От данных к решениям: что такое DWH и как с ним работает аналитика
Представьте, маркетолог просит отчет по вчерашней акции. Отдел продаж жалуется на расхождение данных с финансами. А вы, аналитик, вместо поиска инсайтов целый день гоняетесь за цифрами: выгружаете логи из одной системы, чистите CSV из другой, пытаетесь свести это в Excel и молитесь, чтобы итоговые цифры сошлись. Большая часть рабочего дня уходит не на анализ, а на борьбу с хаосом в данных.
Содержание
Избежать этого поможет Data Warehouse (DWH), или хранилище данных. Из этой статьи вы узнаете, как ежедневная работа с хранилищем превращает хаотичный сбор метрик в эффективный процесс, где большую часть времени занимает не подготовка информации, а ее анализ, поиск инсайтов и формирование рекомендаций для бизнеса.

DWH простыми словами: единый мозг для данных компании
Допустим, аналитику музыкального стриминга поставили задачу узнать, сколько пользователей оформили подписку в январе и сколько из них осталось в сервисе через 3 месяца.
Для этого понадобятся данные из разных систем.
- Из базы приложения: список пользователей, которые нажали кнопку «Оформить подписку» в январе.
- Из платежной системы: информация об успешных списаниях денег за январь, март и апрель (чтобы подтвердить, что подписка активна).
- Из CRM: сведения о тарифах или акциях, по которым люди подключились.
Без DWH день аналитика превратится в квест по цифровой археологии.
- Написать сложный запрос к базе данных приложения, чтобы выгрузить 50 000 строк с ID пользователей, которые начали оформление в январе.
- Сходить к коллеге из отдела платежей, попросить доступ к их системе. Там структура таблиц совершенно другая, названия полей не совпадают. Написать второй запрос, чтобы найти успешные транзакции.
- Чистить данные в огромных файлах Excel.
В итоге 80% времени тратится на поиск нужной информации, а бизнес-задачу еще даже не начали решать.
DWH меняет ситуацию.
Data Warehouse (DWH) — это централизованное хранилище, куда регулярно собирают, очищают и приводят к единой логике данные изо всех систем компании. Здесь они хранятся в аналитическом виде и с историей изменений, чтобы на их основе можно было быстро отвечать на бизнес-вопросы.
С хранилищем работа аналитика ускоряется в разы. Вернемся к стримингу.
1. Подключиться к DWH. Например, через инструмент вроде SQL или BI-систему.
2. Написать один прямой и простой запрос.
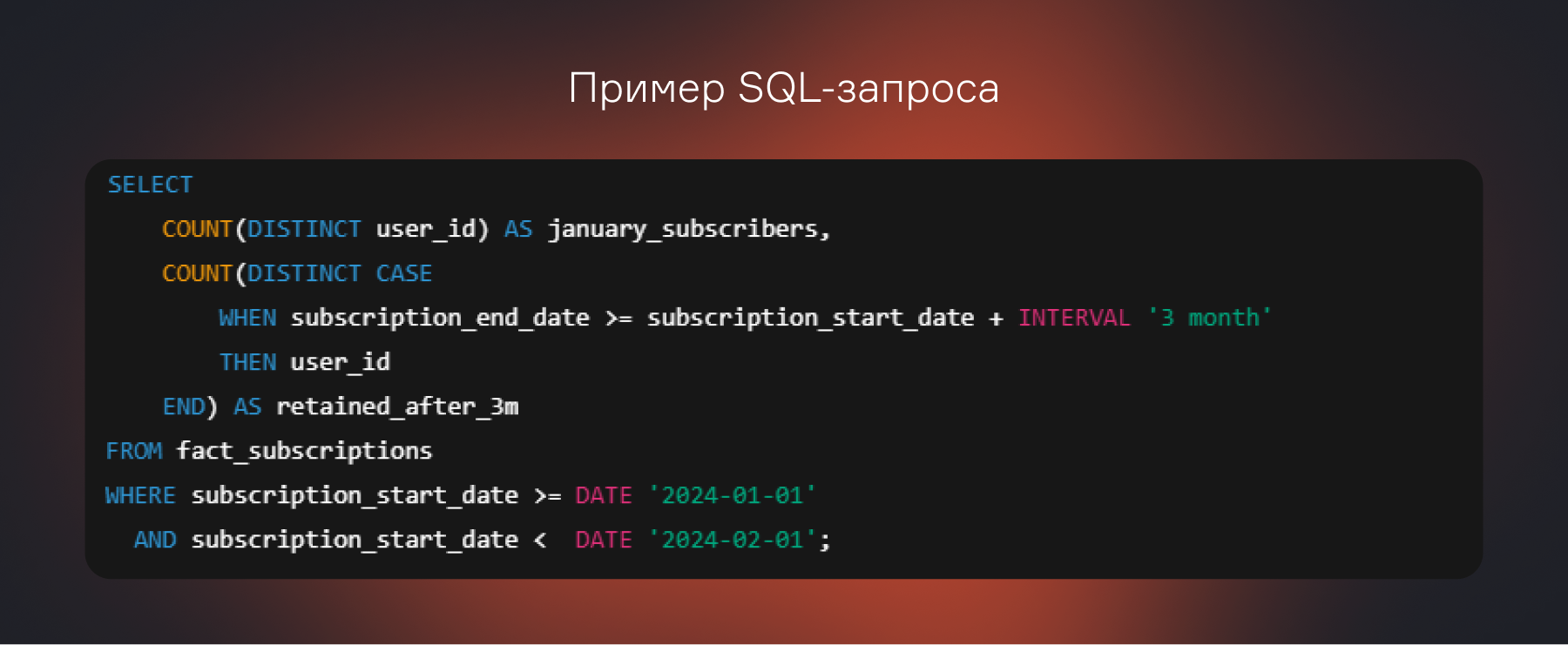
3. Получить ответ за секунды вместо дней или часов.
Специалист экономит время, которое может потратить на анализ. «Почему именно эта группа пользователей осталась? Может, они чаще слушали плейлисты? А те, кто ушли, — у них были технические ошибки при платеже?». И сразу переходит к генерации гипотез и поиску инсайтов.
Кратко
Кто и как использует Data Warehouse:
- аналитики — строят отчеты и дашборды;
- продуктовые команды — смотрят метрики и гипотезы;
- бизнес — принимает решения на основе цифр.
Чаще всего с хранилищем работают через:
- SQL-запросы,
- BI-инструменты (дашборды и отчеты).
Если аналитик — это главный пользователь и исследователь DWH, то дата-инженер — его архитектор и строитель. Это специалист, который проектирует и создает само хранилище, обеспечивая бесперебойный поток качественной информации из всех уголков компании в единый аналитический центр. Хотите освоить эту сложную, но интересную и очень востребованную профессию? Приходите на курс «Инженер данных». Программа создана для профессионалов, которые стремятся к системному проектированию сложных решений.
Чем DWH не является: ключевые отличия от базы данных
Под «обычной» базой данных (чаще всего это OLTP-система) мы подразумеваем рабочую, операционную базу. Ее задача — обеспечивать ежедневную работу приложения или сервиса. Оформить заказ, списать деньги, обновить статус. Она быстро записывает данные, но плохо подходит для анализа. История может перезаписываться, структура — меняться, а сложные аналитические запросы замедляют систему.
Data Warehouse устроено иначе. Оно не обслуживает пользователей напрямую и не участвует в транзакциях. Задача — хранить очищенные, согласованные и исторические данные так, чтобы аналитик мог спокойно задавать сложные вопросы: сравнивать периоды, сегменты, каналы и метрики без риска сломать прод.
| Обычная БД (OLTP — обработка транзакций) | Хранилище данных (DWH — аналитическая обработка) | |
| Основная цель | Операционная работа. Поддержка ежедневных бизнес-процессов в реальном времени. | Аналитика и поддержка решений. Анализ исторических данных для выявления тенденций, прогнозирования. |
| Основные операции | CRUD: Частые короткие операции записи и обновления (INSERT, UPDATE, DELETE). Чтение — по конкретной записи (например, найти заказ №123). | Чтение и агрегация. Очень редкая запись (обычно пакетная загрузка). Частые сложные запросы на чтение (SELECT) с обходом миллионов строк. |
| Структура данных | Нормализованная. Много связанных таблиц. | Денормализованная (часто). Широкие таблицы готовые для анализа. Например, все данные о продаже в одной строке: товар, клиент, магазин, скидка. |
| Масштаб запросов | Обрабатывает много простых транзакций (тысячи в секунду). Пример: «Сменить статус 1 заказа на ’доставлен’». | Обрабатывает мало, но очень тяжелых запросов (несколько в минуту/час). Пример: «Выручка по всем регионам за последние 5 лет в разбивке по категориям товаров». |
| Источники данных | Обычно один источник — то приложение, которое она обслуживает. | Много источников: данные из нескольких OLTP-баз, лог-файлы, внешние API. Например, данные о погоде для анализа спроса. |
| Временной горизонт | В основном текущие, актуальные данные. Старые данные часто архивируются или удаляются. | Хранит исторические данные годами, чтобы видеть тренды. |
| Производительность | Оптимизирована для скорости записи и поиска по ключу. | Оптимизирована для скорости чтения больших объемов и сложных соединений (JOIN). |
Кратко
- Операционная база отвечает, что происходит прямо сейчас;
- Data Warehouse — что на самом деле происходит с бизнесом и почему.
Зачем бизнесу внедрение DWH
Когда в компании нет единого хранилища, аналитика часто выглядит так: разные команды приносят разные цифры, отчеты не сходятся, а на обсуждение, чьи числа правильнее, уходит больше времени, чем на поиск решений. В результате бизнес либо принимает решения на неполных данных, либо откладывает их вовсе.
DWH превращает разрозненные источники в единую систему координат, где метрики определены один раз и используются всеми. Для компании это означает не просто отчеты, а возможность быстро получать ответы и опираться на них в управлении.
Какие задачи решает
Консолидация данных
Все ключевые данные компании — продажи, пользователи, финансы, маркетинг — собираются в одном месте. Аналитику не нужно сводить данные вручную и объяснять, почему цифры отличаются: источники уже связаны и синхронизированы.
Например, в хранилище можно сопоставить данные о качестве работы колл-центра (среднее время решения проблемы) с информацией о повторных покупках клиента. И доказать гипотезу: «Клиенты, чьи вопросы решались быстрее 10 минут, в 2 раза чаще совершают повторную покупку».
Качество и единая логика
В DWH закрепляются общие определения метрик: что считается выручкой, активным пользователем или конверсией. Это снижает количество ошибок и споров между командами и делает аналитику воспроизводимой.
Специалисты больше не тратят время на согласование методологии. Берем готовую, документально зафиксированную метрику. Например, колонку is_active_user в таблице user_activity_daily, и уверенно используем в расчетах. Отчеты аналитика всегда консистентны с отчетами коллег, а их результаты можно воспроизвести в любой момент.
Скорость принятия решений
Когда данные готовы к анализу, бизнес получает ответы быстрее. Аналитик тратит меньше времени на подготовку и больше — на интерпретацию, поиск закономерностей и проверку гипотез.
Примеры из индустрий
Ретейл
Аналитик объединяет данные по продажам, остаткам и акциям в DWH и быстро видит, какие товары теряют маржинальность и почему. Решения по ассортименту и ценам принимаются на основе общей картины, а не отдельных отчетов.
Условная задача: оптимизировать складские запасы и повысить оборачиваемость товаров.
- Хранилище ежедневно забирает данные из 1C, системы учета склада и отдельных табличек у закупщиков.
- Внутри создается единая аналитическая витрина inventory_management.
- В ней для каждой товарной позиции (SKU) в каждом магазине автоматически рассчитываются ключевые метрики: текущий остаток, средние продажи в день, прогноз исчерпания (дней осталось).
Аналитик или даже сам менеджер через BI-дашборд видит красные зоны — товары, которых осталось меньше, чем на 3 дня продаж. Закупки начинают опираться на факты, сокращаются потери от нехватки или излишков, повышается оборачиваемость.

Финтех
Data Warehouse позволяет связать транзакции, поведение пользователей и продуктовые события. Специалист может проанализировать реальную ценность клиентов, найти узкие места в воронке и дать бизнесу основание для изменений в продукте или скоринге.
Задача: борьба с мошенничеством и оценка кредитного риска.
- DWH в режиме, близком к реальному времени (например, каждые 15 минут), загружает сведения о транзакциях, действиях пользователя в приложении и данные из CRM.
- Создается витрина user_risk_profile, которая агрегирует поведение клиента: частота и сумма транзакций, геолокация устройств, история обращений.
- На основе этих чистых и соединенных данных Data Scientist обучает ML-модель, которая присваивает каждой новой транзакции скоринг риска.
Когда пользователь пытается совершить подозрительный перевод, система в миллисекунды проверяет не только саму транзакцию, но и его целостный профиль из хранилища. Если риск высок — операция блокируется для дополнительной проверки. Это защищает деньги клиентов и репутацию банка.
Маркетинг
Вместо разрозненных отчетов по каналам аналитик работает с единой витриной: расходы, конверсии и LTV уже связаны. Это позволяет не просто считать клики, а понимать, какие кампании действительно приносят результат.
Задача: оценить окупаемость инвестиций в рекламу (ROMI) и оптимизировать маркетинговый бюджет.
- DWH забирает сведения о кликах и показах из рекламных систем, а данные о конверсиях (заявки, покупки) — из CRM и сайта.
- Внутри применяется сложная, но единая для всей компании логика атрибуции. Например, атрибуция по последнему клику перед конверсией.
- Строится витрина marketing_campaign_performance, где для каждой кампании указаны расходы и итоговые продажи, которые к ней приписались.
Маркетолог видит не просто клики и показы, а весь путь клиента. Он может точно сказать: «Реклама в VK приносит нам покупателей с самой низкой стоимостью привлечения (CAC), а контекстная реклама по брендовым запросам — с самой высокой долгосрочной ценностью (LTV)». Бюджет перераспределяется в эффективные каналы, ROMI растет.
Как устроен DWH: архитектура и слои данных
Аналитик открывает хранилище и работает с уже подготовленной информацией, не задумываясь о том, как именно она туда попала. Чтобы это было возможно, Data Warehouse строится как отдельная система со своими правилами.Здесь четко разделены этапы работы: источники → загрузка → очистка → аналитические таблицы. Это упорядоченный конвейер. Его суть не в хранении, а в последовательном преобразовании данных от состояния сырых и разрозненных до готовых для анализа. Процесс закреплен в слоистой архитектуре, где каждый слой решает свою задачу.

Слоистая архитектура: от сырых данных до витрин
Шаг 1. Забрали данные из источников (Ingestion)
Это точка входа. Специальные процессы (пайплайны ETL/ELT) автоматически извлекают данные из операционных систем бизнеса: баз данных приложений, CRM, платежных шлюзов, лог-файлов, внешних API. Работают по расписанию (batch) или в реальном времени (streaming).
Шаг 2. Сохранили как есть (Raw / Staging Layer — Сырой слой)
Первый физический слой внутри DWH. Все полученные данные сохраняются здесь без изменений. Это как цифровая фотография состояния источника на момент выгрузки.
Данные в этом слое:
- могут иметь любые форматы;
- часто содержат ошибки и дубликаты.
Этот слой редко используют аналитики: он нужен для восстановления истории, отладки и контроля загрузок. Здесь чаще работает дата-инженер.
Шаг 3. Привели в порядок (Core / Integration Layer — Ядро, слой интеграции)
Второй и главный технологический слой. Здесь происходят ключевые преобразования. Сведения из сырого слоя:
- Очищаются: исправляются опечатки, удаляются дубли, помечаются пропуски.
- Стандартизируются: все даты приводятся к единому формату, коды и названия унифицируются (например, «РФ», «Россия», «RU» → «RU»).
- Интегрируются: данные из разных источников соединяются по правилам. Создаются фундаментальные, надежные сущности — записи о клиентах, продуктах, транзакциях.
В результате появляются общие справочники, корректные связи и история изменений. Это фундамент хранилища, на который опирается вся аналитика.
Шаг 4. Подготовили для анализа (Data Marts Layer — Слой витрин данных)
Здесь данные из ядра трансформируются под конкретные бизнес-задачи. Создаются тематические витрины — оптимизированные для чтения структуры.
- Маркетинговая витрина: данные о рекламных кампаниях, лидах и конверсиях в одной таблице.
- Финансовая витрина: готовые агрегаты по выручке, затратам и прибыли.
- Продажная витрина: детализированные данные о чеках, товарах и клиентах.
Витрины денормализованы, т.е. данные организованы так, чтобы для получения ответа требовалось минимальное количество соединений таблиц. Нужные факты собраны в одном месте. Это делает анализ быстрым и удобным.
Такое разделение позволяет аналитикам не думать о качестве загрузок, а инженерам — не бояться, что их изменения сломают отчеты.
ETL/ELT
Это не просто аббревиатуры, а два разных порядка действий, которые определяют, где и когда происходят основные преобразования данных на их пути в хранилище. Это фундаментальное архитектурное решение.
Вне зависимости от подхода, любой пайплайн включает три шага:
- Extract (Извлечение) — получение информации из исходных систем (базы, API, файлы).
- Transform (Преобразование) — очистка, стандартизация, объединение данных, т. е. приведение их в порядок.
- Load (Загрузка) — помещение итоговых сведений в целевую таблицу DWH.
Важно
Разница между ETL и ELT — в последовательности шагов T и L.
ETL (Extract → Transform → Load) — классический подход.
Данные сначала забирают из источников, затем очищают и объединяют вне Data Warehouse, и только готовый результат загружают в хранилище.
- Плюсы: хороший контроль и безопасность.
- Минусы: сложно масштабируется, менее гибок, часто не сохраняются сырые данные.
ELT (Extract → Load → Transform) — современный стандарт для облачных хранилищ.
Данные сначала загружают в DWH как есть, а все преобразования делают уже внутри с помощью SQL.
- Плюсы: высокая масштабируемость, гибкость, проще архитектура.
- Минусы: логично только при использовании современных облачных решений, требует тонкой настройки прав.
В командах, где стираются границы между аналитикой и инжинирингом, аналитик может сам писать SQL-скрипты преобразований для создания своих витрин, так как вся необходимая информация ему доступна. Зная, что есть сырой слой, специалист в случае странностей в данных, можете запросить у инженера или проверить самостоятельно, что же изначально пришло из источника, чтобы найти корень проблемы.
Язык DWH: модели данных для аналитики
Внутри системы информация организована по определенным логическим шаблонам — моделям. Они не случайны, а решают конкретные задачи: максимально ускорить выполнение аналитических запросов и сделать данные интуитивно понятными для бизнес-пользователя. Есть две основные модели: «звезда» и «снежинка». В их основе лежат понятия фактов и измерений.
Факты (Fact Tables)
Центральные таблицы, содержащие события или операции, которые нужно анализировать. Это количественные, измеримые данные. Например, заказ, просмотр, платеж или подписка.
Факты содержат числа, которые можно суммировать, усреднять. Каждая строка — это конкретное событие, например, одна позиция в чеке, один клик по рекламе. Помимо них, таблица состоит в основном из ключей (ID), которые связывают ее с таблицами измерений.
Измерения (Dimension Tables)
Справочные таблицы, которые описывают и раскрывают контекст фактов. Это качественные, описательные данные. Например, пользователь, дата, продукт, город или устройство.
Они содержат текстовые или числовые поля для фильтрации, группировки и маркировки. Одна строка описывает один объект: одного клиента, один товар, один день.
Важно
Одна таблица фактов связана с несколькими таблицами измерений. Это позволяет анализировать меры (сколько продали) в разрезах атрибутов (что продали, когда, кому и где).
«Звезда» и «Снежинка»: схемы для быстрых запросов
Схема «звезда»
Самая распространенная и оптимальная для аналитика модель в слое витрин.
В центре находится одна таблица фактов. Вокруг нее расположены таблицы измерений, каждая из которых связана с фактами напрямую по первичному ключу.

Возьмем пример для интернет-магазина.
Есть таблица фактов sales_fact: sale_id, product_id (ключ), customer_id (ключ), date_id (ключ), store_id (ключ), quantity (мера), revenue (мера).
И таблицы измерений:
- dim_product (product_id, product_name, category, brand),
- dim_customer (customer_id, city, segment),
- dim_date (date_id, day, month, year, quarter, is_weekend),
- dim_store (store_id, store_name, region).
Аналитик пишет запрос, который начинает выборку из sales_fact, присоединяет к нему dim_product для фильтрации по категории и dim_date для группировки по месяцам. Это быстро и просто.
Почему любят «звезду»:
- Структура визуально очевидна. Легко понять, какие разрезы доступны для анализа.
- Для большинства запросов оптимизатору DWH нужно сделать минимальное количество JOIN’ов (обычно один к каждой таблице измерений).
- Такие системы (Tableau, Power BI) эффективно работают именно со звездной схемой.
Схема «снежинка»
Это более нормализованный вариант, где справочники разбиваются на несколько связанных таблиц. Она экономит место и упрощает поддержку справочников, но делает запросы чуть сложнее. Обычно такую схему выбирают, когда важна масштабируемость и строгая структура.
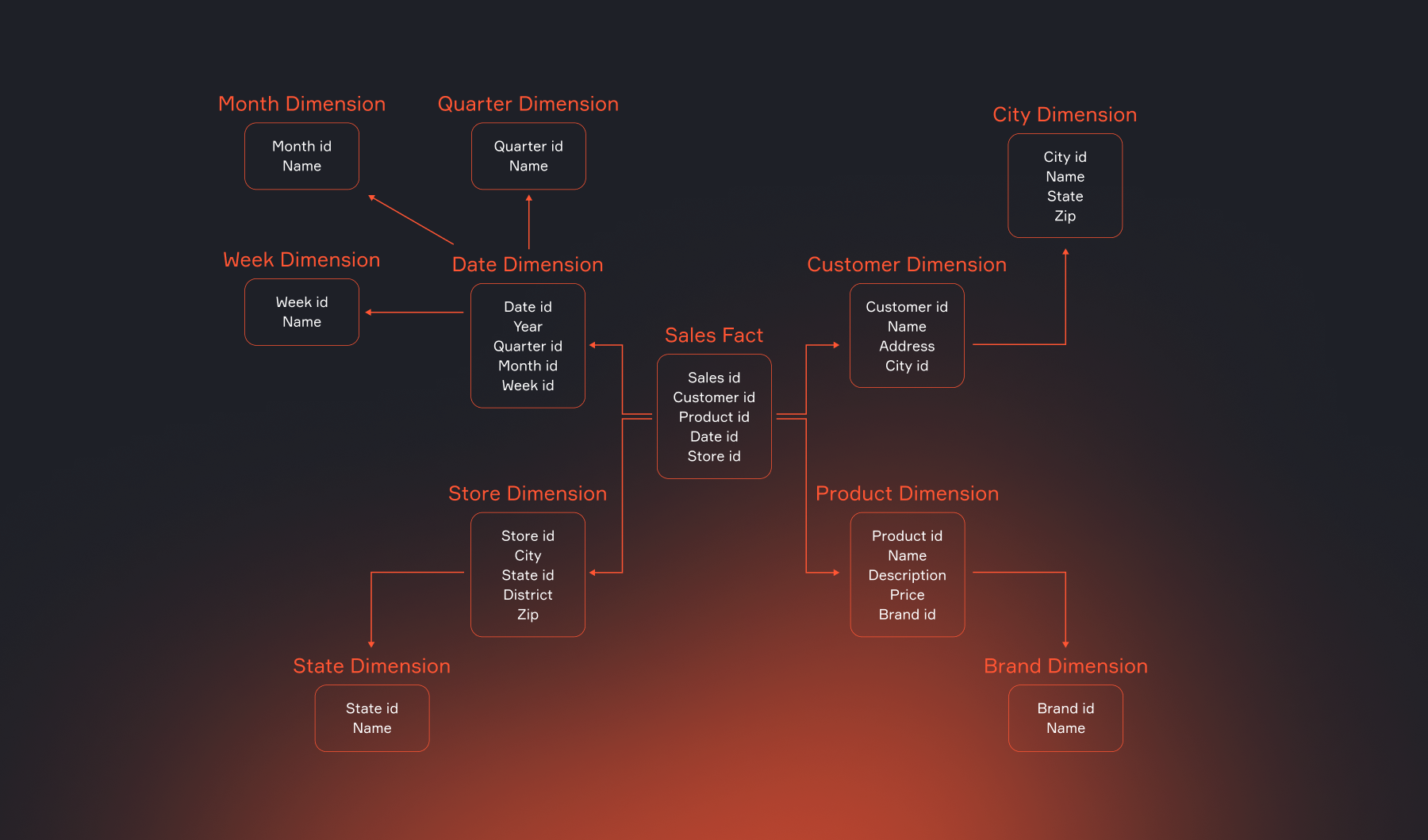
Таблицы измерений также имеют свои подчиненные измерения. Это означает, что атрибуты измерения вынесены в отдельные справочные таблицы. Схема визуально похожа на снежинку, где от центра расходятся не только лучи, но и их ответвления.
Возьмем тот же пример с интернет-магазином, но используем схему снежинки.
- Таблица фактов sales_fact остается той же.
- Таблица dim_product теперь содержит только product_id, product_name и **category_id** (ключ).
- Появляется новая таблица dim_category (category_id, category_name, **department_id**).
- Появляется таблица dim_department (department_id, department_name).
С одной стороны название департамента не дублируется для каждого товара, что экономит место. А с другой стороны, чтобы получить полное название товара с отделом, нужно сделать 3 JOIN’а вместо одного. Это замедляет анализ.
Принципы построения: предметная ориентация и историчность
Предметная ориентация
Данные в DWH организованы не вокруг функций или приложений, как в операционных системах (OLTP), а вокруг ключевых бизнес-сущностей и процессов, которые интересны для анализа. Структура хранилища отражает предметные области бизнеса, а не структуру IT-систем.
То есть, если нужны данные по продажам, специалист идет не в таблицу заказов из API магазина и не в таблицу платежей из шлюза, а в готовую витрину sales, где все уже собрано и связано.
Историчность данных
Система хранит не только текущее состояние, но и изменения во времени. Данные не перезаписываются, а накапливаются. Это позволяет анализировать динамику, сравнивать периоды и отвечать, что изменилось и когда.
Например, при анализе оттока можно восстановить полную историю взаимодействий ушедшего клиента и понять, что именно привело к этому решению. Возможно, после трех повышений стоимости подписки активность пользователя начала падать.
От теории к практике: как строится и работает DWH
Давайте проследим весь путь от задачи бизнеса до готового инсайта. В этом и заключается рутинная работа аналитика с хранилищем данных.
Итак, бизнес спрашивает: «Как меняются наши продажи по месяцам?»
Шаг 1. Переводим вопрос на язык метрик и разрезов
- Что такое «продажи»? Количество заказов? Выручка (сумма)? Прибыль (выручка минус затраты)?
- За какой период? Календарный месяц? 30 дней на текущую дату?
- С какой детализацией? По месяцам? По неделям? По категориям товаров?
Специалист должен уточнить и формализовать. Хорошо, что в Data Warehouse уже прописано, что выручка — это сумма по оплаченным и доставленным заказам. Не придется выяснять и согласовывать заново.
Шаг 2. Выбираем факты и измерения
Где лежат нужные данные?
- Таблица фактов: orders_fact (факты заказов).
- Ключевое измерение: dim_date (измерение времени).
- Нужная мера: final_revenue (финальная выручка).
Аналитик не думает, из какой системы пришел заказ или как связать клиента с платежом — эти связи уже реализованы.
Шаг 3. Пишем SQL-запрос
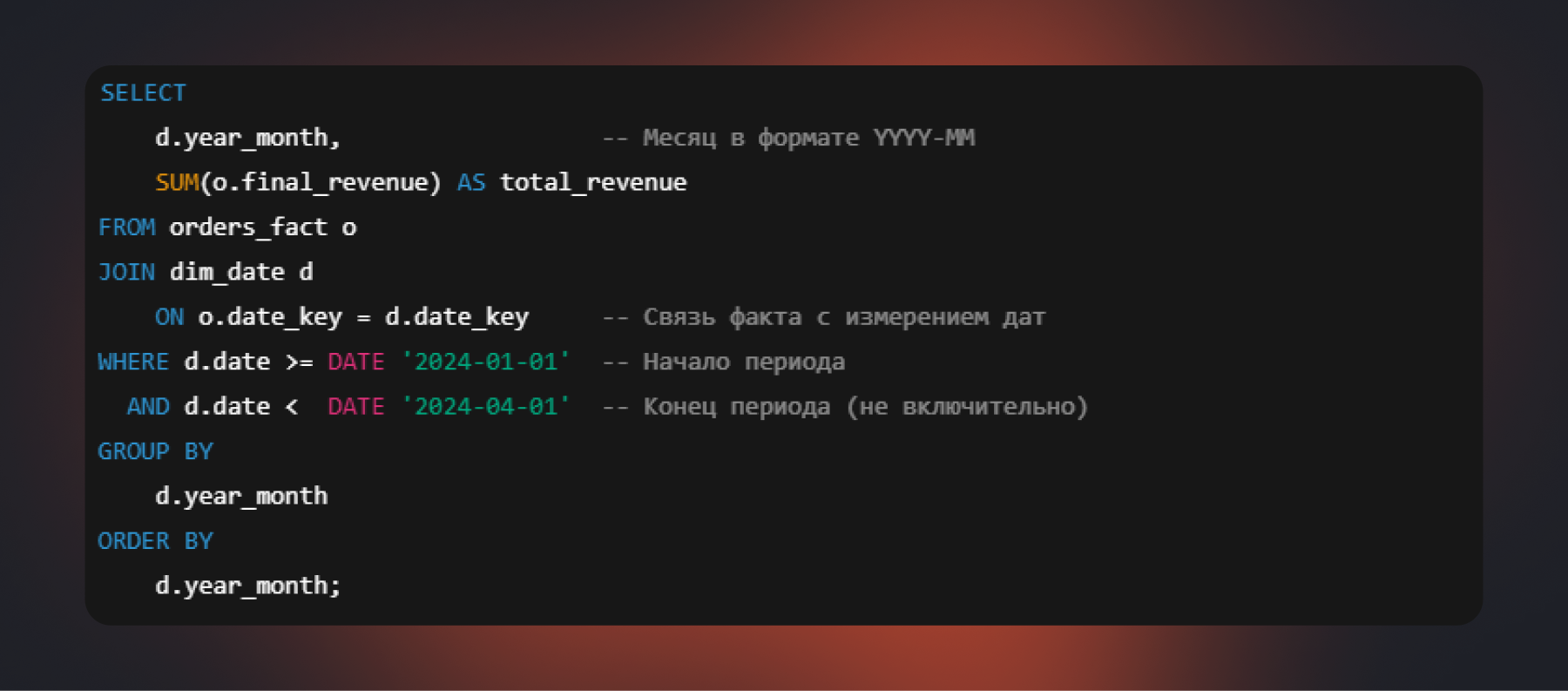
Система выполнит запрос за секунды, даже по данным за годы, благодаря оптимизации для чтения и агрегации.
Шаг 4. Проверяем данные (Data Sanity Check)
Прежде чем показывать менеджменту результаты, нужно все перепроверить.
- Сверить итоговую сумму с показателем за прошлый период из старого отчета.
- Поискать аномальные скачки или провалы.
- Убедиться, что фильтры (например, по статусу заказа) применены корректно.
Благодаря тому, что DWH накапливает данные, можно легко найти информацию за нужный год, месяц, квартал.
Шаг 5. Строим дашборд и интерпретируем результат
Чистые данные из хранилища загружаем в BI-инструмент (Power BI, Tableau). Строим график или дашборд.
- Тренд выручки по месяцам становится наглядным.
- Добавляются фильтры: по региону, каналу продаж, категории товара.
Шаг 6. Изучаем другие гипотезы
Практически никогда анализ на первом вопросе не заканчивается. Появляются уточнения:
- «Хорошо, общая выручка растет. А если разбить по новым и старым клиентам?»
- «В каком регионе самый высокий рост?»
- «Рост за счет количества заказов или за счет среднего чека?»
Можно масштабировать анализ мгновенно. Чтобы ответить на новый вопрос, аналитику не нужно начинать с нуля — просто добавим новое измерение (dim_customer.segment) или новую метрику (order_count) в свой запрос. Данные для этого уже есть, очищены и готовы.
Навыки и инструменты
Работа с хранилищем — это всегда баланс между техническим мастерством и бизнес-интуицией. Без первого вы не достанете данные. Без второго не поймете, что с ними делать и зачем.
Технические навыки
- SQL
95% работы с DWH — это написание SQL-запросов для извлечения и трансформации данных из витрин.
Что важно уметь:
- SELECT, JOIN, WHERE, GROUP BY, ORDER BY — базовый синтаксис.
- Оконные функции (ROW_NUMBER(), RANK(), LAG()) — для сложного анализа трендов и ранжирования.
- CTE (Common Table Expressions) и подзапросы — для структурирования сложных запросов.
- Оптимизация запросов — понимать, почему запрос выполняется медленно (отсутствие индексов, сложные JOIN’ы, большие сканы таблиц).
Бесплатный курс «Симулятор SQL» поможет разобраться с основами языка запросов и даст много практического материала для закрепления теории.
- BI-инструменты (визуализация).
Например, Tableau, Power BI, Яндекс DataLens. Помогают превращать результаты запросов в интерактивные графики и дашборды, понятные бизнесу.
Важно уметь создавать связанные визуализации, настраивать фильтры, выстраивать логику данных в самом инструменте, обеспечивать производительность дашбордов.
На бесплатном курсе «Визуализация данных и продвинутое Tableau» вы научитесь оформлять графики, создавать сложную верстку, а также использовать сложный функционал это программы.
- Основы Python / R
Это опционально, но очень желательно. Так вы сможете справляться с задачами, которые сложно или невозможно решить с помощью SQL: сложная статистика, прогнозное моделирование, работа с API для дополнения данных.
Понимание бизнеса
- Умение задавать правильные вопросы и слушать
Бизнес часто формулирует симптомы («продажи падают»), а не причину. Задача эксперта — докопаться до сути через вопросы:
- Падают в сравнении с каким периодом?
- Во всех регионах или в конкретном?
- Падает количество заказов или средний чек?
- Какое событие (релиз, рекламная кампания, изменение цены) предшествовало изменению?
Это контекст, который определит, к каким таблицам в DWH вы пойдете и какие JOIN’ы сделаете.
Но важно не просто скинуть таблицу с цифрами, а рассказать историю на языке бизнеса. «Выручка выросла на 10%» — это факт. «Выручка выросла на 10% за счет старой аудитории, которая стала покупать чаще после запуска программы лояльности, а траты на привлечение новых клиентов при этом не изменились» — это инсайт.
Заключение
Data Warehouse — это фундамент data-driven культуры в компании. Оно решает ключевую проблему: превращает разрозненные операционные данные в единый, надежный и исторически полный источник для анализа.
Для аналитика переход на работу с DWH означает качественный сдвиг в профессии. Вместо ручного сбора и очистки информации основное время теперь уделяется анализу, поиску причин и формулировке гипотез.
Внедрение и грамотное использование таких хранилищ — это не просто IT-проект, а инвестиция в скорость и качество управленческих решений, что в долгосрочной перспективе становится ключевым конкурентным преимуществом.
