Как развернуть модель машинного обучения (ML)
Еще десять лет назад развернуть веб-приложение означало скопировать файлы на сервер и перезапустить его. Сегодня мы делаем это через автоматизированную последовательность действий, контейнеры и оркестраторы — благодаря набору практик, которые объединяют команды разработчиков и системных администраторов (DevOps). С машинным обучением происходит то же самое. Команды осознали, что блестящая модель, которая лежит в папке на ноутбуке инженера, не приносит бизнесу ценности. В этой статье разберем, почему одного сохранения недостаточно и как развертывание, поддержка и тестирование модели машинного обучения (ML) в рабочей среде становятся важными этапами ее жизненного цикла.
Содержание
- Что нужно для развертывания моделей
- Жизненный цикл модели
- Подготовка модели к развертыванию: упаковка и зависимости
- Куда и как развернуть модель машинного обучения (ML)
- Инструменты подхода MLOps для автоматизации развертывания и мониторинга
- Пример
- С чего начать путь в MLOps: дорожная карта инженера
- Заключение
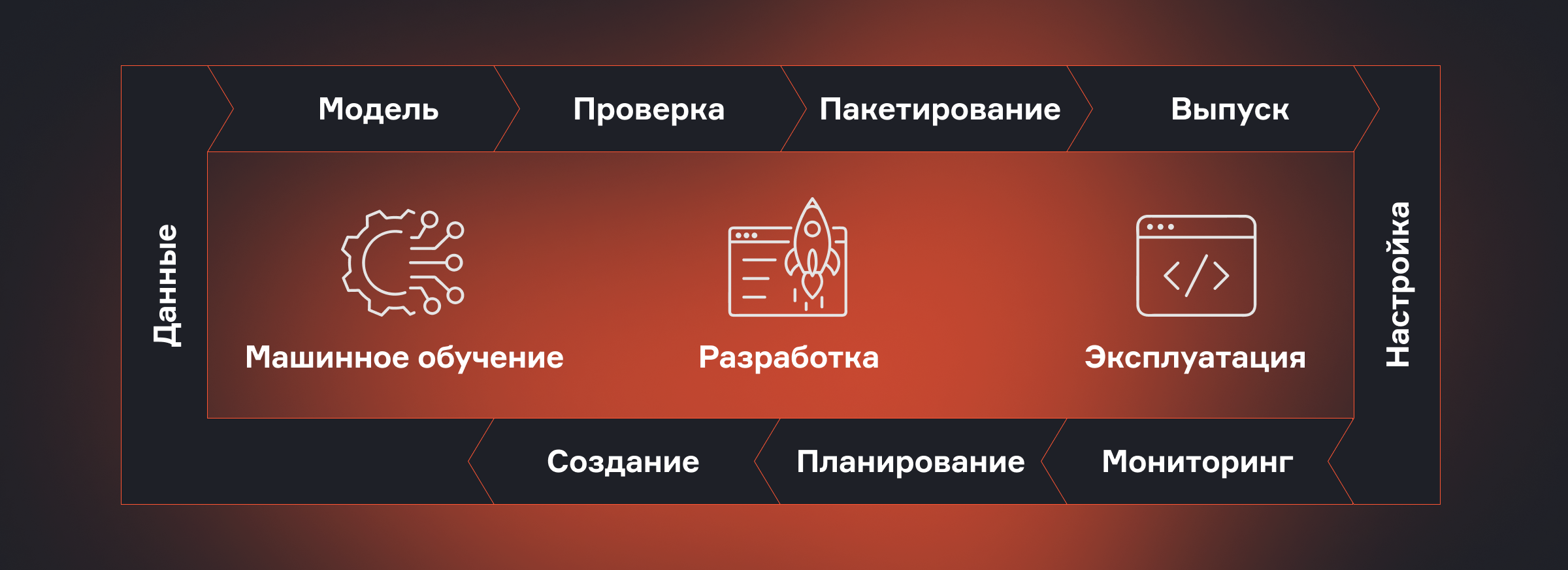
Что нужно для развертывания моделей
Инженерная надстройка над исследовательским процессом, превращающая разовый эксперимент в предсказуемый, измеримый и поддерживаемый сервис — это MLOps (МЛОпс, Machine Learning Operations). Т.е. набор практик, процессов и инструментов, которые объединяют машинное обучение, разработку и эксплуатацию.
В реальном бизнесе модель не существует в вакууме. Она становится частью большего приложения: кто-то подает ей данные, кто-то интерпретирует результат, кто-то следит, как она функционирует со временем.
Вывести готовое решение в работу, значит, решить ряд операционных задач:
- Воспроизводимость: сегодня работает, завтра после обновления библиотеки — падает с ошибкой сериализации.
- Масштабируемость: один запрос в минуту и тысяча запросов в секунду требуют разной архитектуры.
- Наблюдаемость: в отличие от обычного кода, модель может тихо деградировать из-за дрейфа данных, и это нужно отслеживать.
- Скорость итераций: переобучение не должно требовать ручного развертывания и приводить к часовому простою сервиса.
Без системного подхода развертывание превращается в героические усилия одного инженера. С МЛОпс — в повторяемый процесс, который можно автоматизировать.
Если вы хотите системно освоить эту область под руководством практикующих экспертов, обратите внимание на курс «Продвинутое машинное обучение». Программа рассчитана на специалистов с опытом в этой сфере, которым нужно повысить свой уровень и научиться решать сложные задачи бизнеса.
Ключевые отличия между сопровождением моделей машинного обучения и классической разработкой
На первый взгляд, задачи похожи: и там, и там нужно автоматизировать сборку, тестирование и доставку артефактов. Основные различия проявляются в нескольких аспектах.
| Характеристика | Поддержка и обновление приложений (DevOps) | Управление жизненным циклом моделей (MLOps) |
| Основной артефакт | Исходный код (бинарный файл, скрипт) | Модель + данные + код |
| Изменчивость | Код детерминирован | Модель недетерминирована: те же данные ≠ те же предсказания после переобучения |
| Контроль версий | Управление версиями кода (Git) | Управление версиями данных и моделей (Git + DVC) |
| Тестирование | Модульные тесты, интеграционные тесты, тесты производительности | Все то же + тестирование данных, тестирование качества модели (метрик), проверка дрейфа |
| Непрерывная интеграция и доставка-развертывание (CI/CD) | Непрерывная интеграция и доставка кода в окружение | Непрерывная интеграция + непрерывное обучение (CT) + непрерывная доставка моделей |
| Мониторинг | Доступность сервиса (Uptime), потребление ресурсов (CPU, RAM), количество ошибок (5xx) | Все то же + мониторинг качества предсказаний (Accuracy, MAE), мониторинг входных данных (Data Drift), время вывода (inference) |
| Откат | К предыдущей версии кода | К предыдущей версии модели или переобучение на старых данных |
Просто обучить модель недостаточно
Допустим, исследователь данных (Data Scientist) отдает разработчикам обученную модель. А через месяц узнает, что она так и не попала в прод. Причины зачастую одинаковы.
- Окружение. Модель обучалась в дистрибутиве для Python версии 3.9 с набором библиотек образца 2022 года. На рабочем сервере используется Python 3.12, и обновлённая библиотека для работы с таблицами нарушила этап предварительной обработки данных.
- Формат. Файл сохранен с расширением .pkl, но сервис для предсказаний написан на Java, и инженеры не знают, как его загрузить без костылей.
- Производительность. В ноутбуке модель обрабатывала 1000 объектов за секунду. На практике выяснилось, что постоянная перезагрузка весов ограничивает производительность одним запросом в секунду.
- Масштабирование. Алгоритм работает, но бизнес запустил рекламную кампанию, нагрузка выросла в 10 раз, и монолитное приложение просто ложится.
Модель машинного обучения (ML) — это не артефакт, а сервис. И как любой сервис, требует описанного программного интерфейса, контроля используемых библиотек, проверки устойчивости к нагрузке и продуманного порядка обновлений. Операции с моделями машинного обучения (MLOps) закрывают все эти вопросы.
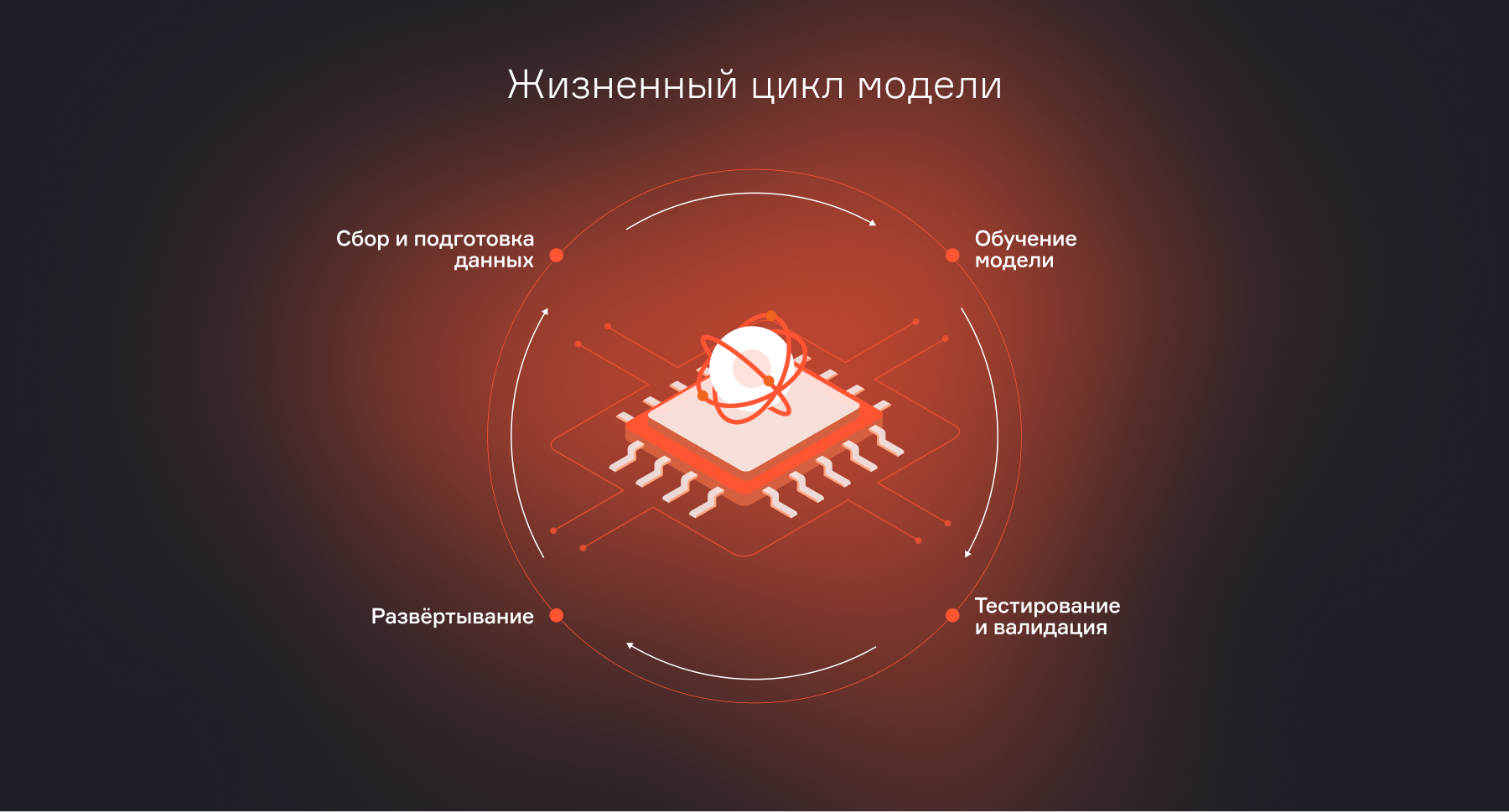
Жизненный цикл модели
Если классическое ПО движется по линейной траектории (код → тест → развертывание → поддержка), то модель машинного обучения эволюционирует в бесконечном цикле. Метрики ползут вниз, данные устаревают, бизнес просит нового — все это заставляет нас постоянно возвращаться к предыдущим этапам. Полный цикл выглядит примерно так:
1. Бизнес-задача
Определяем, какую проблему решаем и как измерим успех (коэффициент кликабельности CTR, конверсия).
2. Данные
Сбор, очистка, разведочный анализ. Это 70% времени.
3. Разработка
Формирование признаков, обучение и подбор гиперпараметров. В результате появляется кандидат модели.
4. Валидация
Проверка качества на свежих данных, тесты производительности, A/B эксперименты.
5. Развертывание
Подготовка модели к внешнему использованию и её интеграция в продукт.
6. Мониторинг
Следим не только за ошибками сервиса, но и за качеством предсказаний (дрейф данных data drift, падение метрик).
7. Переобучение
Если качество упало — обновляем алгоритм. Цикл замыкается.
Если совсем коротко, то можно обобщить до четырех этапов.
Подготовка модели к развертыванию: упаковка и зависимости
Между исследовательским кодом и реальным миром лежит пропасть, которую заполняют инженерные практики. Любую модель перед развертыванием нужно стандартизировать, т.е. привести к единому формату, упаковать в изолированную среду и научиться управлять ее версиями. Рассмотрим ключевые шаги.
Сохранение модели
Модули Pickle или Joblib
Самый распространенный способ для моделей, созданных с помощью библиотеки scikit-learn. При этом модуль Joblib обычно лучше: он быстрее работает с данными в формате NumPy и позволяет сжимать файлы для экономии места. Главный недостаток — нет строгих гарантий, что файл, сохраненный на одной версии библиотек, откроется на другой. Модель, сохраненная, например, в scikit-learn версии 0.24, может не загрузиться или работать с ошибками в версии 1.2..
Форматы библиотек машинного обучения
Библиотека TensorFlow сохраняет модели в формате SavedModel. Это каталог, содержащий вычислительный граф в бинарном виде, веса модели и дополнительные служебные данные.
Библиотека PyTorch использует файлы с расширениями .pt и .pth. В них может храниться либо словарь параметров модели (state_dict), либо вся модель целиком.
В рабочих системах, как правило, сохраняют именно словарь параметров, поскольку сохранение полной модели жёстко связывает файл с исходным кодом и снижает воспроизводимость решения.
Стандарт ONNX (Open Neural Network Exchange)
Универсальный формат для большинства типовых моделей, созданных в TensorFlow, PyTorch и scikit-learn. Модель преобразуется в единое представление и выполняется через движок ONNX Runtime без необходимости устанавливать исходный код программной платформы — на центральных и графических процессорах, а также на мобильных устройствах. Это делает ONNX удобным решением для промышленной эксплуатации с акцентом на переносимость. Поддержка зависит от набора операторов и версии программной платформы, поэтому совместимость рекомендуется проверять заранее (onnx.ai).
Контейнеризация модели: Docker как стандарт
Главный враг промышленной эксплуатации — «у меня на компьютере всё работает». Docker решает эту проблему.
Docker-образ — это копия состояния файловой системы с установленной ОС, Python, библиотеками и самой моделью. Он запускается одинаково на ноутбуке, в тестовом окружении и в облаке.
Для ML-модели машинного обучения Docker дает три важных преимущества:
- Изоляция. Модель со своими зависимостями не конфликтует с другими сервисами на сервере.
- Масштабирование. Образ можно размножить на десятки копий, если нагрузка растет.
- Версионирование. К каждому образу добавляют метку с номером версии, после чего откат на предыдущую модель выполняется одной командой.
В типовом коде сборки образа для ML-сервиса машинного обучения есть: базовый образ (например, python:3.9-slim), установка зависимостей из requirements.txt, копирование файла модели и кода API, команда запуска.
Управление зависимостями
Даже внутри Docker нужно фиксировать версии пакетов. Иначе обновление библиотеки pandas сломает сборку.
Виртуальные окружения (venv или утилита uv)
Стандартный механизм Python, который изолирует устанавливаемые пакеты друг от друга. Плюсы: занимают немного места, работают быстро (uv — это аналог стандартного инструмента venv, но значительно более быстрый). Минус: не затрагивают системные компоненты (например, библиотеки CUDA для видеокарт или библиотеки языка C) — для работы с ними лучше использовать Docker или Conda.
Система Conda (или её быстрая версия mamba)
Управляет не только пакетами Python, но и внешними библиотеками (такими как CUDA, MKL, C++). Незаменима для работы с моделями на видеокартах, где требуется особая настройка драйверов. Минус: со временем окружения сильно разрастаются в объеме, и между пакетами могут возникать конфликты.
Куда и как развернуть модель машинного обучения (ML)
Выбор стратегии развертывания — это баланс между бизнес-требованиями (латентность, доступность), техническими ограничениями (объем данных, требования к аппаратному обеспечению) и зрелостью команды (готовность управлять инфраструктурой).
В отличие от классического веб-сервиса, модель машинного обучения добавляет свои нюансы: чувствительность к распределению данных, потребление ресурсов при инференсе и необходимость переобучения.
- Развертывание как микросервис (REST API)
Самый популярный подход. Модель оборачивается в веб-сервер (FastAPI, Flask) и отвечает на HTTP-запросы.
Плюсы: простота интеграции с любой архитектурой, языковая агностичность, масштабирование горизонтально.
Минусы: издержки на протокол HTTP, неприемлем для сценариев со сверхнизкой задержкой (микросекунды).
Когда использовать: стандартный сценарий — оценка клиентов, рекомендации, классификация текстов.
- Пакетная обработка (Batch Inference)
Модель не ждет запросов в реальном времени, а запускается по расписанию (раз в час, раз в день), обрабатывая пачку данных и складывая результат в БД.
Плюсы: дешево, просто мониторить, легко пересчитывать при ошибках.
Минусы: не подходит для задач, требующих мгновенного ответа.
Когда использовать: оценка кредитных заявок (можно подождать минуту), сегментация пользователей для рассылок.
- Стриминговая обработка (Streaming)
Модель читает данные из потокового брокера сообщений (Kafka, Kinesis, RabbitMQ) и отправляет результат обратно в этот же поток.
Плюсы: реальное время, высокая пропускная способность.
Минусы: сложная инфраструктура, тяжело отлаживать.
Когда использовать: обнаружение мошенничества (fraud detection), обработка кликов в реальном времени.
- Встраивание в приложение (Embedded)
Модель работает прямо на устройстве пользователя или внутри мобильного приложения (TensorFlow Lite, CoreML, ONNX Runtime).
Плюсы: нулевая сетевая задержка, работа без интернета, данные не покидают устройство.
Минусы: ограниченные ресурсы устройства, сложно обновлять.
Когда использовать: мобильные приложения с камерой, рекомендации, автопилоты.
- Бессерверные вычисления (Serverless)
Можно использовать специализированные сервисы, например, AWS Lambda, Google Cloud Functions, Yandex Cloud Functions. Модель поднимается только когда приходит запрос.
Плюсы: платите только за использование, вообще нет инфраструктуры.
Минусы: холодный старт (первые запросы медленные), ограничение по времени выполнения (обычно до 15 минут) и памяти.
Когда использовать: редкие запросы, прототипирование, легкие модели.

Инструменты подхода MLOps для автоматизации развертывания и мониторинга
Инструментов много, стандартов мало, ажиотаж вокруг некоторых решений зашкаливает. Чтобы не заблудиться, разделим их на категории по функциям.
Оркестрация конвейеров данных
Инструменты, которые управляют последовательностью шагов: от выгрузки данных до обучения и выгрузки.
- Apache Airflow. Фактический стандарт для конвейеров, основанных на направленных ациклических графах (DAG). Зрелое решение с широкими возможностями интеграции, однако не специализировано для задач машинного обучения (отсутствует встроенное отслеживание экспериментов).
- Kubeflow. Мощное средство для работы в среде Kubernetes. Позволяет запускать Jupyter, обучать модели и развертывать их в единой среде. Требует сложной настройки, но обладает высокой функциональностью.
- Prefect / Dagster. Современная альтернатива Airflow с более удобным синтаксисом Python и улучшенным управлением состояниями.
Трекинг экспериментов и управление моделями
Здесь живет история экспериментов: какие гиперпараметры дали лучшую метрику, где лежит файл модели, какая версия сейчас в проде.
- MLflow. Популярный инструмент с открытым исходным кодом. Компоненты: Tracking (логирование параметров и метрик), Models (реестр моделей), Registry (управление жизненным циклом). Легко интегрируется с любым кодом.
- DVC (Data Version Control). Система управления версиями для данных, работающая по принципу Git. Позволяет отслеживать версии наборов данных и моделей, размещая их в хранилищах S3 или на локальных дисках, а в Git сохраняя только метаданные и ссылки.
- Weights & Biases (wandb). Облачный сервис, который многие аналитики любят за красивые панели и простоту интеграции.
Развертывание и обслуживание моделей
Инструменты, которые непосредственно отдают предсказания наружу.
- TensorFlow Serving. Специализированное средство обслуживания моделей TensorFlow. Поддерживает пакетную обработку запросов, управление версиями моделей и переключение трафика без перезапуска сервиса.
- TorchServe. Аналогичное решение от PyTorch.
- Seldon Core / KServe. Платформы для Kubernetes, преобразующие любую модель в масштабируемый микросервис с поддержкой постепенного внедрения обновлений и мониторингом.
- BentoML. Удобное средство, которое упаковывает модель со всеми зависимостями в готовый к использованию артефакт и позволяет развертывать его в Docker или Kubernetes одной командой.
Мониторинг моделей
Следим, чтобы данные не протухли.
- Prometheus + Grafana. Классическая связка для сбора метрик. Подходит и для ML, если экспортировать качество предсказаний как метрики.
- Evidently AI. Библиотека для расчета дрейфа данных и качества моделей. Генерирует красивые отчеты и умеет отдавать метрики в Prometheus.
- WhyLabs / Arize. Облачные платформы для мониторинга, которые автоматически следят за распределениями и бьют тревогу при аномалиях.
Важно
Инструменты MLOps-подхода не заменяют процессы. Начинайте с ручного, но воспроизводимого развертывания, а автоматизацию внедряйте лишь тогда, когда рутинные операции начнут занимать неоправданно много времени.
Пример
Развернем простую модель регрессии как REST-сервис. Модель предсказывает стоимость квартиры по площади, числу комнат и району.
Используемые технологии:
- Обучение моделей: scikit-learn
- Управление моделями: MLflow
- Программный интерфейс: FastAPI
- Упаковка решения: Docker
Шаг 1. Обучаем и сохраняем модель
train.py
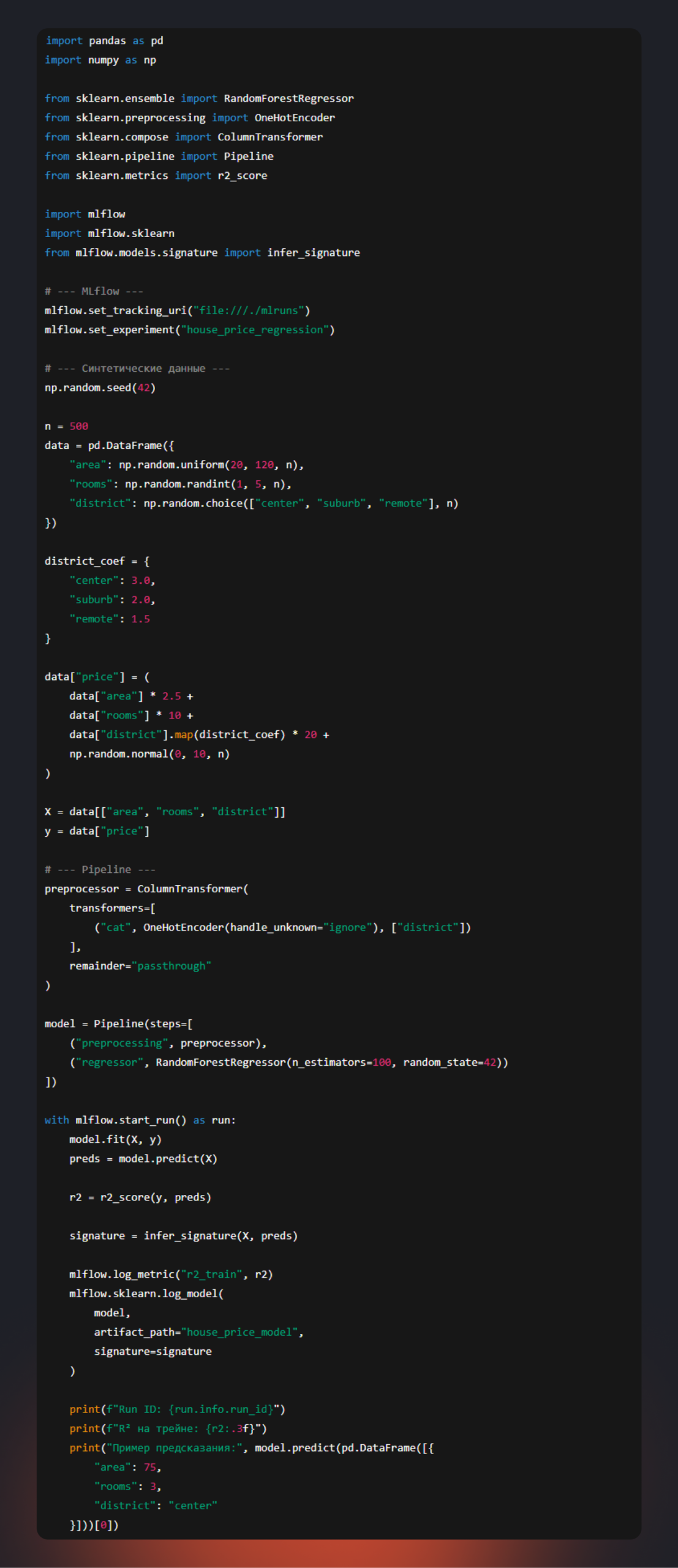
Запуск:

Запомните Run ID.
Модель сохранится в mlruns/.
Шаг 2. Экспортируем модель

В каталоге model/ — готовый артефакт для выполнения прогнозов.
Шаг 3. REST API на FastAPI
app.py
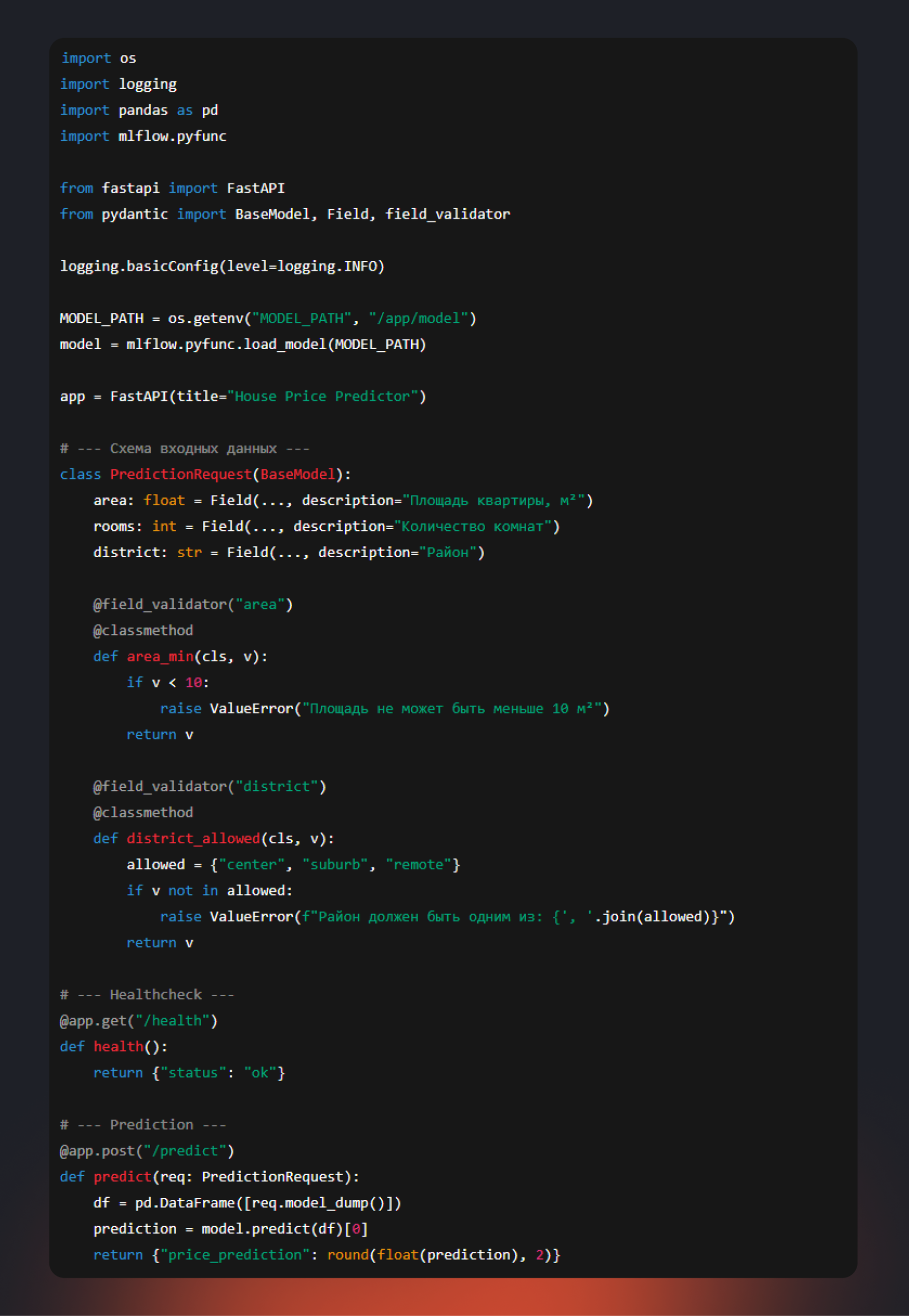
Шаг 4. Зависимости
requirements.txt

Шаг 5. Docker
Dockerfile
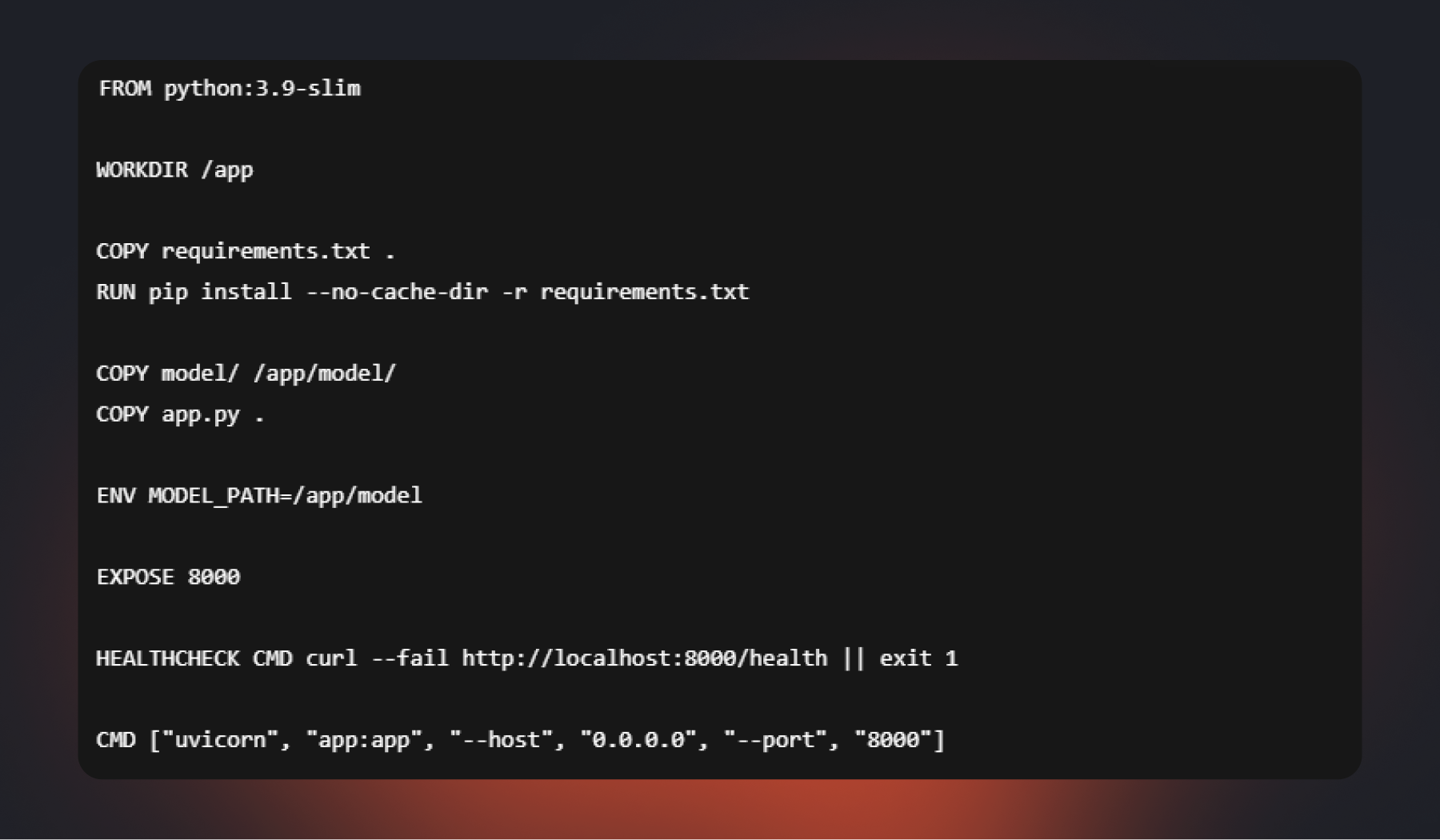
Сборка и запуск:

Шаг 6. Тестирование
Корректный запрос:

Ответ:

Ошибка валидации:
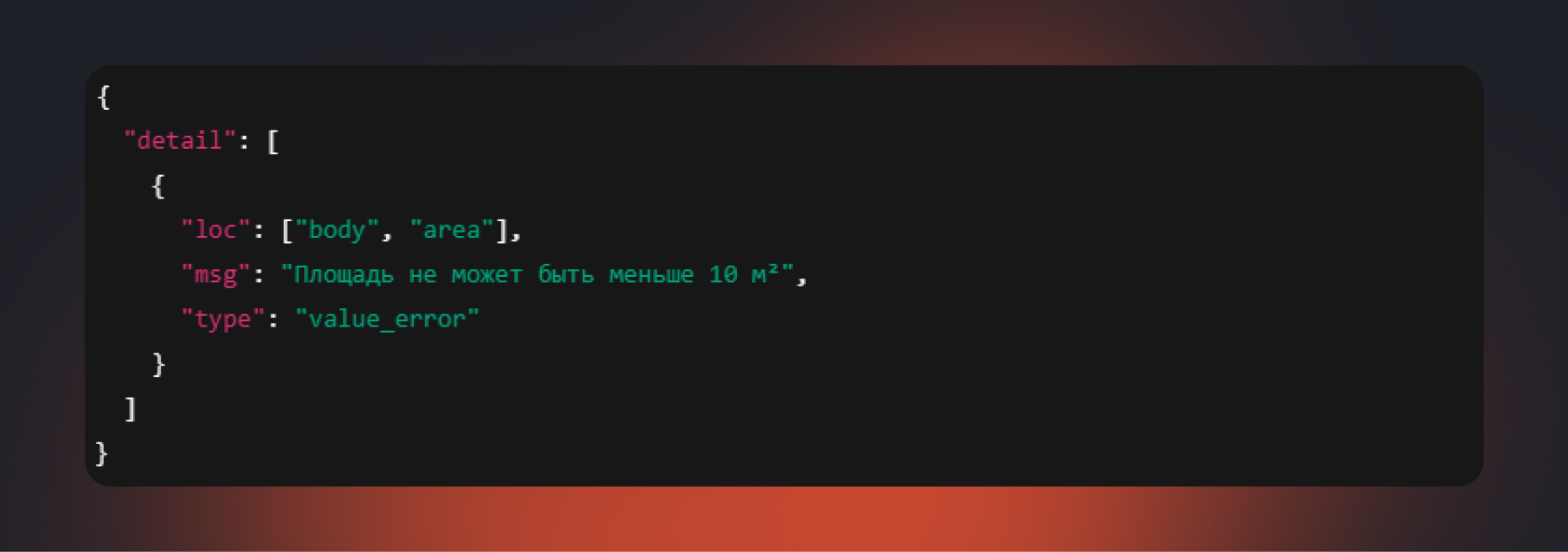
Это базовый рабочий пример. В промышленном решении потребуется дополнить его следующими компонентами:
— Переменные окружения для настройки (путь к модели, порт).
— Протоколирование запросов в формате JSON.
— Сбор метрик для Prometheus.
— Тестирование качества прогнозов.
— Поэтапное развертывание обновлений через Kubernetes.
С чего начать путь в MLOps: дорожная карта инженера
Путь в профессию пугает количеством инструментов, но если разложить по полочкам, все становится проще.
Базовые навыки
- Язык Python
Важно не только знание синтаксиса, но и умение создавать читаемый код с использованием аннотаций типов, обработки исключений и ведения журналов событий. Необходимо понимание объектно-ориентированного программирования, декораторов и менеджеров контекста.
Необходимо четко представлять, что именно подлежит развертыванию. Понимать процесс обучения модели, природу переобучения и принципы интерпретации метрик качества.
- ОС Linux
Модели функционируют на серверах, которые обычно работают под управлением Linux. Умение работать в терминале, писать bash-скрипты, понимать процессы и права доступа — обязательный навык.
- Система Git
Требуется не просто фиксировать изменения, но и понимать механизмы ветвления, разрешать конфликты слияния и эффективно работать в команде.
Обязательный набор технологий
- Платформа Docker
Нужно понимать, как собирать образы, оптимизировать их размер. Контейнеризация является фактическим стандартом доставки моделей.
Освоить Docker с нуля вы сможете на нашем бесплатном курсе.
- Непрерывная интеграция и доставка (CI/CD)
Jenkins, GitLab CI, GitHub Actions. Принцип един: автоматизация процессов сборки, тестирования и развертывания. Для начала достаточно научиться запускать автоматизированный конвейер при отправке изменений в репозиторий.
- Облачные платформы
AWS (SageMaker, S3), GCP (Vertex AI), Yandex DataSphere, Azure. Не обязательно владеть всеми платформами, но важно понимать принципы организации облачного хранения данных и развертывания виртуальной машины с моделью. Начинать изучение рекомендуется с одного поставщика услуг.
Как развиваться дальше
- Оркестрация
Kubernetes — ведущая платформа для оркестрации контейнеров. Понимание принципов работы сервисов, входных контроллеров и диаграмм развертывания Helm позволяет вывести масштабирование на качественно новый уровень. Для задач машинного обучения особенно эффективны платформы Kubeflow и KServe.
- Специализированные MLOps-платформы
MLflow (отслеживание экспериментов и реестр моделей), DVC (управление версиями данных), Apache Airflow (автоматизация конвейеров), Evidently (мониторинг качества). Глубокое изучение одного-двух инструментов даст понимание архитектуры корпоративных решений.
Подход MLOps тесно пересекается с этой областью. Знание Apache Spark, Apache Kafka, ClickHouse или хотя бы базовое понимание потоковой обработки данных значительно расширяет профессиональный кругозор и позволяет создавать по-настоящему адаптивные системы реального времени.
- Гибкие навыки
Важно уметь аргументированно объяснить специалисту по данным, почему недопустимо передавать сериализованную модель по электронной почте, а разработчикам — зачем для моделей требуются специализированные механизмы мониторинга.
Заключение
Мы разобрали, чем управление жизненным циклом моделей (MLOps)
отличается от поддержки и обновления приложений (DevOps), и прошли полный цикл — от создания и разработки ML-модели машинного обучения до её упаковки в Docker и развертывания программного интерфейса. Это минимальный рабочий фундамент. Дальше — дело вашей практики.
