтобы докопаться до истины, недостаточно написать SELECT. Нужно сначала понять, что вообще находится в файлах.
Data Lake (в переводе «озеро данных») — архитектурный подход, рассчитанный на хранение больших объемов сырых данных практически в любом формате.
Идея в том, чтобы сохранить все, что может когда-либо пригодиться, а структурировать тогда, когда появится конкретный вопрос. Здесь работает принцип schema-on-read: сведения хранятся в сыром виде, а структура накладывается в момент чтения, под конкретную задачу.
Озеро неструктурированных данных
Строится на объектных хранилищах, например, Amazon S3 или HDFS. Сведения попадают туда напрямую из источников, часто потоком, и хранятся в открытых форматах: Parquet, Avro, ORC, обычный CSV или JSON. Это дешево: стоимость хранения терабайта на порядок ниже, чем в классическом КХД, а масштабируется озеро практически бесконечно. Компании могут позволить себе хранить сырые данные за годы, не удаляя ничего и не агрегируя.
Но у гибкости есть обратная сторона. Никто не дает гарантий, что в полях — согласованные значения, что ключи уникальны, а временные зоны приведены к единому стандарту. Схема создается на лету: вы читаете файл и сами решаете, чему можно доверять.
Без правил управления и документации хранилище быстро превращается в болото. Чтобы озеро оставалось управляемым, не обойтись без каталога данных, соглашения об именовании, описания схем и ответственных за качество.
Когда аналитику нужен Data Lake
Этот подход полезен там, где данные слишком разнородны, поступают слишком быстро или их структура заранее не известна.
Озеро данных берет на себя следующие сценарии:
- хранение логов серверов и событий кликового потока — данные о действиях пользователей пишутся непрерывно и не терпят жесткой схемы;
- работа с частично структурированными данными — тот самый JSON, который в реляционную таблицу просто так не положишь;
- машинное обучение — моделям нужны сырые данные, а не агрегированные витрины;
- потоковая аналитика — когда реагировать нужно не раз в сутки, а в моменте;
- хранение больших исторических массивов — держать десятилетние архивы в DWH дорого, а в озере дешево;
- объединение данных из десятков разнородных источников.
А еще Data Lake позволяет держать данные про запас. Даже если компания пока не знает, как именно будет использовать информацию, ее можно сохранить в сыром виде и вернуться к анализу позже.
При этом для классической BI-отчетности Data Lake обычно менее удобен, чем КХД. Поэтому во многих компаниях озеро данных существует не вместо хранилища, а вместе с ним: первое используется для хранения и обработки сырья, а второе — для стабильной аналитики и отчетов.
Гибрид будущего: Data Lakehouse
Аналитик открывает один интерфейс и пишет SQL-запрос. Он обращается и к строгим реляционным таблицам, и к сырым JSON-файлам в озере. Информация возвращается за секунды, а результат можно сразу подставить в дашборд. То, что раньше требовало нескольких платформ и сложной интеграции между ними, теперь может работать внутри одного подхода.
Что такое Data Lakehouse и почему он появился
Это архитектура данных, которая объединяет черты корпоративного хранилища и озера данных. От первого берут ACID-транзакции, строгую схему, поддержку SQL и надежность для документации. От второго — масштабируемость, невысокая стоимость хранения и поддержка любых форматов данных.
Причина появления гибрида: компании захотели хранить информацию в дешевом озере, но при этом получать удобство BI и стабильность корпоративного централизованного хранилища данных без постоянного дублирования между разными системами.
Технически Lakehouse строится поверх объектного хранилища, но над сырыми файлами надстраивается слой метаданных и транзакционного управления. Он позволяет выполнять привычные операции, которые раньше были доступны только в реляционных базах: изменять отдельные записи, откатывать изменения, гарантировать согласованность при параллельных запросах.
Какие проблемы помогает решить Lakehouse
- Медленный доступ к большим массивам данных.
- Сложность работы с сырыми и неструктурированными данными.
- Разделение BI и ML на разные платформы.
- Хаос и отсутствие структуры в озере.
- Дублирование данных между системами.
- Сложности с управлением качеством сведений.
Примеры технологий
В основе большинства Lakehouse-платформ лежат открытые форматы таблиц — спецификации и реализации с открытым исходным кодом, которые организуют хранение файлов и метаданных и добавляют Data Lake свойства, раньше доступные только классическим КХД.
Одна из самых известных реализаций — Delta Lake, созданная Databricks. Delta использует транзакционный лог в объектном хранилище и обеспечивает ACID-транзакции, версионность (time travel) и управляемую эволюцию схемы. При работе в экосистеме Databricks и Apache Spark аналитик чаще всего столкнется именно с Delta.
Другой популярный формат — Apache Iceberg. Инициированный Netflix, проект заточен на очень большие аналитические таблицы и решает проблему масштабирования метаданных: manifest и snapshot-структуры позволяют быстро находить нужные файлы без сканирования всего каталога. Iceberg независим от движка и поддерживается в Spark, Trino, Flink и др.; его часто выбирают для облачных стеков, например в AWS.
Apache Hudi делает упор на инкрементную и потоковую загрузку, поддерживает концепции upsert и CDC и два режима работы — Copy-on-Write (чтение) и Merge-on-Read (быстрая запись). Проект возник в Uber и удобен для сценариев аналитики с минимальной задержкой.
Сравниваем три архитектуры для аналитика
Чтобы принимать осознанные решения, нужно сравнивать не абстрактные определения, а конкретные критерии, влияющие на повседневную практику: скорость доступа, качество данных, требуемые навыки, гибкость и стоимость.

Сравнительная таблица
| DWH | Data Lake | Lakehouse | |
| Тип данных | Структурированные, реляционные | Любые | Любые, с поддержкой схемы |
| Схема | Schema-on-write: жестко задана до загрузки | Schema-on-read: определяется в момент запроса | Эволюционирующая: схема задается, но может изменяться |
| Основной язык | SQL | Python, Scala, Spark | SQL + Python/Spark |
| Качество данных | Высокое, данные очищены и проверены | Зависит от источника, требует самостоятельной проверки | Высокое при настройке проверок, данные управляемы |
| Скорость запросов | Высокая для подготовленных витрин | Может быть низкой без оптимизации | Высокая при правильной организации |
| Регламентная отчетность | Идеально подходит | Неудобно, требует дополнительных инструментов | Подходит, но требует настройки |
| Ad-hoc анализ | Ограничен загруженными данными | Максимальная гибкость | Высокая гибкость с привычным SQL |
| ML и Data Science | Не предназначен | Основная среда | Удобен: единая платформа для ML и BI |
| Потоковая обработка | Ограничена или отсутствует | Поддерживается | Поддерживается нативно |
| Порог входа | Низкий: достаточно SQL | Высокий: нужны навыки программирования | Средний: можно начать с SQL |
| Стоимость хранения | Высокая | Низкая | Низкая (объектное хранилище) |
| Управляемость | Высокая: данные описаны, каталогизированы | Риск болота данных | Высокая при внедрении каталога и форматов таблиц |
| Версионность данных | Ограничена или требует специальных механизмов | Не предусмотрена | Встроена (time travel) |
| Типичный сценарий | Финансовая отчетность, KPI, дашборды для бизнеса | Исследование данных, ML, хранение архивов | Единая платформа для BI, ML и работы с сырыми данными |
Централизованное хранилище данных или озеро
Выбор зависит от задач компании, объема данных и зрелости аналитической команды.
Если компании нужны стабильная BI-отчетность, KPI и финансовая аналитика, классического КХД обычно достаточно.
Data Lake становится нужен, когда появляются большие объемы сырых и разнородных данных: логи, JSON, потоковые события или ML-задачи. В этом случае компании часто используют гибридный подход: DWH — для отчетности, озеро — для хранения и исследований.
Lakehouse объединяет возможности предыдущих подходов в одной платформе: позволяет работать и с BI, и с большими сырыми данными без постоянного дублирования инфраструктуры. Это следующий этап развития.
Подходы Инмона и Кимбалла
Современный аналитик редко проектирует хранилище с нуля. Но он работает с тем, что спроектировали до него, и от выбора архитектурного подхода зависит, насколько легко ему будет строить запросы и разбираться в модели данных. Два классических подхода — Инмона и Кимбалла — до сих пор определяют устройство большинства корпоративных хранилищ.
3NF (Инмон) vs звездные схемы (Кимбалл)
Билл Инмон рассматривает хранилище как единый источник истины для всей компании. Данные моделируются в третьей нормальной форме (3NF) — максимально очищенной от избыточности. Таблицы нормализованы: справочники вынесены отдельно, связи строгие, дублирования нет. Это подход «сверху вниз»: сначала проектируется общая модель предприятия, а уже под нее строятся витрины для разных отделов.
Ральф Кимбалл ставит во главу угла удобство конечного пользователя. Информация моделируется в форме звезд: в центре — таблица фактов с событиями и показателями, вокруг — таблицы измерений со справочными сведениями. Это подход «снизу вверх»: витрины строятся под конкретные задачи, а общая модель складывается из них постепенно.
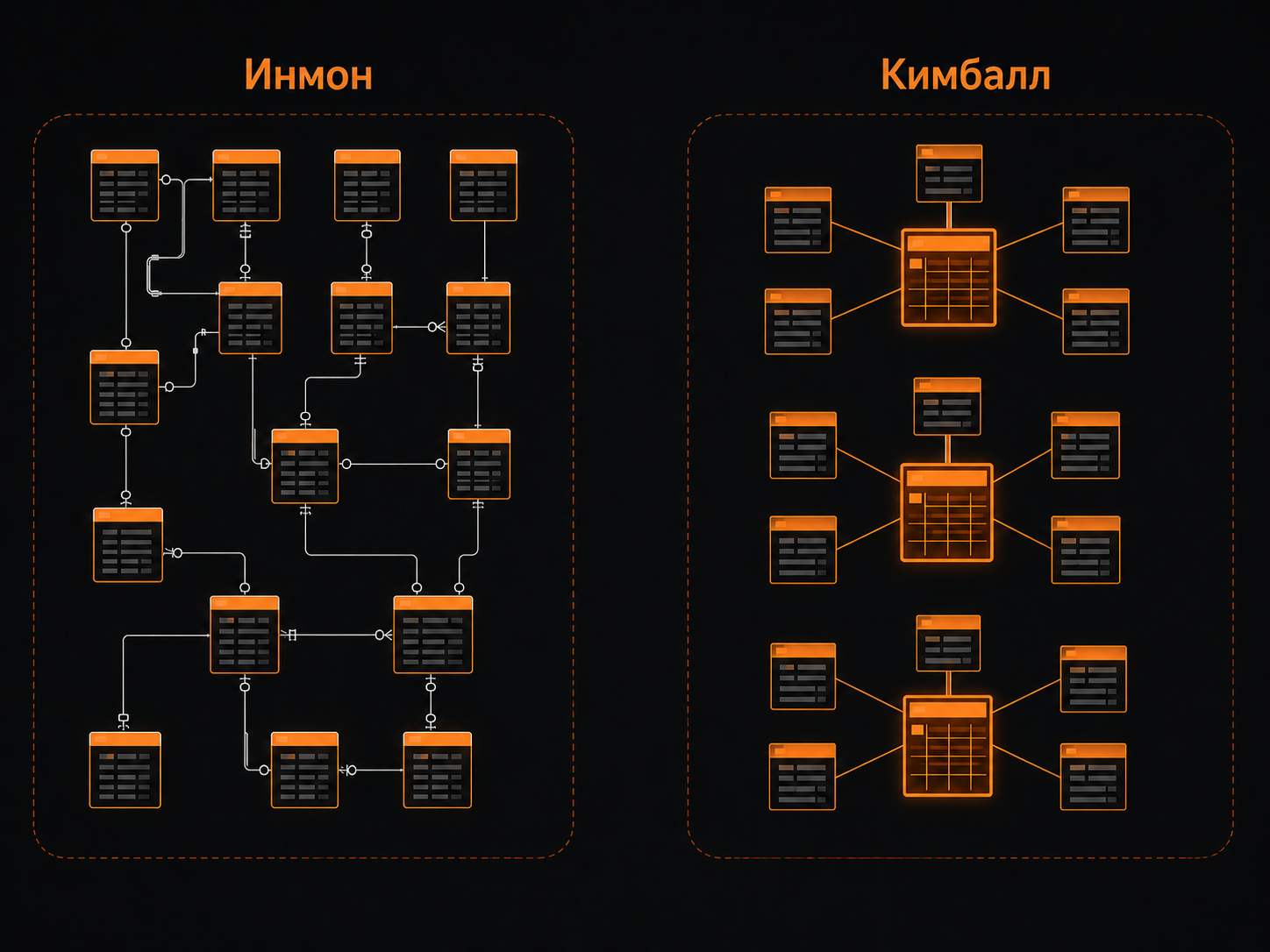
Как выбор подхода влияет на работу
Модель Инмона обычно выбирают организации, которым важны централизованное управление данными и строгая структура. Подход Кимбалла лучше подходит для BI-аналитики и быстрого построения витрин.
Современному аналитику не обязательно помнить все детали обеих методологий, но полезно уметь определить, с чем он имеет дело, и понимать, почему в одном проекте запрос пишется за пять минут, а в другом — за полчаса.
Как работают с Data Warehouse и Data Lake на практике
Теория отступает на второй план, когда аналитик открывает рабочий инструмент и пишет первый запрос.
SQL в DWH
Хранилище проектировалось именно под SQL-доступ: реляционная модель, оптимизатор запросов, индексы и предварительно просчитанные агрегаты.
Повседневная работа в DWH строится вокруг нескольких типовых сценариев.
- Построение дашбордов и регламентных отчетов. Аналитик пишет запрос к витрине, проверяет корректность цифр, визуализирует результат в BI-инструменте.
- Ситуативные запросы бизнес-пользователей: «Покажи продажи по регионам за последний квартал», «Сравни выручку по новым и старым клиентам».
- Проверка гипотез: данные уже структурированы, можно быстро проверить предположение, не отвлекаясь на подготовку данных.
Благодаря заранее подготовленной структуре запросы в КХД обычно предсказуемы. Именно поэтому большинство BI-инструментов — от Microsoft Power BI до Tableau — в первую очередь ориентированы на работу с Data Warehouse.
PySpark и фреймворки для Data Lake
Работа с озером начинается там, где SQL упирается в ограничения. Данные не подготовлены, схема не задана, а объемы таковы, что обычная БД не справится. Здесь нужен другой набор инструментов. Прежде всего PySpark — Python-интерфейс для Apache Spark.
С его помощью:
- масштабируемо обрабатывают большие массивы информации;
- читают и обрабатывают parquet- и JSON-данные;
- запускают очистку и трансформацию данных;
- формируют датасеты для аналитики и машинного обучения.
Также существуют фреймворки (программные платформы), упрощающие типовые операции. Например, DataFrame API позволяет работать с данными почти как с таблицами SQL, а Spark SQL — писать SQL-запросы прямо к файлам в озере.
Важно
Чтобы эффективно работать с PySpark, нужно понимать основы распределенных вычислений, уметь писать код на Python и разбираться в форматах хранения.
Тестирование DWH и качества сведений
Проверки часто встроены в сам сценарий загрузки: ETL-процессы отсеивают дубликаты, проверяют ссылочную целостность, следят за форматами. Но это не снимает с аналитика ответственности за финальную валидацию.
Важно проверить:
- Полноту данных.
- Корректность агрегатов. Например, сумма продаж по регионам должна совпадать с общей суммой продаж.
- Свежесть данных. Обновились ли витрины вовремя?
- Консистентность справочников. Нет ли дубликатов в измерениях, не появились ли новые категории без согласования и т.д.
Где учиться
Для тех, кто хочет получить фундаментальную подготовку, существует магистерская программа «Аналитика больших данных» — наш совместный проект с НИУ ВШЭ. В ней соединились академическая экспертиза одного из ведущих университетов России и прикладное понимание требований рынка.
Формат обучения — онлайн, что позволяет совмещать учебу с работой, при этом получая все льготы очной формы: отсрочку от армии, налоговый вычет, доступ к ресурсам НИУ ВШЭ. По окончании выдается диплом магистра государственного образца. Предусмотрен образовательный кредит под 3% годовых.
Заключение
Универсальной архитектуры хранения данных не существует. Аналитику не обязательно знать все, но важно понимать, в какой среде он работает и какие инструменты будут уместны. Мы погрузились в тему корпоративных хранилищ данных (КХД): что это такое в IT-сфере, чем обернулось противостояние Data Lake vs Data Warehouse и почему возник Lakehouse. Дальше вам важно углубляться в SQL, Python, PySpark, открытые форматы таблиц и облачные платформы.
