Дизайн-документ в машинном обучении: как спроектировать систему
До 85% проектов в сфере машинного обучения (ML) не доходят до реального использования. Проблема не в том, что модели плохо учатся, а в том, что их учат в вакууме. Как не стать частью печальной статистики? В этой статье говорим о внедрении искусственного интеллекта и машинного обучения. Разберем, как грамотный дизайн-документ помогает построить мост между сырой моделью и продуктом, который приносит пользу.
Содержание

Что такое проектирование ML-систем и зачем оно
Проектирование ML-систем (ML System Design) — дисциплина, которая находится на стыке машинного обучения и программной инженерии. Это процесс создания архитектуры продукта, в котором модель машинного обучения — не просто красивый алгоритм в ноутбуке, а полноценный рабочий компонент. Чтобы он приносил пользу, нужно спроектировать все, что его окружает:
- Откуда берутся данные и как очищаются?
- Как модель получает запросы и отдает предсказания?
- Как мы поймем, что она стала хуже работать?
- Как ее обновлять, не останавливая весь сервис?
Дизайн-документ (Design Document) — результат проектирования: техническая карта, которая описывает, как все будет устроено, и помогает не упустить критически важные детали до того, как команда напишет первую строчку кода.
Если хотите научиться создавать эффективные интеллектуальные системы и поддерживать их надежную работу, пройдите курс «ML Design: Основы проектирования систем машинного обучения». Студенты учатся у практиков индустрии и за 13 недель получают целостное понимание основ этой перспективной дисциплины, от архитектуры до интеграции.
Отличия от классической разработки
В традиционном программировании мы пишем четкие инструкции: «если случилось А, сделай Б». В машинном обучении (Machine Learning, ML) все иначе — мы создаем систему, которая обучается на данных. А данные имеют привычку меняться.
Главные отличия
- Непредсказуемость
Код можно отладить до идеала. Поведение модели на новой информации только оценивают вероятностно. Она может ошибаться так, как обычный код никогда не ошибется.
- Зависимость от данных
Хорошая ML-система держится на трех китах: код, модель и данные. Если в обычном сервисе база данных — это просто хранилище, то в здесь данные — топливо, качество которого напрямую определяет качество работы всего продукта.
- Дрейф и устаревание
Обычный код работает одинаково год за годом. Модель, обученная сегодня, через полгода может поглупеть, потому что изменилось поведение пользователей или экономическая ситуация. Система должна это отслеживать и уметь переобучаться.
В чем разница между ML-проектом и ML-продуктом
ML-проект — это исследование. Оно должно показать, что задачу в принципе можно решить с помощью машинного обучения. Итогом такой работы обычно становится ноутбук с кодом, обученная модель и хорошие показатели качества на тестовых данных. Архитектура здесь простая: данные → ноутбук → метрика качества.
ML-продукт — это инженерное решение. Его цель — приносить пользу пользователям и бизнесу. Результатом работы здесь становится рабочий сервис, который стабильно выдерживает нагрузку, масштабируется и помогает зарабатывать деньги или снижать расходы.
В интервью с Армандом Айрапетяном, руководителем платформы Ozon Crowd, как раз обсудили, как запускать ИИ-решения без лишней спешки и выстраивать процессы вокруг данных еще до обучения модели.
От бизнес-идеи к ML-задаче
Распространенный сценарий провала выглядит так: бизнес хочет «нейросеть, как у всех», специалисты год колдуют над архитектурой, а в итоге оказывается, что вопрос полностью закрывал обычный скрипт на пять строк кода.
Все из-за неверной постановки задачи. Прежде чем писать первую строчку кода или открывать ноутбук, нужно пройти два критически важных этапа: проверить, нужен ли здесь ML вообще, и правильно перевести бизнес-метрики на язык машинного обучения.
Уточнение требований
Иногда менеджмент говорит о внедрении искусственного интеллекта и машинного обучения просто потому, что это модно. Вот несколько частых ситуаций, когда не нужно усложнять.
- Задача решается простой эвристикой.
Если вы хотите рекомендовать пользователю товары, а у него просто день рождения — достаточно баннера «С днем рождения! Скидка 20% на торты». Модель тут не нужна.
- Нет данных или они слишком грязные.
Если информации недостаточно, модели будет нечему обучиться. Иногда проще собрать нормальную статистику за год, чем полгода мучиться с кривым алгоритмом.
- Цена ошибки слишком высока.
Есть задачи, где лучше жесткое правило, чем вероятностное предсказание. Например, в платежных системах: если сумма чека превышает остаток на счете, то транзакция отклоняется. Тут не нужно гадать, одобрить или нет.
- Требуется стопроцентная объяснимость.
Регуляторы, например, в банках или медицине часто требуют точного обоснования каждого решения. Модель машинного обучения — это «черный ящик». Иногда проще написать десяток правил и под каждое подвести юридическую базу, чем пытаться объяснить, почему градиентный бустинг решил именно так.
Перевод бизнес-метрик в ML-метрики
Когда вы убедились, что ИИ действительно нужен, важно избежать недопонимания между бизнесом и командой разработки.
Разберем на примере метрики с рекомендательной системой в интернет-магазине.
- Бизнес-метрика: рост выручки, увеличение среднего чека.
- Что просит бизнес: показывать пользователям то, что они точно купят.
Если ученый по данным просто начнет повышать долю правильных ответов (accuracy), он может натренировать модель рекомендовать только хиты, т.е. товары, которые и так все покупают. Цифры будут высокими, но бизнес не получит роста, ведь мы просто показываем всем одно и то же.

Нам важны не просто клики, а покупки. Значит, главной метрикой в ML будет не accuracy, а точность среди первых K рекомендаций (precision@k).
Алгоритм перевода
- Услышьте от бизнеса глобальную цель (деньги, лояльность, скорость).
- Поймите, какое действие пользователя к этой цели ведет (покупка, клик, возврат в сервис).
- Найдите способ зашить это действие в ML-метрику.
- Договоритесь, чем готовы жертвовать ради главной цели.
Только пройдя этот путь, можно начинать проектировать систему. Иначе велик риск создать идеальную с математической точки зрения модель, которая будет бесполезна для бизнеса.
Структура ML-проекта
Модель — деталь большого механизма. Чтобы система работала и приносила пользу, она должна состоять из нескольких ключевых компонентов.
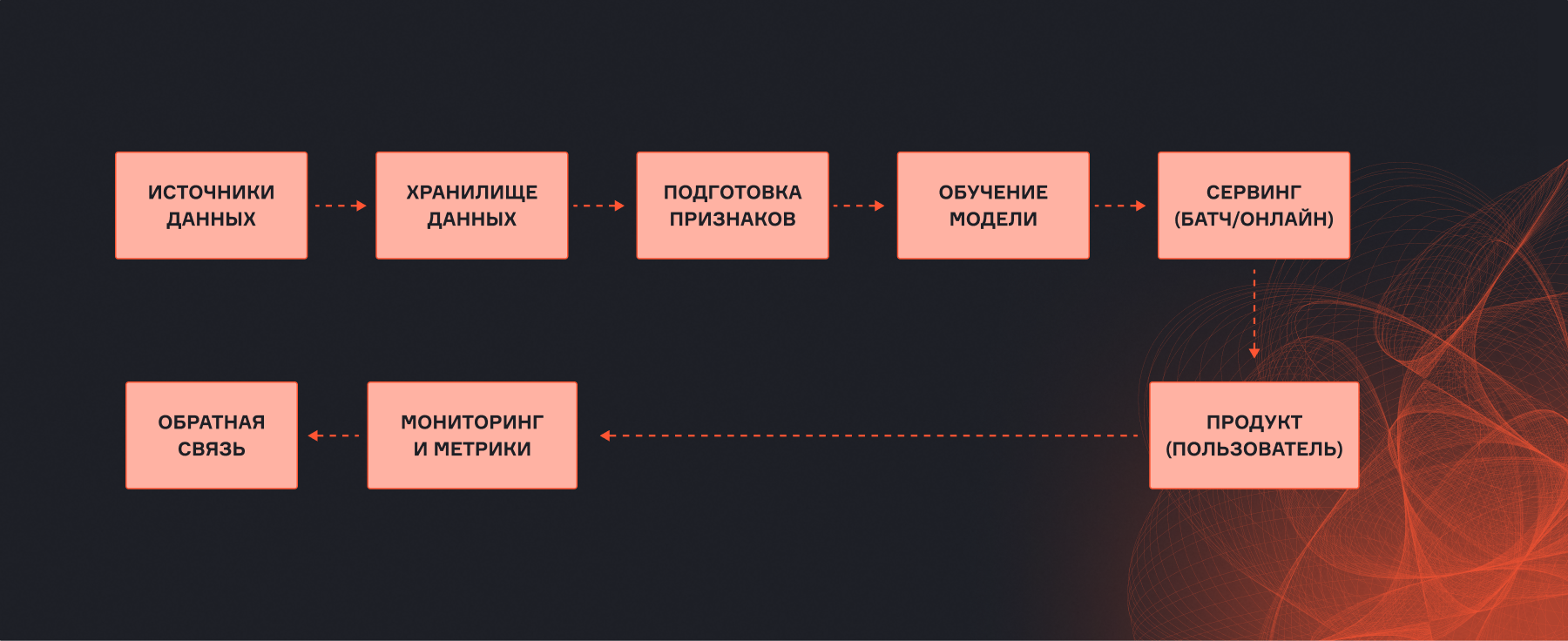
Источники данных
- Клиентская база (данные о пользователях из CRM-системы).
- Поведенческие логи (что пользователь смотрел, на что кликал, что положил в корзину).
- Внешние ресурсы (курсы валют, погода, данные из открытых источников).
На этом этапе главное — настроить стабильный конвейер сбора информации и убедиться, что ничего не теряется по пути.
Хранилище данных (Data Lake / DWH)
Сырые данные нужно где-то складировать. Обычно для этого используют озера данных (Data Lake) или витрины (Data Warehouse). Здесь данные живут в первозданном виде или после легкой первичной обработки. Важно, чтобы хранилище позволяло эффективно выгружать большие объемы сведений для обучения.
Подготовка (Feature Engineering)
- Очистку данных от мусора и выбросов.
- Заполнение пропусков.
- Создание признаков (фичей) — перевод сырых данных в формат, понятный модели.
В хорошей архитектуре этот процесс часто выносят в хранилище признаков (Feature Store). Сервис хранит подготовленные фичи и умеет подавать их одинаково быстро и для обучения, и для реальных предсказаний. Это спасает от ситуации, когда модель учится на одних данных, а в жизни получает другие.
Оркестрация и обучение (Training Pipeline)
Нужен конвейер, который автоматически:
- Забирает подготовленные данные.
- Запускает эксперименты с разными гиперпараметрами.
- Обучает несколько версий модели.
- Проверяет качество на отложенной выборке.
- Сохраняет артефакты (веса, метаданные) в реестр моделей.
Процесс может запускаться по расписанию (например, раз в сутки) или по событию (появились новые данные).
Обслуживание моделей (Model Serving)
Обученная модель должна отвечать на запросы. Есть два основных подхода.
- Онлайн-сервинг (микросервис). Подходит для рекомендаций в моменте или проверки платежей.
- Пакетный расчет. Подходит для рассылок или аналитических панелей-дашбордов.
Подробнее мы разберем эти подходы далее в статье.
Логика продукта и API (Product Integration)
Сырое предсказание нужно обернуть в бизнес-логику.
Если модель выдала вероятность покупки 0.8, но это товар из категории 18+, а пользователю 16 лет — не показываем.
Если ML-сервис упал и не отвечает, нужно отдать заглушку или сохраненные рекомендации, чтобы сайт продолжал работать.
Мониторинг и обратная связь
Модели деградируют. Нужно постоянно следить за:
- Техническими метриками: время ответа сервиса, количество ошибок.
- ML-метриками: не изменилось ли распределение предсказаний? Не упало ли качество?
- Бизнес-метриками: покупают ли люди то, что мы им рекомендуем?
Кроме того, нужно собирать данные от пользователей: купил — не купил, досмотрел — не досмотрел. Эти данные становятся новой порцией информации для дообучения модели. Замыкая этот круг, мы получаем самообновляющуюся систему.
Важно
Дизайн-документ — это инструмент, в котором вы описываете, как именно каждый из семи компонентов будет реализован в вашем проекте. Он помогает увидеть дыры в архитектуре до того, как они стали проблемой в реализации.
Проектируем данные и метрики
Если вы неправильно спроектируете, что и как измерять, и откуда брать обратную связь, вся система будет работать вслепую.
В этом разделе разберем три ключевых вопроса: как выбрать метрики качества ML, чем отличаются онлайн- и офлайн-измерения, и как спроектировать сбор данных, чтобы алгоритм мог учиться на своих ошибках.
Что такое метрики качества ML
Это цифры, которые говорят нам, насколько хорошо модель решает свою задачу.
| Тип задачи | Пример | Классические метрики | Нюанс |
| Классификация | Спам или не спам |
| Если спама 1% от всех писем, можно просто все помечать как «не спам» и получить accuracy 99%. Но пользы ноль. Здесь важнее precision (чтоб не пометить важное письмо как спам) или recall (чтоб точно поймать все спам-рассылки). |
| Ранжирование | Поисковая выдача |
| Важен не просто факт попадания, а порядок, чтобы самое релевантное было наверху. |
| Регрессия (предсказание числа) | Цена квартиры, температура |
| Смотрим, насколько сильно модель ошибается. |
| Рекомендательные системы | «Вам может понравиться» |
| Важно угадать и показать что-то новое, а не только хиты. |
В дизайн-документе нужно зафиксировать не просто выбранную метрику, а почему выбрана именно она и какое значение мы считаем успехом.
Онлайн или офлайн
Офлайн-метрики — то, что мы посчитали на исторических данных.
- Что это: качество модели на отложенной тестовой выборке.
- Где считаются: в ноутбуке, в процессе обучения
- Плюсы: быстрые, дешевые, можно посчитать до запуска.
- Минусы: не учитывают реальное поведение пользователей и контекст.
Онлайн-метрики — то, что реально происходит с пользователями. Например, конверсия в покупку, средний чек, время, проведенное в сервисе.
- Что это: как изменение поведения модели влияет на бизнес-показатели.
- Где считаются: на реальных пользователях.
- Плюсы: показывают реальную ценность для бизнеса.
- Минусы: требуют времени на накопление данных, на них влияет много внешних факторов.
Хороший дизайн-документ фиксирует обе группы. На офлайне проверяем модель до релиза. А за онлайном следим после.
Проектирование сбора данных для обратной связи
Обратная связь (фидбек) — это информация, что произошло после предсказания модели. Сбылось? Например:
- Модель порекомендовала товар — пользователь купил (хорошая обратная связь) или проигнорировал (нейтральная).
- Модель одобрила кредит — клиент выплатил (хорошо) или обанкротился (плохо).
Обратная связь часто приходит с задержкой и в искаженном виде. Если вы не продумаете, как ее собирать, хранить и подмешивать в новые данные для обучения, модель никогда не сможет учиться на своих ошибках.

Выбор архитектуры
Один из ключевых инженерных вопросов при внедрении машинного обучения: как именно модель будет отдавать предсказания?
Пакетный режим (батч, Batch Inference)
Это самый простой для реализации и самый надежный способ. Модель запускается по расписанию (раз в час, раз в сутки, раз в неделю), обсчитывает всех пользователей или все объекты разом, и складывает готовые предсказания в базу данных. А когда пользователь заходит на сайт, сервер просто забирает готовый результат из этой базы.
Онлайн-режим (Real-time / Online Inference)
Здесь модель живет в отдельном сервисе (обычно это микросервис на языке Python, завернутый в контейнер). Когда пользователь совершает действие, сервис отправляет запрос к этому микросервису, модель в реальном времени обсчитывает данные конкретного пользователя и возвращает предсказание.
Гибридный подход
Классический пример — рекомендации в интернет-магазине.
Батч. Раз в день считается модель, которая анализирует историю покупок всех пользователей и строит профили интересов. Результат кладется в базу.
Онлайн. Когда пользователь заходит на сайт и смотрит конкретный товар, легковесная модель в реальном времени учитывает этот просмотр и корректирует выдачу: «Раз вы смотрите красные кроссовки, вот вам еще похожие модели в наличии».
При выборе архитектуры в дизайн-документе нужно ответить на три вопроса:
- Насколько критична задержка?
- Как часто меняются данные, на основе которых мы предсказываем?
- Какова стоимость ошибки?
В документации обязательно зафиксируйте выбранный паттерн и обоснование, почему именно он. А если вы выбираете гибрид — опишите, как именно данные текут между батч- и онлайн-частями, чтобы не запутаться самим и не запутать коллег.
От дизайна к коду
Когда дизайн-документ готов, начинается самое опасное — перенос идей в код. Главное правило: код для релиза отличается от исследовательского. В ноутбуке можно игнорировать ошибки, а в жизни каждое падение видят пользователи. Поэтому с первого дня закладывайте обработку ошибок, лимиты по времени и логирование. Думайте о надежности: что будет, если сервис упадет? Всегда держите заглушку (например, кеш с прошлыми предсказаниями), чтобы пользователь не увидел пустой экран.
Тестируйте не только код, но и данные — проверяйте, не изменилось ли их распределение, не пришли ли пустые значения. Главный секрет успешного запуска: сначала сделайте максимально простую работающую версию, а уже потом накручивайте сложные функции.
Главные ошибки при проектировании ML-систем
1. Машинное обучение там, где не нужно
Решили задачу нейросетью, хотя хватило бы простого SQL-запроса. Если задача решается эвристикой за час — не мучайте команду.
2. Погоня за метриками
Увлеклись повышением показателей, хотя бизнесу нужны деньги. Поэтому нужно постоянно сверяться с бизнес-задачами.
3. Грязные данные на входе
Обучили на чистых данных, а в релиз полетел мусор. Чтобы этого не было, делайте автоматические тесты на пропуски, выбросы и изменение распределений.
4. Нет мониторинга и обратной связи
Модель деградирует, мир меняется, а вы узнаете об этом через месяц от разгневанного начальника. Поэтому важно с первого дня проектировать, что и как отслеживать, и как собирать фидбек для дообучения.
5. Забыли про версионирование
Через полгода не можете повторить удачный эксперимент и откатиться, когда все сломалось. Всегда версионируйте код (git), данные и модели (MLflow)! Каждый эксперимент должен быть воспроизводим.
6. Не подумали о нагрузке
На тестовых 100 пользователях летало, на 10 000 реальных — легло. Закладывайте требования по производительности в дизайн и проводите нагрузочное тестирование до запуска.
Заключение
Проектирование и внедрение ML-систем ( Machine Learning System Design) — это умение вовремя задавать правильные вопросы. Зачем мы это делаем? Кому это нужно? Что будет, если модель ошибется? Как мы поймем, что она сломалась?
Главный секрет успешных 15% проектов в том, что они относятся к машинному обучению не как к научному эксперименту, а как к инженерной дисциплине. Проработанный дизайн-документ сэкономит месяцы разработки и миллионы рублей. Постройте этот фундамент правильно.
