Библиотека Seaborn: создаем графики для анализа данных в Python
Визуализация данных за 5 минут: работа с библиотекой Seaborn в Python
Визуализация — один из самых быстрых способов понять, что на самом деле происходит в данных. Диаграммы и графики помогают увидеть тренды, выбросы, зависимости и ошибки еще до сложного анализа и моделирования. Однако для новичков построение даже простой наглядной схемы часто кажется сложнее, чем на самом деле.
Содержание
- Что такое Seaborn и для чего она нужна
- Быстрый старт: установка Seaborn и первая визуализация
- 7 основных типов графиков в Seaborn с примерами кода
- Работа со стилями и темами в Seaborn
- Пять встроенных стилей фона и сетки
- Контекст: размеры под формат подачи
- Цветовые палитры по типам данных
- Seaborn vs Matplotlib: в чем ключевая разница
- Заключение
Seaborn — библиотека Python, которая решает эту проблему. Она позволяет создавать аккуратные и информативные графики буквально в несколько строк кода и отлично подходит для первичного анализа данных. В статье разберемся, как начать работать с этой библиотекой, понять ее логику и построить первую визуализацию для реальной задачи, даже если вы только начинаете путь в аналитике или разработке.
Чтобы такие инструменты, как Seaborn, стали вашими надежными помощниками, нужна уверенная база. Умение писать код, понимать ошибки и структурировать решения — это основа, которая позволит не просто следовать инструкциям, а самостоятельно создавать скрипты для анализа, парсинга данных или автоматизации отчетов. Начните с бесплатного курса «Основы Python». Он подойдет всем, кто хочет освоить программирование с нуля. Вам потребуется только уверенное пользование компьютером.
Что такое Seaborn и для чего она нужна
Представьте, что анализируете данные о продажах. Нужно понять, зависит ли средний чек от дня недели. В коде это звучит так: «Построй мне столбчатую диаграмму, где по оси X — дни, по оси Y — средняя сумма покупки, а также рассчитай и покажи доверительные интервалы».
Если вы пользуетесь только библиотекой Matplotlib, то потребуются десятки строк кода, тонкая ручная настройка. Вы больше думаете о том, как нарисовать, а не о том, что увидеть в данных. А ведь можно написать одну строку кода и получить готовый, статистически полноценный график: рассчитанное среднее, автоматически построенные доверительные интервалы, приятную цветовую палитру и аккуратное оформление.
Seaborn — это высокоуровневая библиотека Python для создания информативных и красивых статистических графиков. Она построена на основе Matplotlib, хорошо работает с таблицами pandas и понимает структуру данных: числовые признаки, категории и группы. Благодаря этому обычно достаточно указать, какие столбцы использовать, — библиотека сама позаботится о визуализации.
Seaborn особенно полезен на этапе исследовательского анализа данных (EDA), когда важно быстро:
- посмотреть распределение значений;
- сравнить несколько групп между собой;
- найти зависимости между признаками;
- заметить выбросы и аномалии.
Этот инструмент помогает за минуту проверить гипотезу, увидеть аномалию или показать результат коллеге — без многочасовой возни с настройкой внешнего вида
Быстрый старт: установка Seaborn и первая визуализация
В этом разделе вы узнаете, как установить эту библиотеку, подключить ее в Python и использовать встроенные датасеты для обучения и экспериментов. Это позволит сосредоточиться на практике, не отвлекаясь на подготовку данных.
Как установить Seaborn
Библиотека устанавливается как обычный Python-пакет и не требует сложной настройки. Главное условие — у вас уже должен быть установлен Python. Рекомендуется версия 3.8 или выше, так как именно эти версии активно поддерживаются сообществом и всеми ключевыми библиотеками для анализа данных.
Установка через pip
Самый простой и распространенный способ — установка через pip. В терминале или командной строке выполните:

Если вы работаете в окружении, где используется несколько версий Python, может понадобиться явное указание версии:

Установка через conda
Если вы используете Anaconda или Miniconda, Seaborn можно установить через conda:

Этот вариант удобен, особенно если вы используете Anaconda как основной дистрибутив, так как conda автоматически подтянет совместимые версии зависимостей из своих репозиториев.
Проверка установки
После установки убедимся, что библиотека доступна. Запустите Python или Jupyter Notebook и выполните:

Если ошибок нет — Seaborn установлен корректно и готов к работе. При установке через pip или conda автоматически подтягиваются все необходимые зависимости, включая:
- matplotlib — для отрисовки графиков;
- pandas — для работы с табличными данными;
- numpy — для вычислений.
Импорт библиотек и настройка
Для начала нам потребуется минимальный набор, который используется в большинстве аналитических задач.

Seaborn отвечает за построение визуализаций, а Matplotlib используется для отображения и тонкой настройки результата. Даже если вы напрямую не вызываете функции Matplotlib, она работает под капотом Seaborn.
Базовая настройка стиля
Одно из преимуществ этой библиотеки — готовые стили оформления. Достаточно одной строки, чтобы все визуализации выглядели аккуратно и читаемо.

Эта команда:
- задает приятную цветовую палитру;
- улучшает читаемость подписей и осей;
- делает внешний вид подходящим для анализа и отчетов.
Чаще всего этого достаточно для старта. Если вы работаете в Jupyter Notebook, визуализации будут отображаться автоматически после выполнения ячейки.
Минимальный шаблон для работы
В реальных проектах код часто начинается с одного и того же шаблона. Его удобно сохранить и использовать в будущем:

На этом этапе все готово к построению первого графика. Далее воспользуемся встроенными датасетами Seaborn, чтобы не тратить время на подготовку данных и сразу перейти к анализу.
Встроенные датасеты
Чтобы начать работу, не обязательно сразу искать реальные данные или загружать файлы. В библиотеку уже встроено несколько готовых датасетов, которые удобно использовать для обучения и экспериментов.
Эти наборы данных небольшие, понятные по структуре и хорошо подходят для первичного анализа. Полный список встроенных датасетов и их описание лучше смотреть в официальной документации Seaborn. Для примера, среди них вы можете встретить:
- tips — данные о чаевых в ресторане;
- titanic — информация о пассажирах «Титаника»;
- penguins — характеристики пингвинов;
- iris — классический датасет для анализа признаков.
Загрузим один из самых популярных наборов — tips:

В результате вы получите таблицу pandas, с которой можно работать как с обычным DataFrame: фильтровать данные, выбирать столбцы и передавать их в Seaborn для анализа.
Встроенные датасеты:
- не требуют ручной загрузки файлов;
- имеют чистую и понятную структуру;
- позволяют быстро перейти от данных к визуализации.
Именно поэтому их часто используют для знакомства с возможностями библиотеки и первых шагов в аналитике.
7 основных типов графиков в Seaborn с примерами кода
Seaborn умеет строить множество визуализаций, но для старта не нужно знать их все. Важно понять, какой график ответит на ваш вопрос о данных. Мы разделили семь ключевых типов на три группы:
- Основные — три самых часто используемых графика: scatterplot, histplot и boxplot. Они закрывают 80% задач первичного анализа и будут разобраны подробно с объяснением.
- Дополнительные — lineplot и barplot, которые полезны для конкретных случаев, например, для трендов или сравнения категорий.
- Продвинутые — heatmap и pairplot. Они дают быстрый и широкий обзор данных и помогают находить скрытые зависимости, используя минимум кода.
Диаграмма рассеяния (scatterplot)
Назначение: изучить взаимосвязь между двумя числовыми переменными. Это первый инструмент, если хотите проверить, как изменение одной величины отражается на другой. Например, как сумма счета влияет на размер чаевых.
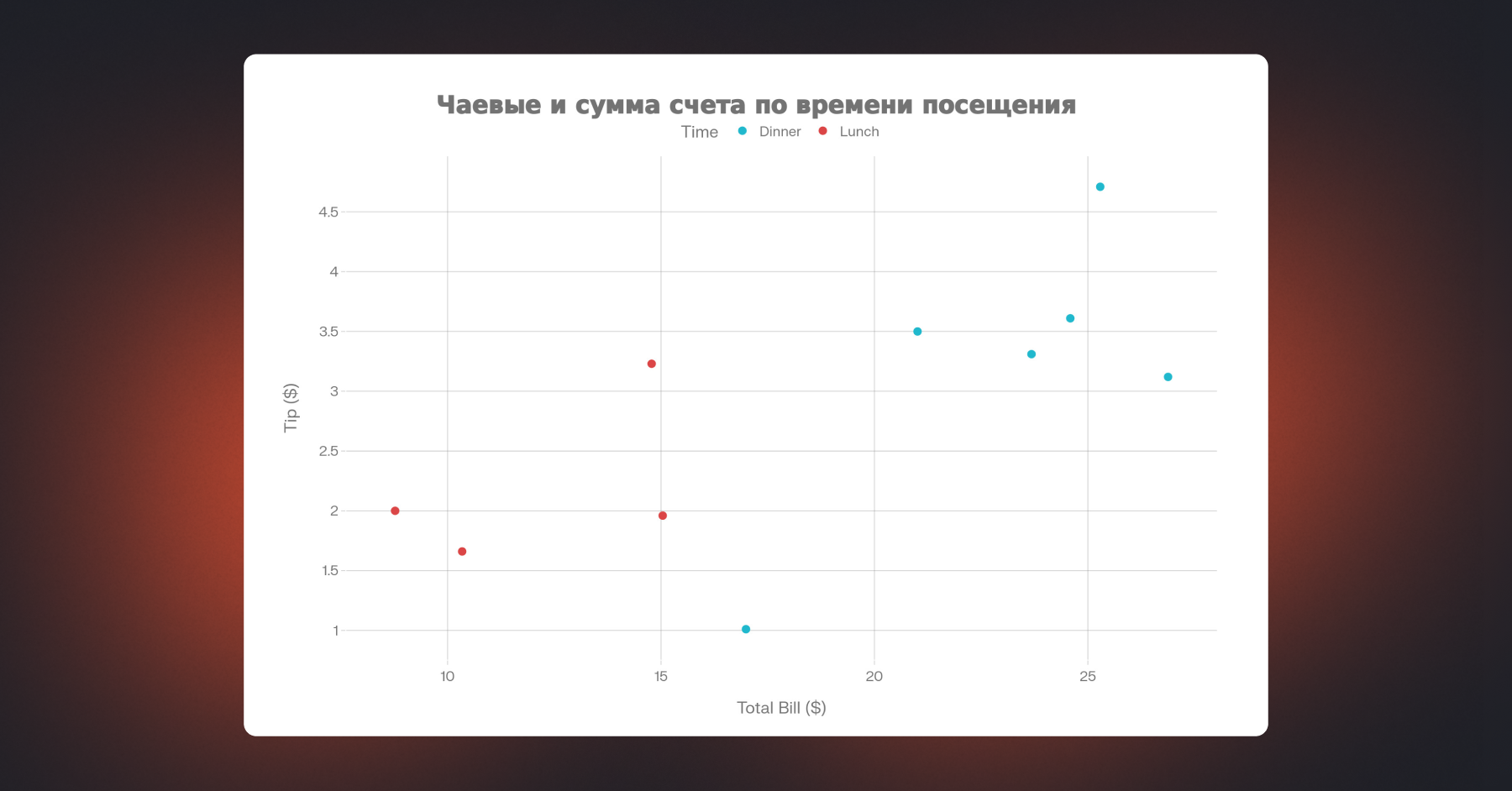
График показывает облако точек: чем выше сумма счета, тем больше чаевые. Видна положительная линейная тенденция.

Теперь точки окрашены по времени дня. Можно заметить, что вечерние счета (Dinner) в среднем выше и чаевые на них больше. Одна визуализация показывает и общую тенденцию, и различия между группами.
Гистограмма и плотность распределения (histplot, kdeplot)
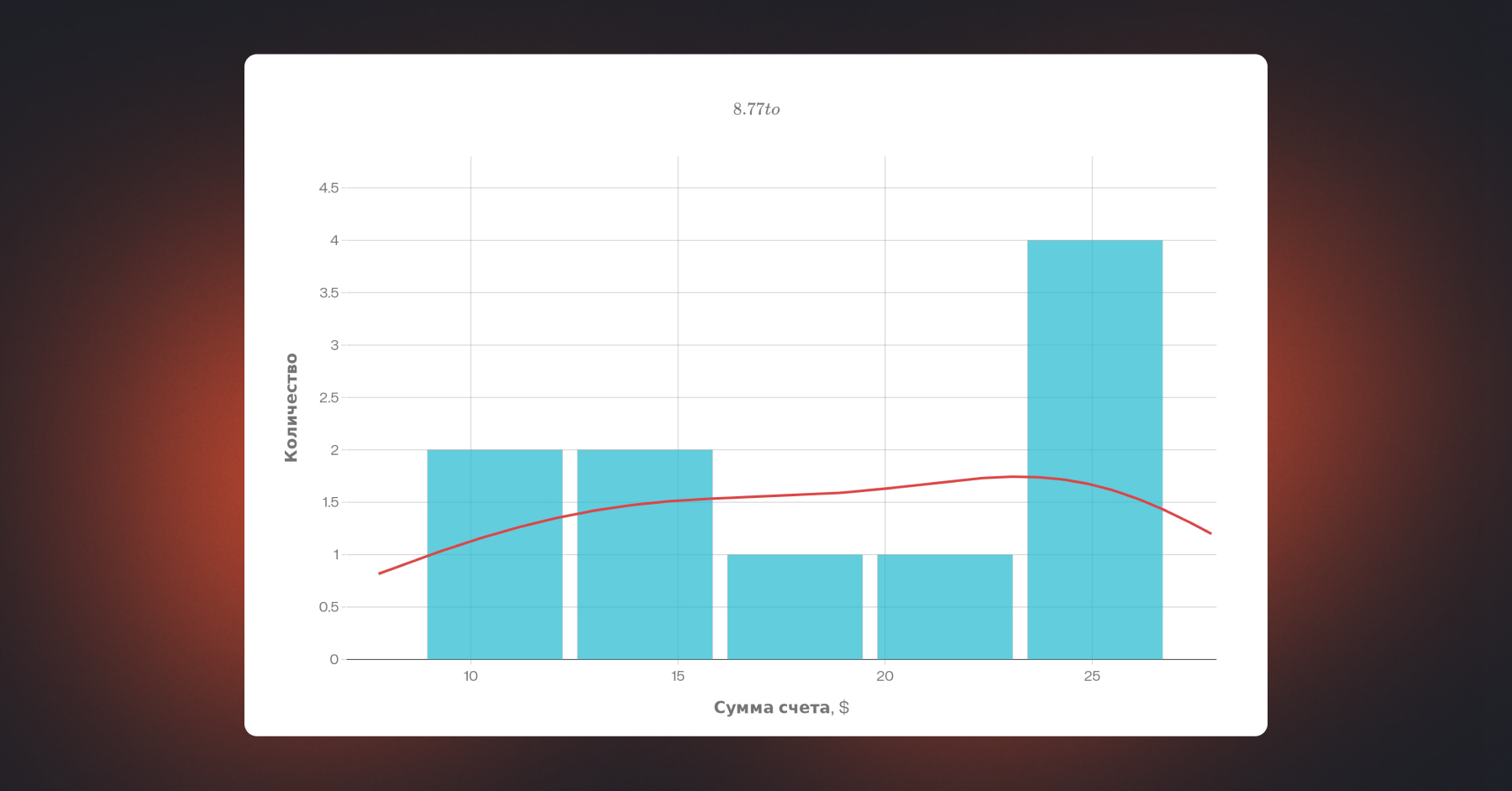
Назначение: показать, как распределены значения числовой переменной. Гистограмма показывает частоту, а кривая плотности (KDE) сглаживает распределение и помогает увидеть общую форму.
Допустим, мы хотим понять, какие чеки в ресторане встречаются чаще всего — маленькие, средние или большие.

Что мы видим? Мы получаем столбчатую диаграмму (гистограмму), где:
- По оси X: Сумма счета, разбитая на интервалы (корзины).
- По оси Y: Количество счетов, попавших в каждый интервал.
- Синяя кривая (KDE): Сглаженная версия гистограммы.
Распределение скошено вправо (правосторонняя асимметрия). Большинство счетов лежит в диапазоне 10–20$, редкие значения достигают 40–50$.

- element=’step’ делает гистограмму контурной для наглядного сравнения.
- stat=’density’ показывает относительные частоты, а не абсолютные значения.
- common_norm=False позволяет сравнивать формы распределений независимо.
Распределения курящих и некурящих клиентов похожи, большинство чеков также лежит в районе 10-20$. Уже можно сделать вывод, что привычка курить не сильно влияет на размер чека. За несколько секунд мы оценили форму данных, нашли типичный диапазон и проверили гипотезу о различии между группами.
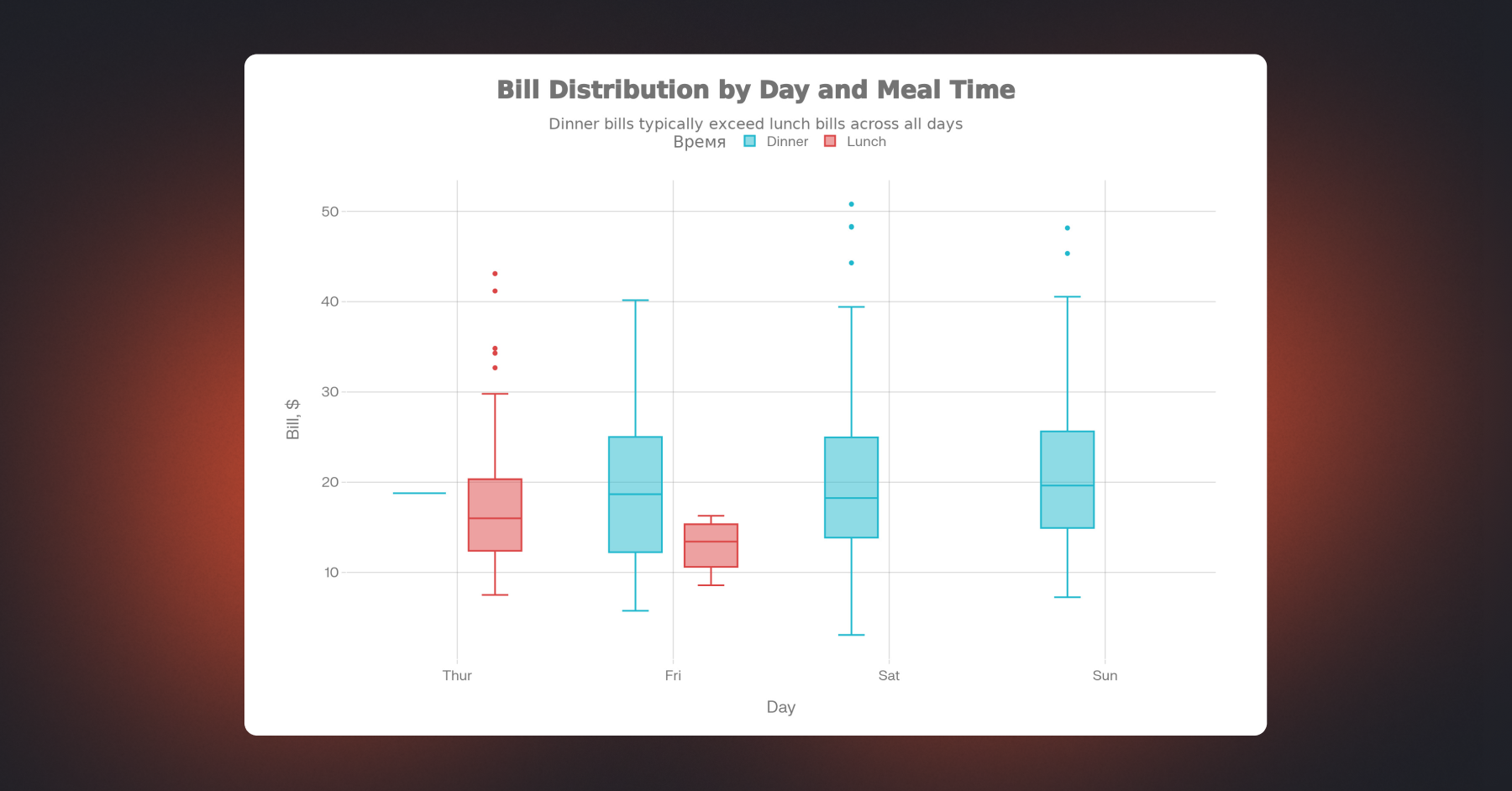
Ящик с усами (boxplot)
Назначение: сравнить распределение числовой переменной по разным группам. Это главный инструмент, когда нужно ответить на вопросы типа: «В какой день недели средний чек больше?», «Различается ли возраст клиентов в зависимости от пола?».
Допустим, владелец ресторана хочет понять, в какие дни чеки в среднем выше.

Перед нами несколько «ящиков» (box), по одному для каждого дня.
Ключ к интерпретации ящика:
- Центральная линия в ящике — это медиана (среднее значение). 50% данных лежат ниже этой линии, 50% — выше.
- Границы ящика (Q1 и Q3) показывают диапазон, в который попадает средние 50% данных.
- «Усы» (whiskers) — линии, идущие от ящика. Они обычно показывают диапазон типичных данных, за вычетом выбросов. Длина «усов» обычно равна 1.5 * (Q3 — Q1).
- Точки за пределами усов — это выбросы (outliers), аномально высокие или низкие значения.
Возможная интерпретация нашего графика:
- Сравнение медиан
Самый высокий средний чек — в субботу (Sat), а самый низкий — в воскресенье (Sun).
- Разброс данных
В пятницу (Fri) разброс сумм самый маленький (ящик короткий), а в субботу (Sat) — самый большой, что говорит о большем разнообразии чеков.
- Выбросы
Мы видим несколько выбросов (например, очень высокие счета в четверг и субботу). Это потенциально важные аномалии для анализа.

Теперь видно, как меняется распределение внутри дня: в пятницу — только обеды, в субботу — только ужины, а в воскресенье ужины «тяжелее» обедов.
Один boxplot показывает медиану, разброс, выбросы и сравнение групп одновременно — гораздо нагляднее, чем таблица.
Линейный график (lineplot)
Назначение: показать тренд или изменение одной величины относительно другой, чаще всего — во времени. Идеален для отслеживания динамики: продажи по месяцам, температура по дням, количество пользователей по неделям.
Посмотрим, как менялось среднее количество пассажиров авиакомпании по месяцам (с доверительными интервалами).
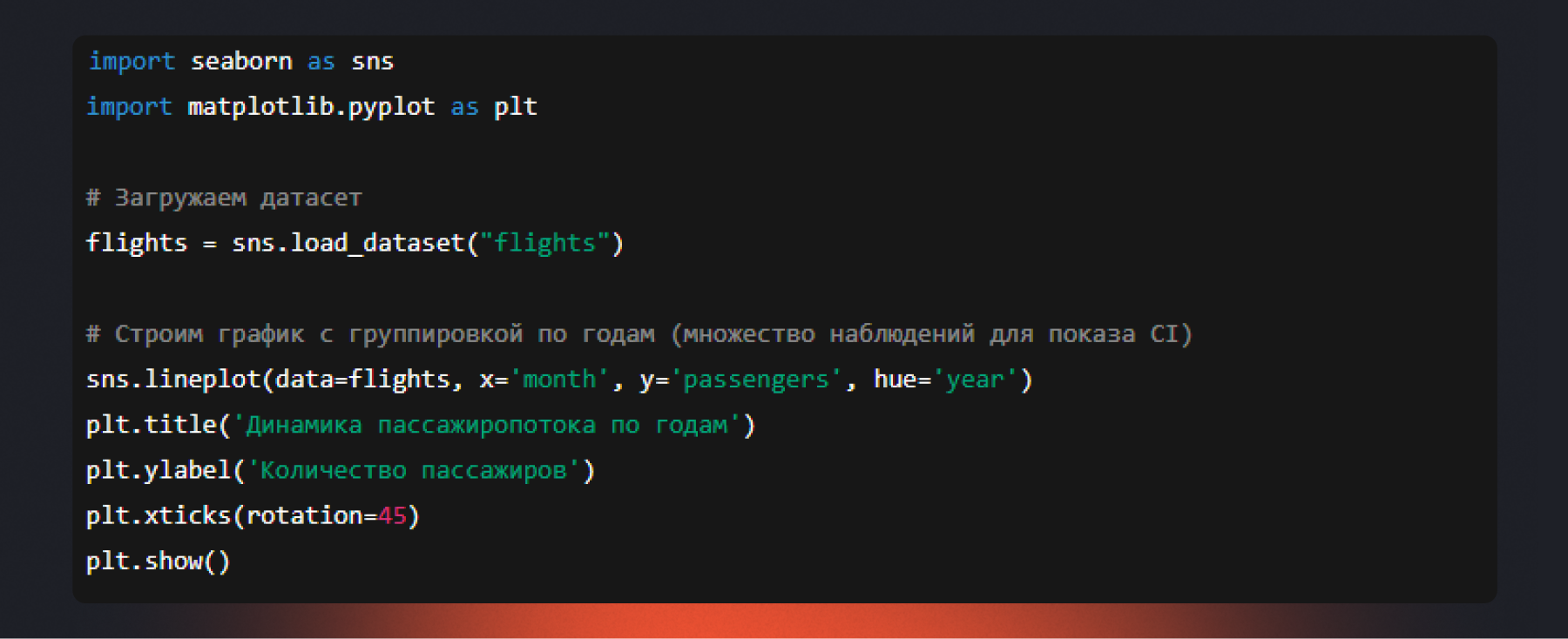
lineplot по умолчанию показывает доверительный интервал вокруг линии (затененная область), если для каждого значения X есть несколько наблюдений. В примере несколько линий по годам дают разброс для расчета CI — это показывает надежность тренда.
Столбчатая диаграмма (barplot)
В Seaborn barplot — это не просто гистограмма. По умолчанию она показывает среднее значение числовой переменной для каждой категории, а «усы» на столбцах отображают доверительный интервал (погрешность оценки).
К примеру, сравним средний размер чаевых в разные дни недели.
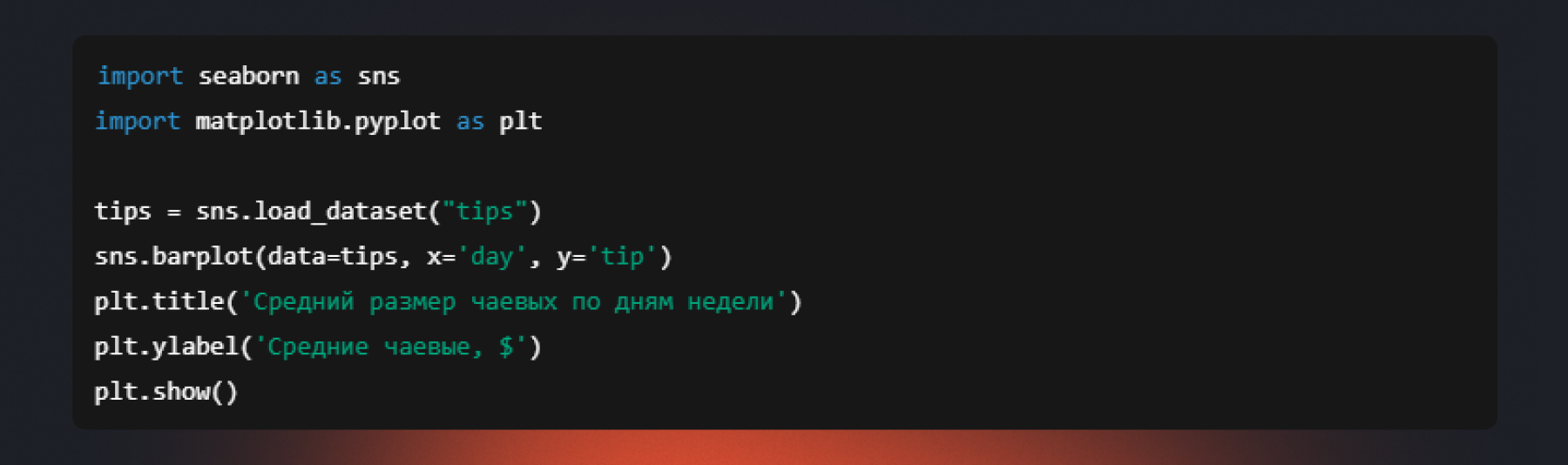
Высота столбца — это среднее, «усы» показывают разброс данных. Короткие усы = точная оценка, длинные усы = данные сильно варьируются.
Тепловая карта (heatmap)
Назначение: визуализировать матрицу чисел в виде цветовой карты. Чаще всего используется для матрицы корреляций или сводных таблиц.
Допустим, нужно быстро оценить взаимосвязь всех числовых признаков в датасете.
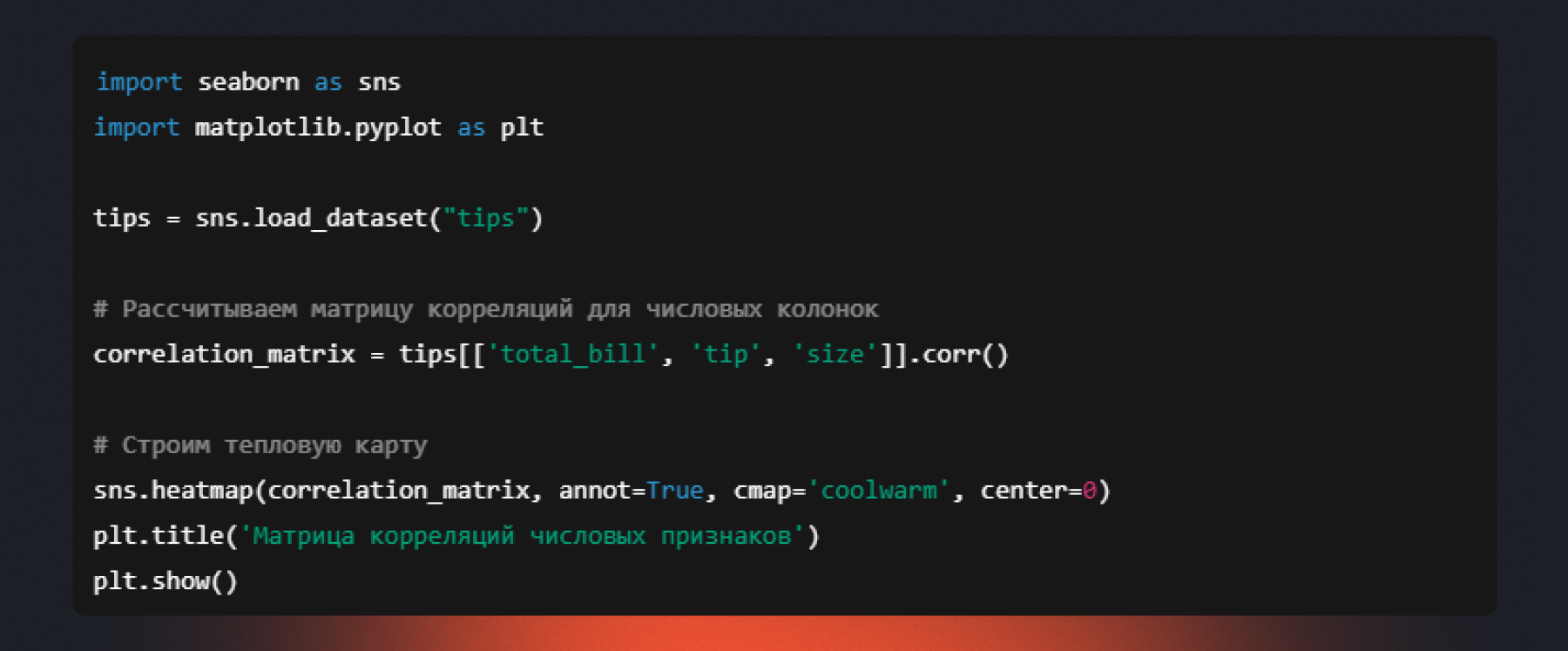
Ячейки окрашены от синего (обратная корреляция) через белый (ноль) к красному (прямая корреляция). Числа (annot=True) показывают силу связи. Видно, что total_bill и tip сильно связаны (~0.68).
Парные отношения (pairplot)
Назначение: «швейцарский нож» для первого знакомства с датасетом. Строит матрицу из диаграмм рассеяния (scatterplot) и плотностей распределения (KDE) для всех числовых столбцов, позволяя одним взглядом оценить распределения и взаимосвязи.
Например, исследуем знаменитый датасет iris с характеристиками цветков.
Что вы увидите: на диагонали — распределения признаков для каждого вида. Вне диагонали — диаграммы рассеяния, показывающие, как признаки соотносятся друг с другом, и насколько хорошо разные виды (цвета) разделяются в пространстве этих признаков. Это мощнейший инструмент для формирования первых гипотез.
Работа со стилями и темами в Seaborn
Главное преимущество этой библиотеки — готовые профессиональные стили, которые превращают сырые графики в презентабельные визуализации за 1-2 команды. Вместо ручной настройки Matplotlib вы управляете стилем, размерами и цветами декларативно.
Рекомендуемый API в Seaborn 0.13+ — функция sns.set_theme(). Она объединяет управление стилем, контекстом и палитрой.
Без параметров sns.set_theme() применяет оптимальные настройки по умолчанию:
- Стиль: «darkgrid» (светло-серый фон с темной сеткой)
- Контекст: «notebook» (сбалансированные размеры для Jupyter)
- Палитра: «light» (светлые тона; для насыщенных цветов используйте «deep»)
Пять встроенных стилей фона и сетки
Стиль задается параметром style в sns.set_theme():
- «darkgrid» (по умолчанию) — светло-серый фон с темной сеткой. Идеален для анализа данных.
- «whitegrid» — белый фон с темной сеткой. Удобен для точных измерений.
- «dark» — темно-серый фон без сетки. Минимализм для отчетов.
- «white» — чистый белый фон без сетки. Универсальный выбор.
- «ticks» — белый фон с осями и тонкой рамкой. Технический минимализм.
Контекст: размеры под формат подачи
Параметр context масштабирует шрифты, линии, метки:
- «paper» — компактный для статей и PDF.
- «notebook» (по умолчанию) — оптимальный для Jupyter.
- «talk» — крупный для презентаций и слайдов.
- «poster» — максимальный для стендов и постеров.
Цветовые палитры по типам данных
Палитры задаются параметром palette. Seaborn предлагает три категории:
Качественные (для категорий):
- «deep», «muted», «pastel», «bright», «dark», «colorblind».
- Пример: «deep» отлично работает для 6-10 категорий.
Последовательные (для монотонных градиентов):
- «viridis», «plasma», «inferno», «magma», «Blues», «YlOrRd».
- Показывают интенсивность от минимума к максимуму.
Дивергентные (для отклонений от центра):
- «rocket», «mako», «flare», «crest», «vlag», «icefire», «coolwarm», «RdBu_r».
- Подчеркивают значения выше или ниже среднего.
Seaborn vs Matplotlib: в чем ключевая разница
Представьте, что вы хотите собрать мебель. Matplotlib — это мастерская с инструментами: вы сможете создать уникальный предмет, но потратите на это часы. Seaborn — это набор готовых модулей из IKEA: вы быстро соберете стандартную, но стильную и функциональную вещь по инструкции.
Matplotlib — библиотека среднего уровня с полным контролем над элементами графика (линии, оси, подписи). Вы рисуете все с нуля, что требует много кода даже для простых визуализаций. Это мощно, но медленно для рутинного анализа.
Seaborn — это высокоуровневая надстройка над Matplotlib, созданная для статистической визуализации. Вы описываете, что хотите увидеть в своих данных (связь, распределение, сравнение групп), а Seaborn автоматически строит готовый график с опциональным расчетом статистики, красивой палитрой и оформлением.
Заключение
Теперь у вас есть ключ к быстрой визуализации. Установили, импортировали, вызвали sns.set_theme() — и Seaborn готов превратить ваши данные в понятные графики парой строк.
Запомните главное: используйте scatterplot для связей, histplot для распределений, boxplot для сравнений. Не бойтесь экспериментировать с темами и палитрами. А если понадобится кастомизация — подключайте Matplotlib.
