No-code → Low-code → Python: как быстро прототипировать RAG-ботов
Сегодня почти каждая компания хочет собственного ИИ-ассистента. Именно поэтому растет интерес к RAG-системам. Если упростить, RAG в ИИ — это способ научить модель искать информацию в ваших данных перед генерацией ответа. В статье разберем, как развивается такой проект от простого прототипа до полноценного решения на Python.
Содержание

Что такое RAG и зачем его прототипировать
Представьте корпоративный чат, в который сотрудник пишет: «Какие у нас правила оформления отпуска?» Вместо ссылки на папку с документами система сразу отвечает готовым текстом, опираясь на внутренний регламент компании.
RAG-технология — это подход, при котором языковая модель перед генерацией ответа сначала ищет информацию во внешних источниках: документах, таблицах, базах знаний или внутренних сервисах.
RAG (Retrieval-Augmented Generation) расшифровывается как генерация, дополненная поиском. Это процесс из трех шагов:
- Поиск. Ваш вопрос превращается в запрос, который ищет похожие фрагменты в базе документов.
- Извлечение. Система достает самые подходящие куски — параграфы из регламентов, инструкций, PDF-файлов.
- Генерация. Языковая модель получает эти фрагменты как контекст и на их основе пишет осмысленный ответ.
Главное преимущество такого подхода — возможность быстро подключить ИИ к собственным данным без обучения модели с нуля. Поэтому его сегодня активно используют для корпоративных помощников, поиска по документации, внутренних Copilot-систем и чат-ботов поддержки.
При этом большинство команд начинают не с полноценной разработки, а с прототипа. Сначала важно проверить саму идею: насколько качественно модель ищет информацию, понимает документы и отвечает на реальные вопросы пользователей. Именно здесь появляются три основных подхода к созданию RAG-ботов: no-code, low-code и Python.
Если вас интересует, как создать ИИ без кода, запишитесь на практический интенсив «RAG-боты и агенты LLM (большие языковые модели)». Вы пройдете путь от no-code сборки без программирования до локального приложения — шаг за шагом с поддержкой преподавателя.
No-code RAG: прототип за 1 день без программирования
Самый быстрый способ проверить идею. Вы не пишете код, не настраиваете серверы и не разбираетесь в тонкостях векторизации. Вы берете готовую платформу, загружаете документы и получаете работающего бота.
Что такое no-code платформы и кому они подходят
No-code платформа — это визуальный конструктор, где приложение или бот собирается из готовых блоков. Все детали уже подготовлены, остается соединить их в правильном порядке.
Блоки выглядят примерно так: «Загрузить документы» → «Найти похожие фрагменты» → «Отправить в языковую модель» → «Показать ответ». Вы настраиваете их мышкой, иногда заполняете пару полей вроде API-ключа, и бот готов к работе.
Кому и когда это подходит:
- Малому бизнесу и стартапам. Когда нет ни разработчиков, ни бюджета на них, но нужно быстро сделать полезный инструмент.
- Маркетологам, HR-менеджерам, аналитикам, руководителям — людям, которые отлично знают предметную область, но не умеют программировать.
- Для проверки гипотез. Перед тем как вкладывать серьезные ресурсы в разработку, нужно понять: а вообще решает ли такой бот чью-то реальную проблему? No-code дает ответ за пару дней, а не за месяцы исследований.
Если у вас уже есть документы и понимание задачи, работающий бот можно получить за 1–3 часа. Полноценный внутренний помощник, с которым уже начинают работать сотрудники — за 1–3 дня. Это рекордная скорость, недостижимая ни в одном другом подходе.
Потребуются минимальные ресурсы. Обычно хватает подписки на саму платформу (многие имеют бесплатный тариф для старта), API-ключа к языковой модели вроде OpenAI или Claude и, собственно, ваших документов. Сервер не нужен, настройка инфраструктуры не нужна, специфические технические знания не нужны. Вы открываете браузер и начинаете собирать.
Конечно, когда появляются запросы посложнее — интеграция с CRM, права доступа, нестандартная логика — подход нужно менять. Но на старте важно понять, работает ли вообще ваша задумка.
Обзор no-code инструментов для RAG
Чаще всего используют комбинацию нескольких сервисов: один отвечает за интерфейс, второй — за данные, третий — за автоматизацию или интеграции с языковыми моделями.
Bubble — один из самых популярных no-code конструкторов для веб-приложений. Если вам нужен не просто чат-бот в мессенджере, а полноценное веб-приложение с авторизацией, чатом, загрузкой документов и интеграцией с API языковых моделей, Bubble предлагает почти неограниченные визуальные возможности. По сути, это LEGO для создания SaaS-продуктов.
- Сильная сторона — гибкий визуальный интерфейс с поддержкой API и большим количеством плагинов.
- Минусы: сложные сценарии быстро становятся трудно поддерживаемыми, контроль над backend-логикой ограничен, а производительность зависит от платформы.
Glide делает ставку на максимально быстрый запуск приложений поверх таблиц и готовых данных. Если Bubble — это полноценная мастерская, то Glide — умный конструктор, где приложение собирается буквально из ваших Google Таблиц. Можно быстро сделать ИИ-поиск по базе инструкций, помощника для отдела продаж или внутренний FAQ-бот.
- Плюсы: очень низкий порог входа, молниеносный запуск и удобство для нетехнических команд.
- Минусы: меньше гибкости, ограниченная кастомизация RAG-логики и сложности с масштабированием под большие нагрузки или вычисления.
Airtable, по сути, гибрид таблицы, базы данных и конструктор серверной части приложения без кода. Сами по себе Airtable-таблицы не создадут RAG-бота, но они часто становятся фундаментом для хранения документов, организации базы знаний и каталогизации данных. Через интеграции и автоматизации инструмент подключается к языковым моделям.
- Плюсы: знакомый интерфейс таблицы, удобство структурирования данных и огромное количество интеграций.
- Минусы: Airtable не умеет самостоятельно искать релевантную информацию, а при работе с большими объемами данных упирается в ограничения.
Low-code RAG: баланс скорости и гибкости
Это промежуточный уровень между визуальным конструктором и полноценной разработкой. Вы все еще используете готовые инструменты, которые берут на себя большую часть технической работы. Но теперь можно вмешиваться в логику, писать фрагменты кода и точнее настраивать поведение системы.
Что такое low-code платформы и чем отличаются от no-code
Low-code платформы — это инструменты, которые сочетают визуальное проектирование с возможностью добавлять собственную логику, скрипты, API-запросы и автоматизации. Они требуют чуть больше технической подготовки, но дают намного больше гибкости по сравнению с программированием без кода.
| Характеристика | No-code | Low-code |
| Способ настройки | Только мышью, перетаскиванием блоков | Блоки + возможность писать скрипты и запросы |
| Работа с API | Готовые интеграции, что дали — тем и пользуемся | Можно подключаться к любым внешним сервисам, писать свои коннекторы |
| Контроль над логикой | Строго в рамках предусмотренных сценариев | Можно менять поведение системы: условия, фильтры, ветвления |
| Поиск и извлечение | Что внутри платформы — то и работает | Можно настраивать параметры поиска, добавлять переранжирование, экспериментировать |
| Порог входа | Не требует технических знаний | Нужно понимать API, JSON и основы скриптов |
| Время на прототип | Часы или дни | Дни или недели |
| Гибкость | Низкая | Средняя или высокая |
| Масштабируемость | Ограничена платформой | Хорошая, можно добавлять серверы, базы данных, кеширование |
Обзор low-code инструментов
n8n — один из самых мощных low-code инструментов для автоматизации на сегодняшний день. Если ваша компания не хочет, чтобы данные покидали контур, или требования безопасности не позволяют работать через облачные сервисы, n8n закроет этот вопрос.
- Плюсы: полный контроль над данными, возможность вставлять JavaScript-код между любыми этапами процесса и создавать сложные логические цепочки без ограничений стандартных модулей.
- Минусы: высокий порог входа, требуется понимание JavaScript и основ работы API, сложнее в освоении, чем у конкурентов.
Make — это облачный SaaS-сервис с одним из самых красивых и понятных визуальных редакторов на рынке. Если n8n создан для инженеров, то Make — для тех, кто ценит визуальную интуитивность.
- Плюсы: очень низкий порог входа, наглядная отладка, быстрое подключение популярных сервисов от Google Drive до Telegram. Идеален для быстрого создания RAG-сценариев.
- Минусы: кастомизация через код более ограничена, чем в n8n; меньше гибкости для нестандартных задач.
Yandex Workflows — инструмент из экосистемы Yandex Cloud, и в этом его главная особенность. Если ваша компания уже использует облачные сервисы Яндекса, например, хранение данных, виртуальные машины или YandexGPT, то Workflows становится естественным выбором.
- Плюсы: два способа описания процессов (визуальный конструктор и YAML-спецификация), версионирование через Git, глубокая интеграция с Yandex Tracker, Object Storage и облачными AI-моделями «из коробки».
- Минусы: жесткая привязка к одному облачному провайдеру, не подходит для инфраструктур на других решениях.
Архитектура RAG в low-code
Какую бы AI-платформу вы ни выбрали, внутри процесс всегда проходит три ключевых этапа.
- Векторизация — превращаем документы в числа
Документы, которые вы загружаете — PDF, заметки, страницы из Notion, — модель не понимает напрямую. Она работает с числами. Поэтому для начала нужно разбить документы на осмысленные фрагменты и превратить каждый в вектор, то есть в набор чисел, который отражает его смысл.
В low-code инструментах этот процесс обычно спрятан за блоком: «Загрузить документ» → «Создать эмбеддинги» (от англ. embedding — «встраивание»). Но вы можете влиять на параметры: размер фрагмента, способ разбиения текста, выбор модели для векторизации. От этих настроек напрямую зависит, насколько точно бот будет находить нужную информацию.
- Поиск — находим релевантные фрагменты
Когда пользователь задает вопрос, он тоже превращается в вектор. Затем система сравнивает этот вектор с векторами всех фрагментов документов и находит самые близкие по смыслу.
В low-code появляется гибкость, недоступная в no-code-подходе. Можно настроить: сколько фрагментов извлекать для каждого запроса, по какому алгоритму сравнивать векторы, нужно ли дополнительное переранжирование результатов. Например, система может сначала найти 10 потенциально подходящих фрагментов, а потом переранжировать их с помощью более точного алгоритма и оставить три лучших.
- Генерация — языковая модель пишет ответ
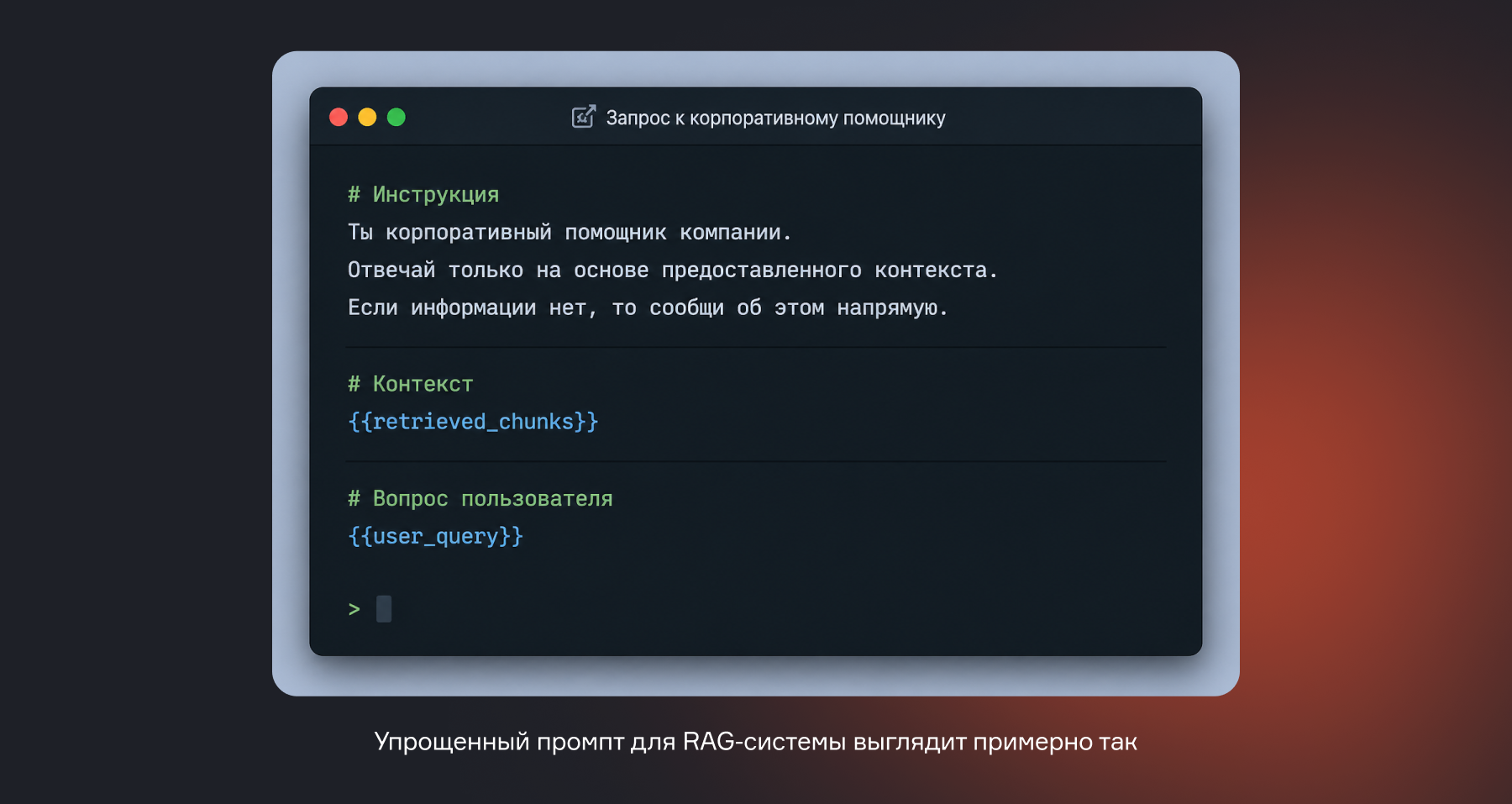
Найденные фрагменты текста отправляются в языковую модель вместе с вопросом пользователя. ИИ получает инструкцию вроде: «Ответь на вопрос, используя только следующий контекст». Дальше нейросеть пишет осмысленный ответ, опираясь на ваши документы.
Важно
В таких инструментах вы контролируете промпт, который летит в модель. Можно менять инструкцию, добавлять правила форматирования, настраивать поведение при отсутствии релевантного контекста. Это сильно повышает качество ответов по сравнению с no-code платформами, где промпт часто вшит и не редактируется.
Пример автоматического RAG-пайплайна в n8n
Допустим, компания регулярно выпускает новые инструкции и регламенты. Вместо ручной загрузки каждого PDF в базу знаний, система делает это автоматически. Новый файл появляется в папке — через несколько минут бот уже отвечает по нему.
Такие цепочки удобно собирать в n8n. Платформа позволяет визуально управлять процессом обработки, с возможностью вмешаться в логику кодом. Выглядит как конвейер:
Документ → Обработка → Чанкинг → Эмбеддинги → Векторная БД → LLM
- Шаг 1. Загрузка документа
Все начинается с триггера — события, запускающего сценарий. Это новый файл в Google Drive, загрузка через Telegram-бота, вложение в письме или Notion-документ. Сотрудник кладет файл в папку, а система автоматически его подхватывает.
- Шаг 2. Извлечение текста
Следующий узел получает содержимое: n8n работает с документами PDF, DOCX, TXT, HTML. Текст очищается, т.е. удаляются переносы, нормализуются символы, убираются служебные элементы. Здесь можно добавить JavaScript для кастомной обработки, например, для удаления колонтитулов и извлечения разделов.
- Шаг 3. Чанкинг (от англ. chunking, chunk — «кусок», «часть»)
Большие документы разбиваются на фрагменты по 500–1000 символов (токенов) с наложением для сохранения контекста. Low-code позволяет управлять логикой разбиения, в отличие от no-code с фиксированными настройками.
- Шаг 4. Генерация эмбеддингов
Каждый фрагмент идет в эмбеддинг-модель: OpenAI, Ollama, Sentence Transformers или Azure OpenAI. Текст превращается в вектор — набор чисел для семантического поиска.
- Шаг 5. Сохранение в векторную БД
Эмбеддинги сохраняются в Chroma, Qdrant, Weaviate или Pinecone. Теперь база знаний готова к семантическому поиску, когда система ищет не по ключевым словам, а по смыслу. Вопрос «как оформить отпуск» найдет фрагмент про «ежегодный оплачиваемый отдых», хотя слова формально разные.
- Шаг 6. Подбор контекста и генерация
Когда пользователь задает вопрос, система создает эмбеддинг запроса, ищет похожие фрагменты в векторной базе, передает найденный контекст в языковую модель и получает готовый ответ.
Интеграция LLM и управление промптами без глубокого кода
В большинстве low-code платформ интеграция языковых моделей LLM выглядит одинаково: пользователь задает вопрос, сценарий получает запрос, система добавляет найденный контекст, формируется промпт, запрос отправляется в модель и ответ возвращается пользователю. Подключают обычно OpenAI, Anthropic, Google Gemini или локальные модели через Ollama.
При этом low-code инструменты позволяют управлять промптами гибче, чем кажется на первый взгляд. Можно подставлять контекст из поиска, менять системный промпт в зависимости от роли пользователя, ограничивать стиль ответа, задавать формат JSON, добавлять память о предыдущих вопросах, управлять параметрами вроде креативности модели.
Можно быстро тестировать разные системные промпты, качество поиска, длину контекста, поведение разных моделей и точность ответов. Без этого этапа сложно понять, как RAG-система поведет себя в реальных сценариях.
Python RAG: полный контроль
No-code и low-code платформы — это искусство разумных компромиссов. Вы жертвуете контролем ради скорости, миритесь с ограничениями ради простоты. Но в какой-то момент компромиссы перестают быть разумными.
Когда low-code перестает хватать
Обычно это происходит не сразу. Сначала система работает для небольшой команды или одного отдела, но потом нагрузка и требования растут:
- документов становится слишком много;
- пользователи начинают активно пользоваться ботом;
- появляются сложные сценарии доступа;
- бизнесу нужна высокая точность ответов;
- растут расходы на API и инфраструктуру.
В этот момент оказывается, что визуальных блоков и готовых интеграций уже недостаточно. Появляется потребность управлять каждым слоем системы: от поиска документов до логики генерации ответа. Промпты усложняются, процессы множатся — и команды переходят на Python.
Основной стек
Когда RAG-проект переходит в полноценную разработку на Python, вместо визуальных блоков появляется набор специализированных инструментов. Каждый из них отвечает за свою часть системы: поиск документов, хранение данных, работу с LLM и построение логики бота. Рабочий стек укладывается в простую формулу:
фреймворк для оркестрации + векторная база + языковая модель
- Фреймворки
LangChain — универсальный конструктор для работы с языковыми моделями. Он предоставляет готовые цепочки для загрузки документов, разбиения на фрагменты, создания эмбеддингов, поиска и генерации. Сильная сторона — возможность строить сложные цепочки агентов, когда бот не просто отвечает, а принимает решения, вызывает внешние API и выполняет многошаговые инструкции.
LlamaIndex изначально создавался именно для RAG, и работа с данными здесь выведена на первый план. Загрузка документов из десятков источников, гибкая индексация, переранжирование, древовидные структуры для навигации по длинным документам. Часто команды используют их вместе: LlamaIndex для индексации и поиска, LangChain для оркестрации и агентов.
- Векторные базы
После генерации эмбеддингов их нужно где-то хранить и быстро по ним искать. Обычная база данных плохо подходит для поиска смысла в тексте. Поэтому в RAG используют векторные БД.
Chroma — легкая база, которая запускается за минуту. Установил библиотеку, создал коллекцию, добавил векторы — и можно искать. Никаких серверов, минимум настройки. Chroma выбирают для локальных проектов, прототипов, обучения и небольших систем.
Qdrant — решение с поддержкой фильтрации по метаданным, сегментирования коллекций, продвинутых алгоритмов поиска и высокой производительности под нагрузкой. Подходит, если документов очень много; нужен быстрый поиск; важна масштабируемость; есть высокие нагрузки; требуется фильтрация и сложная логика поиска контекста.
- Языковые модели
Для генерации ответов и создания эмбеддингов нужна LLM модель.
OpenAI — самый простой вход: API-ключ, пара строк кода, и модель отвечает. Качество высокое, но данные уходят на сторонний сервер, а стоимость растет с нагрузкой.
Ollama решает обе эти проблемы. Это инструмент для запуска открытых моделей прямо на вашем сервере. Все данные остаются внутри компании, стоимость предсказуема, и вы не зависите от доступности облачного API. Минус — нужен сервер с GPU для хорошей скорости, но для небольших проектов хватает и CPU.
Архитектура Python RAG
Главное отличие Python-архитектуры от low-code заключается не в наборе шагов. Шаги те же. А в том, что теперь вы не ограничены рамками визуального редактора. Любой этап можно разобрать, пересобрать под свои требования и оптимизировать.
1. Индексация документов
Все начинается с загрузки. В отличие от low-code, где вы указывали папку, здесь нужно самостоятельно решать, откуда брать данные. Это могут быть PDF из корпоративного хранилища, страницы из Notion, база знаний в Confluence, письма из почты, записи из CRM. Python-библиотеки вроде LlamaIndex дают готовые коннекторы к десяткам источников, но теперь вы можете написать свой загрузчик для любого специфического формата.
2. Чанкинг
Документы нужно разбить на фрагменты. Казалось бы, режь по 500 символов и все. Но на практике от стратегии чанкинга качество ответов зависит сильнее, чем от выбора модели. Можно разбивать по абзацам, можно по заголовкам с сохранением иерархии, можно с перекрытием в 100 символов, чтобы мысль не обрывалась на середине. Можно делать родительские и дочерние фрагменты-чанки: маленькие для поиска, большие для контекста. Python дает полную свободу экспериментировать и подбирать стратегию под конкретные документы. Юридические тексты разбиваются не так, как техническая документация, а та — не так, как диалоги из поддержки.
3. Эмбеддинги
Каждый чанк превращается в вектор. Вы выбираете модель для эмбеддингов под свою задачу: OpenAI ada-002 для английского, text-embedding-3 для мультиязычности, или открытые модели через Sentence Transformers, если данные нельзя отправлять вовне. Здесь же решается вопрос с метаданными: к каждому чанку можно прикрепить дату, автора, источник, категорию — все, что потом пригодится для фильтрации при поиске.
4. Поиск релевантных данных
Когда пользователь задает вопрос, он тоже проходит через эмбеддинг-модель и превращается в вектор. Дальше происходит поиск по векторной базе. Но в Python-архитектуре вы можете комбинировать семантический поиск с ключевым, добавлять фильтры по метаданным, настраивать пороги релевантности. А главное — после первичного поиска можно включить переранжирование: специальная модель заново оценивает найденные фрагменты и переставляет их по точности соответствия вопросу.
5. Сборка ответа
Отобранные фрагменты вместе с вопросом пользователя и системным промптом отправляются в языковую модель. Но теперь вы контролируете и этот этап. Можно:
- добавить историю диалога для сохранения контекста;
- обрезать слишком длинный контекст по скользящему окну;
- отправлять запрос не в одну модель, а в две — дешевую для черновика и дорогую для финального ответа.
Все это снижает стоимость и повышает качество, но требует кода.
Пример кода: RAG-бот за вечер на FastAPI + ChromaDB
Базовый прототип можно собрать буквально за вечер, если использовать готовые библиотеки. Покажем сильно упрощенный пример минимального RAG-сервиса на:
- FastAPI,
- ChromaDB,
- OpenAI API.
Такой бот умеет сохранять документы, искать релевантные фрагменты, передавать контекст LLM и возвращать ответ пользователю.
На этапе подготовки установим зависимости.

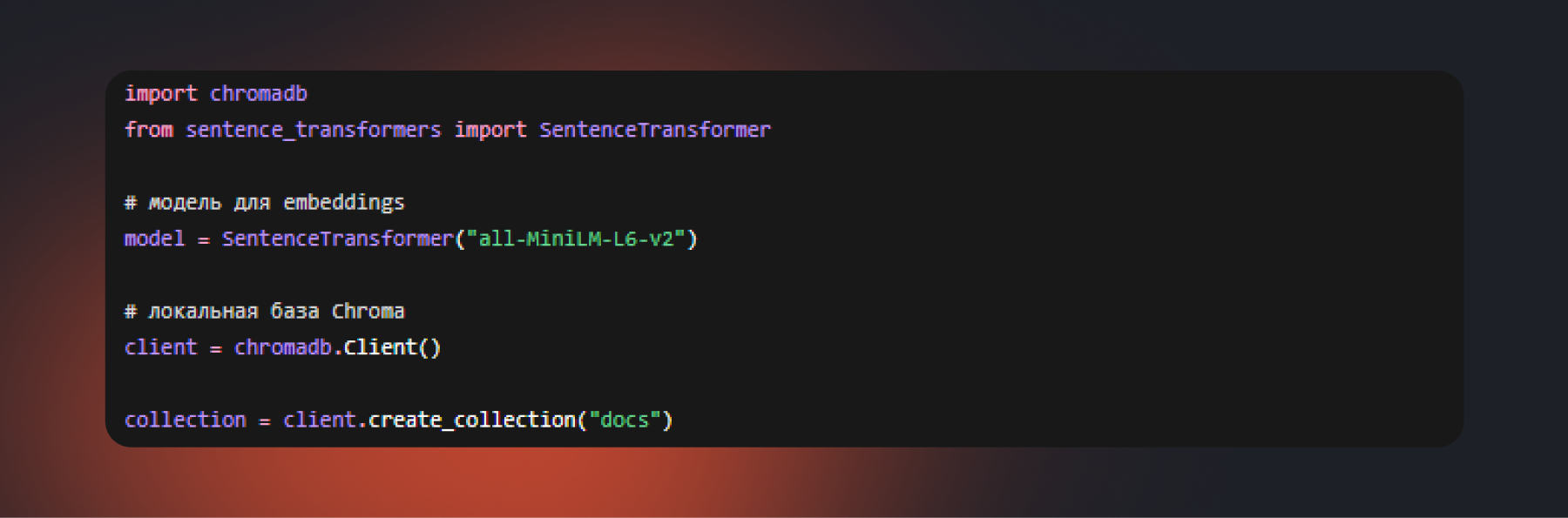
Шаг 1. Создаем векторную базу
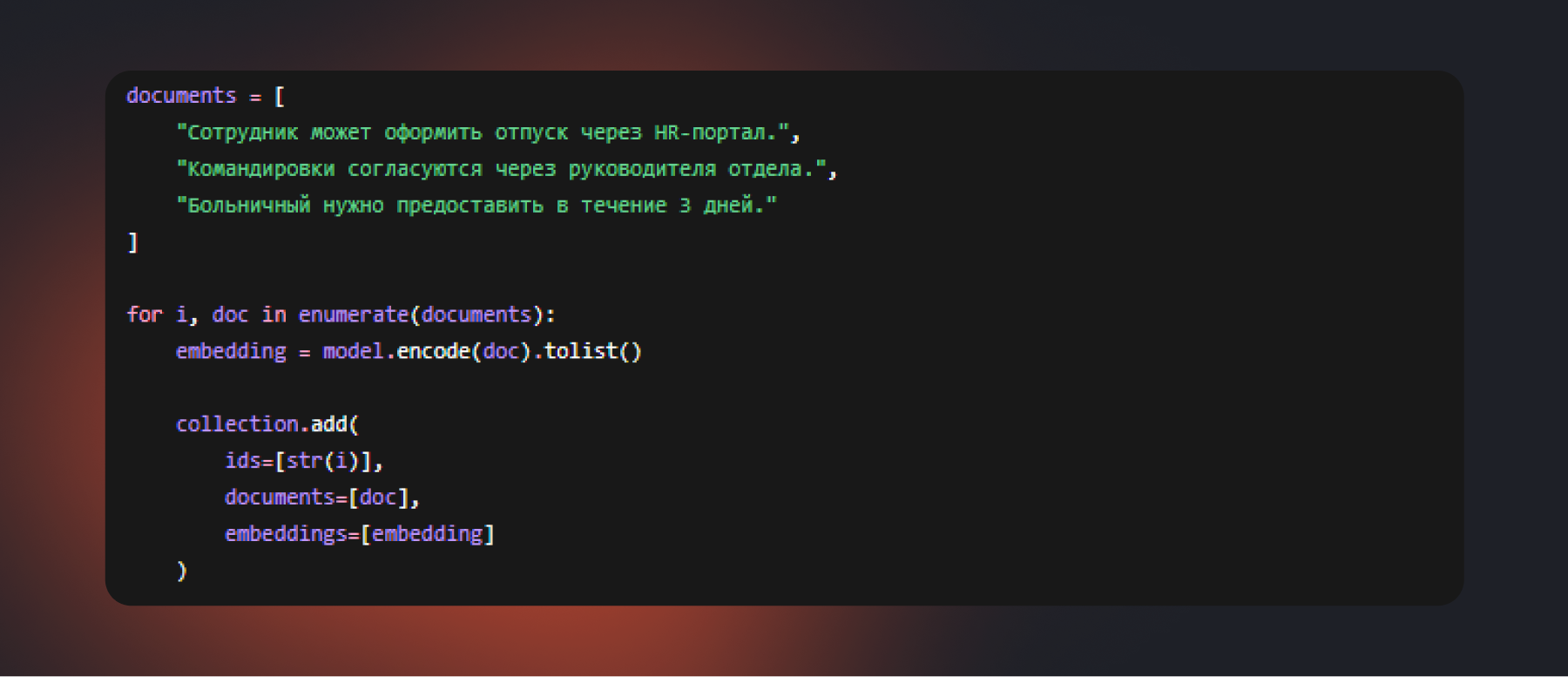
Шаг 2. Загружаем документы
Шаг 3. Настраиваем поиск
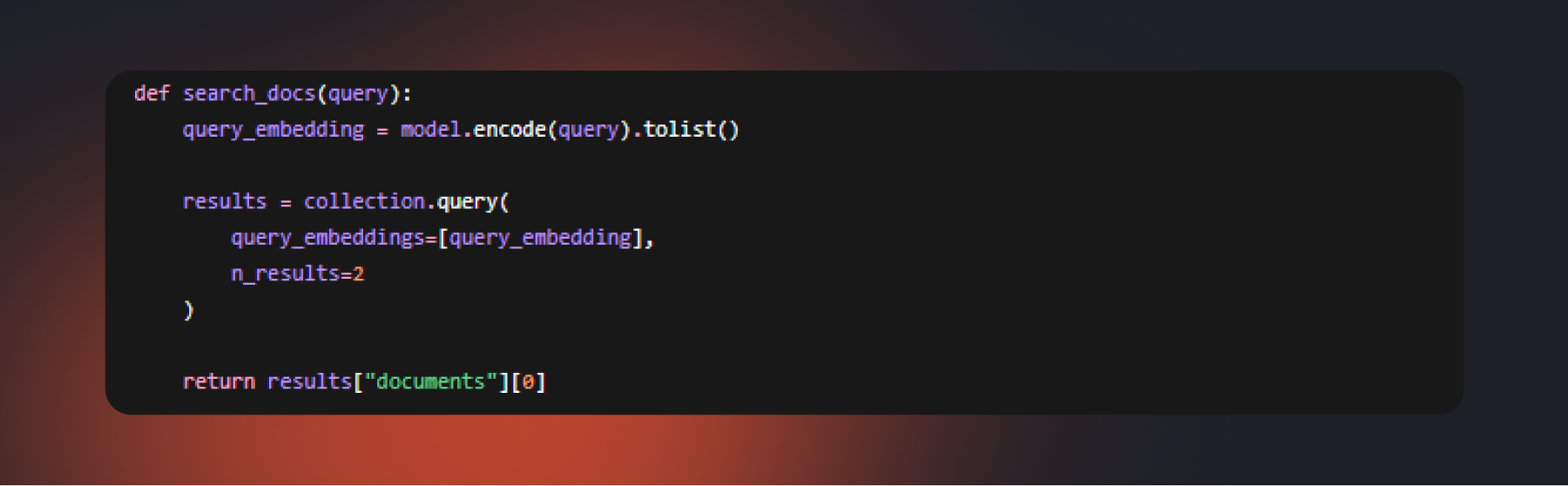
Теперь бот умеет находить релевантные фрагменты. Например:

Вернёт:

Шаг 4. Подключаем OpenAI

Шаг 5. Генерация ответа
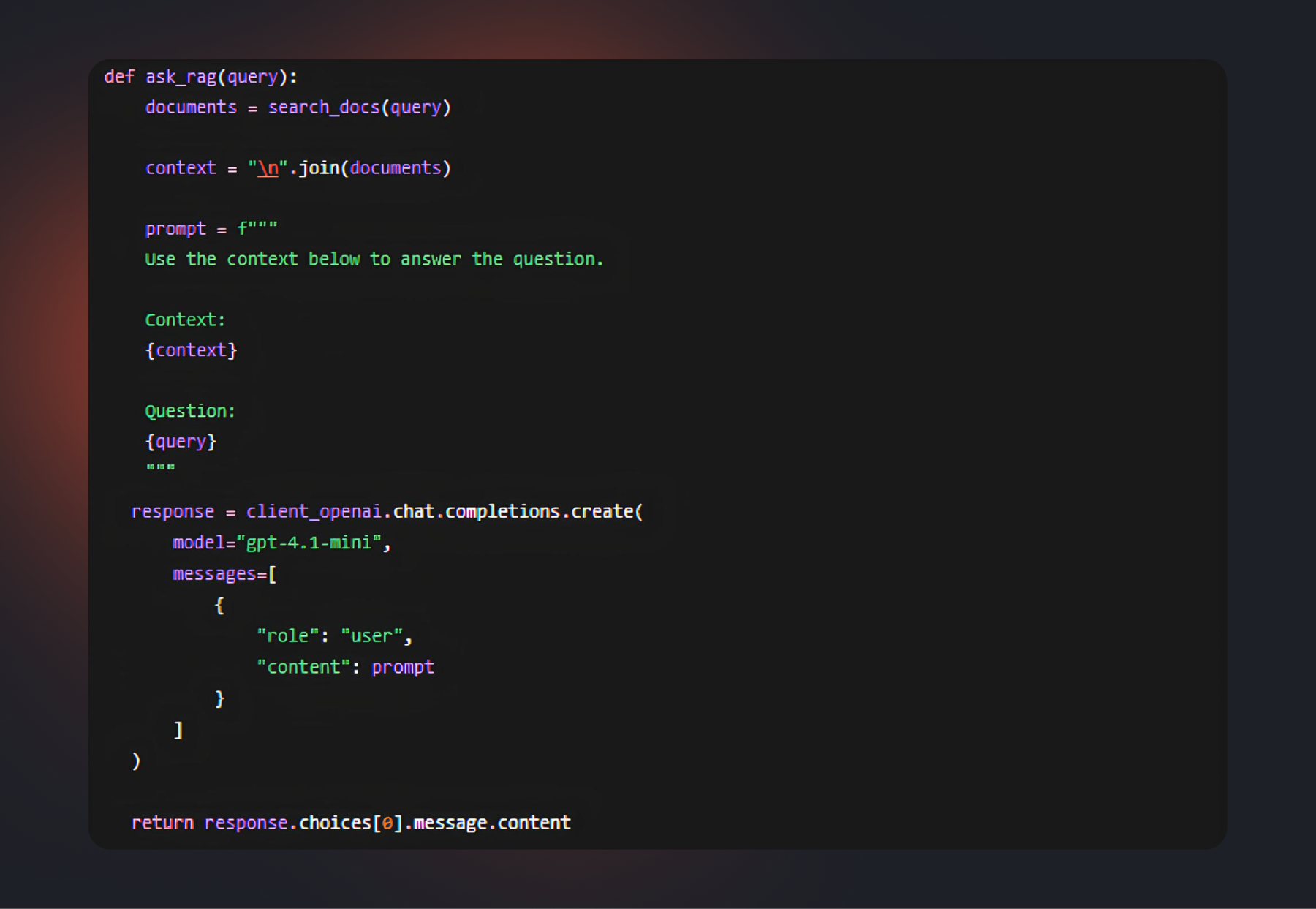
Шаг 6. Делаем API через FastAPI

Запускаем сервер

После запуска можно отправлять запросы.

Траектория перехода: куда расти от прототипа
Три подхода, которые мы разобрали, — это естественная лестница развития RAG-проекта. Переходить на следующую ступень нужно тогда, когда предыдущий уровень перестал справляться. Соберем общую картину.
- Этап 1. Проверка идеи
Вы пока не уверены, что RAG-бот вообще решает чью-то проблему. Может, документов слишком мало и проще искать по ним вручную. Может, сотрудники не будут писать вопросы боту. На этом этапе лучший выбор — no-code. Бюджет минимален, технические требования нулевые, скорость — максимальная. Если идея не взлетает, вы потеряли день, а не месяцы разработки.
- Этап 2. Первые реальные пользователи
Прототип прижился. Сотрудники спрашивают бота про командировки, HR-отдел хочет добавить свои инструкции, руководитель просит подключить мессенджер. Появляются первые запросы на интеграции и гибкость, которые no-code платформа закрывает с трудом или не закрывает вовсе. Это сигнал к переходу на low-code. Здесь вы настраиваете сценарий под себя, подключаете внешние сервисы и получаете систему, которая уже близка к релизу. Большинство корпоративных RAG-проектов живут именно на этом уровне и прекрасно себя чувствуют.
- Этап 3. Масштабирование
Проект вырос настолько, что low-code платформа становится узким горлышком. Документов тысячи, пользователей сотни, время ответа критично, требования безопасности жесткие, а стоимость подписки на платформу сопоставима с зарплатой разработчика. В этот момент команда пишет архитектуру на Python: свой сервер, своя векторная база, свои цепочки действий с переранжированием и мониторингом. Это уже не прототип — это продукт.
Важно
Не каждый проект обязан проходить все три этапа. Многие полезные RAG-боты начинаются на no-code и там же заканчиваются, решив свою задачу. Другие вырастают до low-code и остаются там на годы. И лишь небольшая часть доходит до Python — когда по-другому уже нельзя.
Заключение
Самая дорогая ошибка в разработке RAG-систем — начать с Python, когда достаточно no-code. И самая болезненная — застрять на no-code, когда проект давно просит полноценной архитектуры. Помните: каждый уровень хорош в свое время. Не стройте дом, если вам нужна квартира на месяц. Хороший вопрос, который стоит задать себе: «На каком этапе мой проект и что сейчас важнее — скорость, гибкость или контроль?» Честный ответ сэкономит недели работы и тысячи рублей.
